大数据并行计算框架Spark
Spark2.1. http://dblab.xmu.edu.cn/blog/1689-2/
0+入门:Spark的安装和使用(Python版)
Spark2.1.0+入门:第一个Spark应用程序:WordCount(Python版)
http://dblab.xmu.edu.cn/blog/1692-2/#more-1692
应用:
启动
cd /usr/local/spark
./bin/pyspark
RDD
分布式对象集合,一个只读的分区记录集合。一种数据结构(相当于int、double等)
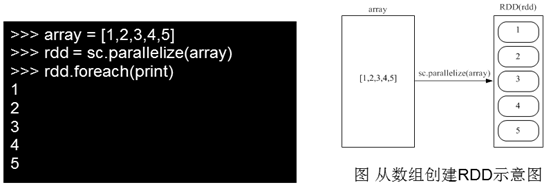
1.RDD创建
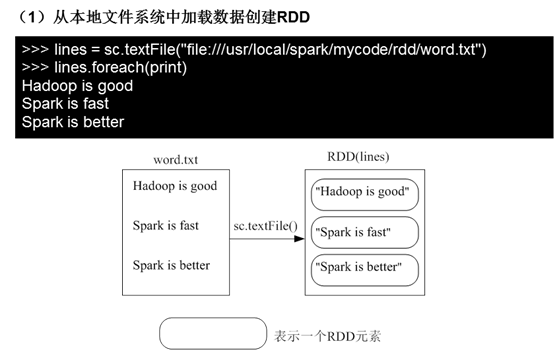
(1)从本地文件系统中加载数据创建RDD
(2)从分布式文件系统HDFS中加载数据

(3)从其他RDD创建。
parallelize:https://blog.csdn.net/wyqwilliam/article/details/84330408
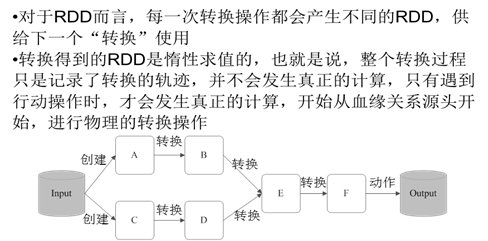
2.RDD操作
Spark API :https://www.csdn.net/gather_26/MtTaYg4sNDQ5MC1ibG9n.html
2.1转换操作

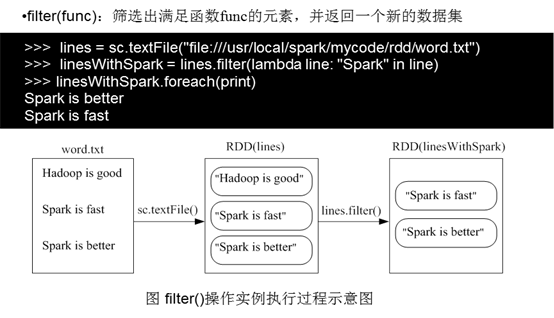
1)fileter(func)
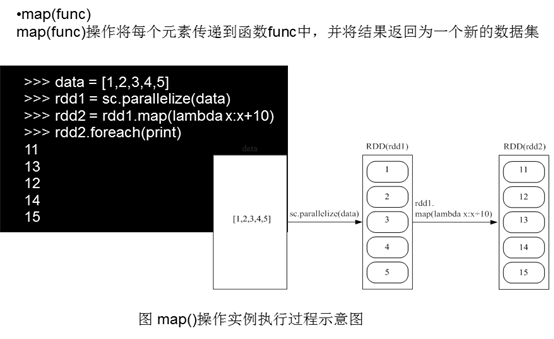
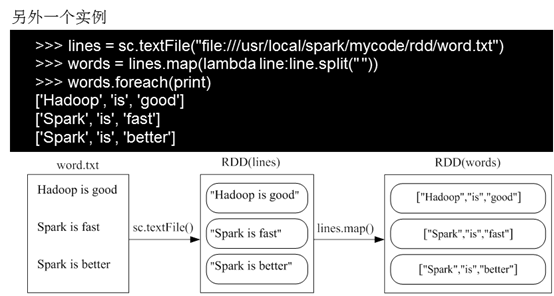
2)map(func)
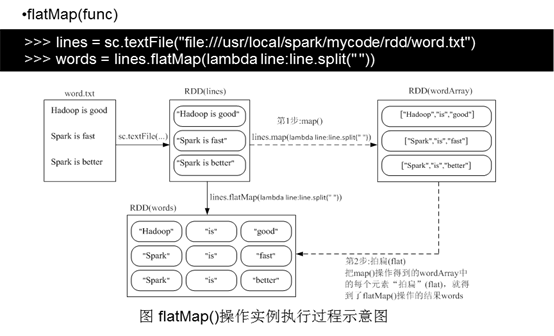
3)flatMap(func)
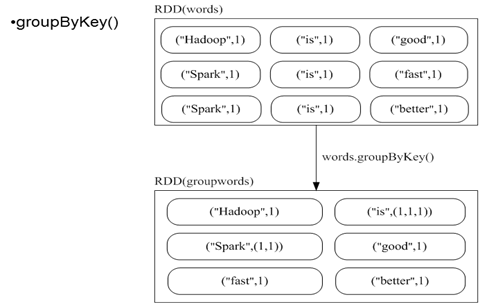
4)groupByKey()

5)reduceBykey(func)

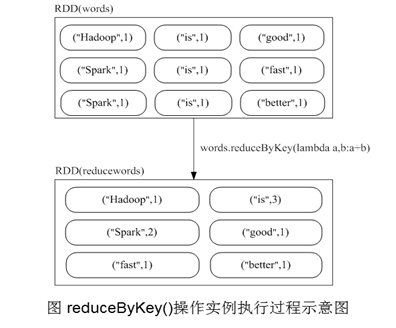
groupByKey也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作
reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义

6)keys()

7)values()

8)mapValues(func)

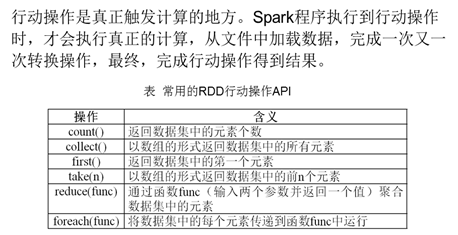
4.2行动操作




4.3惰性机制

持久化




分区


练习:
1给定一组键值对("spark",2),("hadoop",6),("hadoop",4),("spark",6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
2 有两个文件,file1.txt,file2.txt,字段含义如下orderid,userid,payment,productid。求top 5个payment值。
file1.txt
1,1768,50,155
2,1218, 600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27
file2.txt
100,4287,226,233
101,6562,489,124
102,1124,33,17
103,3267,159,179
104,4569,57,125
105,1438,37,116
大数据并行计算框架Spark的更多相关文章
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
http://www.csdn.net/article/2014-06-05/2820089 摘要:MapReduce在实时查询和迭代计算上仍有较大的不足,目前,Spark由于其可伸缩.基于内存计算等 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- 大数据篇:Spark
大数据篇:Spark Spark是什么 Spark是一个快速(基于内存),通用,可扩展的计算引擎,采用Scala语言编写.2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验 ...
- [转帖]大数据hadoop与spark的区别
大数据hadoop与spark的区别 https://www.cnblogs.com/adnb34g/p/9233906.html Posted on 2018-06-27 14:43 左手中倒影 阅 ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
随机推荐
- Selenium系列(二十) - PageObject模式的详细介绍
如果你还想从头学起Selenium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基础知识, ...
- Java读源码之ReentrantLock
前言 ReentrantLock 可重入锁,应该是除了 synchronized 关键字外用的最多的线程同步手段了,虽然JVM维护者疯狂优化 synchronized 使其已经拥有了很好的性能.但 R ...
- 十进制转化为非十进制C++代码
还是先为大家介绍一下原理吧. 假设余数为 r ,十进制数为 n :(拆分为整数 zs ,余数 ys) 对 zs:需要将 zs 除 r 取余数,直到商为 0 停止,将余数倒序排列即可. 对 ys:需要将 ...
- 从养孩子谈谈 IO 模型(一)
同步/异步.阻塞/非阻塞 说的是一回事儿吗? 同步/异步.阻塞/非阻塞 你能通俗易懂的讲清楚吗? Java 中的 BIO.NIO.AIO 你了解吗? Socket 编程你还会吗? Linux 操作系统 ...
- Netty:Channel
上一篇我们通过一个简单的Netty代码了解到了Netty中的核心组件,这一篇我们将围绕核心组件中的Channel来展开学习. Channel的简介 Channel代表着与网络套接字或者能够进行IO操作 ...
- Hadoop(五):HDFS的JAVA API基本操作
HDFS的JAVA API操作 HDFS在生产应用中主要是客户端的开发,其核心步骤是从HDFS提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件. 主 ...
- 机器学习4- 多元线性回归+Python实现
目录 1 多元线性回归 2 多元线性回归的Python实现 2.1 手动实现 2.1.1 导入必要模块 2.1.2 加载数据 2.1.3 计算系数 2.1.4 预测 2.2 使用 sklearn 1 ...
- python 函数--装饰器
一.装饰器 1.为什么要用装饰器? 装饰器的功能:在不修改原函数以及调用方式的情况下对原函数功能进行扩展. 二.开放和封闭原则 1.对扩展是开放的 2.对修改是封闭的 三.装饰器的固有结构 impor ...
- ThinkPHP3.2.3集成微信分享JS-SDK实践
先来看看微信分享效果:在没有集成微信分享js-sdk前是这样的:没有摘要,缩略图任意抓取正文图片 在集成微信分享js-sdk后是这样的:标题,摘要,缩略图自定义 一.下载微信SDK开发包下载地址:ht ...
- Python设计模式(3)-工厂方法模式
# coding=utf-8 #定义一个用于创建对象的接口,让子类决定实例化哪一个类 class DbManager: def __init__(self): pass def operate_db( ...