Spark-BlockManager
简单说明
BlockManager是管理整个Spark运行时数据的读写,包含数据存储本身,在数据存储的基础之上进行数据读写。由于Spark是分布式的,所有BlockManager也是分布式的,BlockManager本身相对而言是一个比较大的模块,Spark中有非常多的模块:调度模块、资源管理模块等等。BlockManager是另外一个非常重要的模块,BlockManager本身源码量非常大。本篇从BlockManager原理流程对BlockManager做深刻的理解。在Shuffle读写数据的时候, 我们需要读写BlockManager。因此BlockManager是至关重要的内容。
BlockManager是整个Spark底层负责数据存储与管理的一个组件,Driver和Executor的所有数据都由对应的BlockManager进行管理。
相关组件
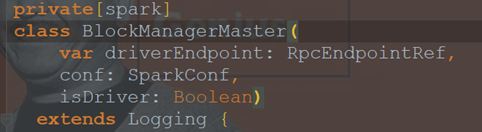
BlockManagerMaster
Driver上有BlockManagerMaster,负责对各个节点(Executor)上的BlockManager内部管理的数据的元数据进行维护,比如block的增删改等操作,都会在这里维护好元数据的变更。
BlockManagerMaster与BlockManager的关系非常像NameNode与DataNode的关系,BlockManagerMaster中保存中BlockManager内部管理数据的元数据,进行维护,当BlockManager进行Block增删改等操作时,都会在BlockManagerMaster中进行元数据的变更,这与NameNode维护DataNode的元数据信息,DataNode中数据发生变化时NameNode中的元数据信息也会相应变化是一致的。
- 4,BlockManagerMaster tell,如果message为false,抛异常。
message为 BlockManagerMasterEndpoint中的receiveAndReply方法发送过去的


BlockManager
每个节点(Executor)都有一个BlockManager,(每启动一个CoarseGrainedExecutorBackend都会实例化一个BlockManager),每个BlockManager创建之后,第一件事即是去向BlockManagerMaster进行注册,实质上是:Executor中的BlockManager在启动的时候注册给了Driver上的BlockManagerMasterEndpoint。
- 1,在Executor中创建BlockManager。
当Executor实例化的时候会通过env.blockManager.initialize(conf.getAppId)来实例化Executor上的BlockManager并且创建BlockManagerSlaveEndpoint这个消息循环体来接受Driver中的BlockManagerMasterEndpoint发过来的指令,例如:删除Block。(Executor中)

BlockManager中有三个非常重要的组件:
MemoryStore
负责对内存数据进行读写。
DiskStore
负责对磁盘数据进行读写。
BlockTransferService
负责建立BlockManager到远程其他节点的BlockManager的连接,负责对远程其他节点的BlockManager的数据进行读写;例如:
使用BlockManager进行写操作时,比如说,RDD运行过程中的一些中间数据,或者我们手动指定了persist(),会优先将数据写入内存中,如果内存大小不够,会使用自己的算法,将内存中的部分数据写入磁盘;此外,如果persist()指定了要replica,那么会使用BlockTransferService将数据replicate一份到其他节点的BlockManager上去。
使用BlockManager进行读操作时,比如说,shuffleRead操作,如果能从本地读取,就利用DiskStore或者MemoryStore从本地读取数据,但是本地没有数据的话,那么会用BlockTransferService与有数据的BlockManager建立连接,然后用BlockTransferService从远程BlockManager读取数据。
BlockManagerMasterEndpoint
传入BlockManagerMaster类(Driver)里的一个消息循环体,会负责通过远程消息通信的方式去管理所有节点的BlockMaster。
- 3,BlockManagerMaster接收到Executor上的注册信息并进行处理。
(BlockManagerMasterEndpoint中的receiveAndReply方法)

BlockManagerSlaveEndpoint
BlockManager上的消息循环体。(BlockManager里面的一个属性)

Executor上的BlockManager创建BlockManagerSlaveEndpoint这个消息循环体来接受Driver中的BlockManagerMasterEndpoint发过来的指令。
- 2,BlockManager向BlockManagerMaster注册
当BlockManagerSlaveEndpoint实例化后,Executor上的BlockManager需要向Driver上的BlockManagerMasterEndpoint注册:
(BlockManager中的initialize(appId: String)方法中)

BlockManagerInfo
每个BlockManager创建之后,第一件事即是去向BlockManagerMaster进行注册,此时BlockManagerMaster会为其创建对应的BlockManagerInfo来进行元数据管理。
BlockStatus
只要使用BlockManager执行了数据增删改的操作,那么必须将Block的BlockStatus上报到BlockManagerMaster,在BlockManagerMaster上会对指定BlockManager的BlockManagerInfo内部的BlockStatus进行增删改操作,从而达到元数据的维护功能。
|
// Mapping from block id to its status. private val _blocks = new JHashMap[BlockId, BlockStatus] |
MapOutPutTrackerMaster
在Application启动的时候,会在SparkEnv中注册BlockManager和MapOutPutTracker。
MapOutPutTrackerMaster负责跟踪所有的Mapper输出的。
当执行第二个 Stage 时,第二个 Stage 会向 Driver 中的 MapOutputTrackerMasterEndpoint 发消息请求上一个 Stage 中相应的输出,此時 MapOutputTrackerMaster 会把上一個 Stage 的输出数据的元数据信息发送给当前请求的 Stage。
DiskBlockManager
管理Logical Block与Disk上的Physical Block之间的映射关系并负责磁盘的文件的创建、读写等。
负责管理逻辑级别和物理级别的映射关系,根据BlockID映射一个文件。在目录spark.local.dir或者SPARK_LOCAL_DIRS中,Block文件进行hash生成。通过createLocalDirs 生成本地目录。
运行原理示意图

图片下载地址:https://www.processon.com/embed/5e96a0a0e401fd262e1a14d6
上述文字描述中标序号的红色加粗部分为BlockManager向BlockManagerMaster注册的过程。
Spark-BlockManager的更多相关文章
- Spark BlockManager的通信及内存占用分析(源码阅读九)
之前阅读也有总结过Block的RPC服务是通过NettyBlockRpcServer提供打开,即下载Block文件的功能.然后在启动jbo的时候由Driver上的BlockManagerMaster对 ...
- Spark BlockManager 概述
Application 启动的时候: 1. 会在 SparkEnv 中实例化 BlockManagerMaster 和 MapOutputTracker,其中 (a) BlockManagerMast ...
- Spark源码剖析 - SparkContext的初始化(八)_初始化管理器BlockManager
8.初始化管理器BlockManager 无论是Spark的初始化阶段还是任务提交.执行阶段,始终离不开存储体系.Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息.计算结 ...
- Spark 官方文档(4)——Configuration配置
Spark可以通过三种方式配置系统: 通过SparkConf对象, 或者Java系统属性配置Spark的应用参数 通过每个节点上的conf/spark-env.sh脚本为每台机器配置环境变量 通过lo ...
- Spark数据传输及ShuffleClient(源码阅读五)
我们都知道Spark的每个task运行在不同的服务器节点上,map输出的结果直接存储到map任务所在服务器的存储体系中,reduce任务有可能不在同一台机器上运行,所以需要远程将多个map任务的中间结 ...
- 【Spark学习】Apache Spark安全机制
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4135808.html 目录 W ...
- Spark配置参数详解
以下是整理的Spark中的一些配置参数,官方文档请参考Spark Configuration. Spark提供三个位置用来配置系统: Spark属性:控制大部分的应用程序参数,可以用SparkConf ...
- Spark记录-官网学习配置篇(一)
参考http://spark.apache.org/docs/latest/configuration.html Spark提供三个位置来配置系统: Spark属性控制大多数应用程序参数,可以使用Sp ...
- spark属性
应用属性 属性名 缺省值 意义 spark.app.name (none) The name of your application. This will appear in the UI and i ...
- Spark Configuration配置
Spark可以通过三种方式配置系统: 通过SparkConf对象, 或者Java系统属性配置Spark的应用参数 通过每个节点上的conf/spark-env.sh脚本为每台机器配置环境变量 通过lo ...
随机推荐
- 图解GC流程
GC流程是每一个Java开发人员都应该掌握的内容.你知道什么时候触发Minor GC?什么时候触发 Minor GC 的过程是怎么样的?Full GC 的过程又是怎么样的?这一切都要从「压死骆驼 ...
- ftp 无法显示远程文件夹
翻阅了网上前辈们的答案,都未能解决,所以就研究了一下 不需要防火墙的情况,关闭防火墙即可 下面使用的iptables防火墙验证的,其他的请自行验证 研究了好久,发现ftp使用端口波动很大,大概在300 ...
- H - 遥远的糖果 HihoCoder - 1478
给定一个N x M的01矩阵,其中1表示人,0表示糖.对于每一个位置,求出每个位置离糖的最短距离是多少. 矩阵中每个位置与它上下左右相邻的格子距离为1. Input 第一行包含两个整数,N和M. 以下 ...
- markdown 插入图片太大?怎么设定图片大小?
你一定在插入图片的时候,遇到图片太大,影响观感的问题. Markdown中,图片大小的设定方式有两种 第一种: 
采用dockerhub安装 docker run -p 3306:3306 --name mysql -v /mydata/mysql/log:/var/log/mysql -v /mydata/my ...
- Blocked Billboard II题解--模拟到崩溃的模拟
前言 比赛真的状态不好(腐了一小会),导致差点爆0. 这个题解真的是在非常非常专注下写出来的,要不然真的心态崩. 题目 题目描述 奶牛Bassie想要覆盖一大块广告牌,她在之前已经覆盖了一小部分广告牌 ...
- Mysql千万级记录表分表策略
目前,比较流行的分表为2倍扩容. 表A(id, name, age, sex) 基于自增id分表, 通过触发器先同步A到B, 程序通过mod 2操作数据,然后drop掉触发器,在 删除两个A表的偶数i ...
- BadMethodCallException : Call to undefined method App\Models\Article::setContainer()
如果你执行 php artisan db:seed 发生如下错误 说是模型中不存在 静态方法 setContainer()方法,那么你应该检查下你的DatabaseSeeder.php 文件 中的 r ...
- gcc/g++堆栈保护技术
最近学习内存分布,通过gdb调试发现一些问题,栈空间变量地址应该是从高往低分布的,但是调试发现地址虽然是从高往低分布,但是变量地址的顺序是乱的,请教同事他说可能是gcc/g++默认启用了堆栈保护, ...
- C语言冒泡排序法分析及代码实现
冒泡排序法: 所谓冒泡排序法,就是对一组数字进行从大到小或者从小到大排序的一种算法.具体方法是,相邻数值两两交换.从第一个数值开始,如果相邻两个数的排列顺序与我们的期望不同,则将两个数的位置进行交换( ...