[转帖]大数据hadoop与spark的区别
大数据hadoop与spark的区别
https://www.cnblogs.com/adnb34g/p/9233906.html
学习hadoop已经有很长一段时间了,好像是二三月份的时候朋友给了一个国产Hadoop发行版下载地址,因为还是在学习阶段就下载了一个三节点的学习版玩一下。在研究、学习hadoop的朋友可以去找一下看看(发行版 大快DKhadoop,去大快的网站上应该可以下载到的。)
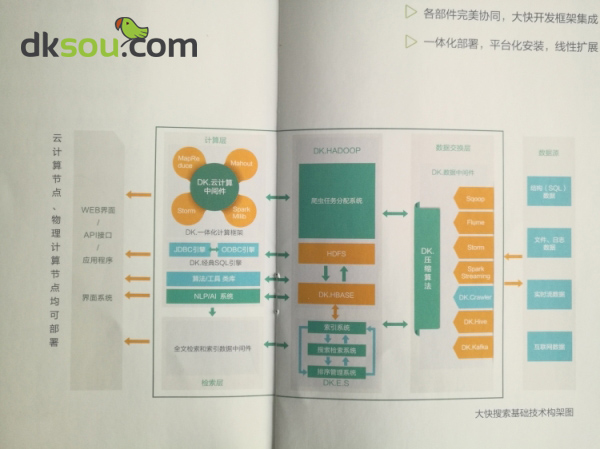
在学习hadoop的时候查询一些资料的时候经常会看到有比较hadoop和spark的,对于初学者来说难免会有点搞不清楚这二者到底有什么大的区别。我记得刚开始接触大数据这方面内容的时候,也就这个问题查阅了一些资料,在《FreeRCH大数据一体化开发框架》的这篇说明文档中有就Hadoop和spark的区别进行了简单的说明,但我觉得解释的也不是特别详细。我把个人认为解释的比较好的一个观点分享给大家:
它主要是从四个方面对Hadoop和spark进行了对比分析:
1、目的:首先需要明确一点,hadoophe spark 这二者都是大数据框架,即便如此二者各自存在的目的是不同的。Hadoop是一个分布式的数据基础设施,它是将庞大的数据集分派到由若干台计算机组成的集群中的多个节点进行存储。Spark是一个专门用来对那些分布式存储的大数据进行处理的工具,spark本身并不会进行分布式数据的存储。
2、两者的部署:Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。所以使用Hadoop则可以抛开spark,而直接使用Hadoop自身的mapreduce完成数据的处理。Spark是不提供文件管理系统的,但也不是只能依附在Hadoop上,它同样可以选择其他的基于云的数据系统平台,但spark默认的一般选择的还是hadoop。
3、数据处理速度:Spark,拥有Hadoop、 MapReduce所具有能更好地适用于数据挖掘与机器学习等需要迭代的的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,
Spark 是一种与hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
4、数据安全恢复:Hadoop每次处理的后的数据是写入到磁盘上,所以其天生就能很有弹性的对系统错误进行处理;spark的数据对象存储在分布于数据集群中的叫做弹性分布式数据集中,这些数据对象既可以放在内存,也可以放在磁盘,所以spark同样可以完成数据的安全恢复。
[转帖]大数据hadoop与spark的区别的更多相关文章
- 大数据hadoop与spark的区别
学习hadoop已经有很长一段时间了,好像是二三月份的时候朋友给了一个国产Hadoop发行版下载地址,因为还是在学习阶段就下载了一个三节点的学习版玩一下.在研究.学习hadoop的朋友可以去找一下看看 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据 Hadoop,Spark和Storm
大数据(Big Data) 大数据,官方定义是指那些数据量特别大.数据类别特别复杂的数据集,这种数据集无法用传统的数据库进行存储,管理和处理.大数据的主要特点为数据量大(Volume),数据类别复 ...
- 大数据Hadoop与Spark学习经验谈
昨晚听了下Hulu大数据基础架构组负责人–董西成的关于大数据学习方法的直播,挺有收获的,下面截取一些PPT的关键内容,希望对正在学习大数据的人有帮助. 现状是目前存在的问题,比如找百度.查书这种学习方 ...
- 大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
http://www.csdn.net/article/2014-06-05/2820089 摘要:MapReduce在实时查询和迭代计算上仍有较大的不足,目前,Spark由于其可伸缩.基于内存计算等 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 大数据hadoop面试题2018年最新版(美团)
还在用着以前的大数据Hadoop面试题去美团面试吗?互联网发展迅速的今天,如果不及时更新自己的技术库那如何才能在众多的竞争者中脱颖而出呢? 奉行着"吃喝玩乐全都有"和"美 ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- 大数据篇:Spark
大数据篇:Spark Spark是什么 Spark是一个快速(基于内存),通用,可扩展的计算引擎,采用Scala语言编写.2009年诞生于UC Berkeley(加州大学伯克利分校,CAL的AMP实验 ...
随机推荐
- AspNetCore3.0 和 JWT
添加NuGet引用 IdentityModel Microsoft.AspNetCore.Authorization.JwtBearer 在appsettings.json中添加JwtBearer配置 ...
- Java 死锁以及死锁的产生
public class DeadLockSample { public static void main(String[] args) { DeadLock d1 = new DeadLock(tr ...
- docker理论 Cgroup namespace 各种隔离
耦合 是指两个或两个以上的体系或者两种运动形式间通过相互作用而批次影响以至联合起来的现象. Nginx与apache 在同一台服务器运行都占用80端口,起冲突这是我们修改其中一个端口为8080 半解耦 ...
- 以前进行的程序安装创建了挂起的文件操作(SqlServer2000或SqlServer 2000 SP4补丁安装)
在安装SqlServer 2000或者SqlServer 2000 SP4补丁时常常会出现这样的提示,从而不能进行安装,即使重新启动了计算机,也还是会有同样的提示.在网上查了一下资料,原来是注册表里记 ...
- java本地与树莓派中采用UDP传输文本、图片
今天解决了一个困扰好几天的问题,由于比赛需要,需要用java语言,并采用UDP传输协议,让树莓派与服务器(就是本机)建立连接传输视频,图片. 由于UDP是建立在无连接的协议上,因此就碰到了一个很尴尬的 ...
- java.util之一:ArrayList
ArrayList是java中的线性结构的一种表示方法,在java中使用频率非常高,下面来一步一步分析其底层的实现.(JDK1.8) 一.构造函数 ArrayList的构造函数有三个,分别如下, 我们 ...
- 深度学习面试题29:GoogLeNet(Inception V3)
目录 使用非对称卷积分解大filters 重新设计pooling层 辅助构造器 使用标签平滑 参考资料 在<深度学习面试题20:GoogLeNet(Inception V1)>和<深 ...
- ASP.NET_微信JS_SDK调用
using System;using System.Collections.Generic;using System.IO;using System.Linq;using System.Net;usi ...
- pt-table-checksum校验与pt-table-sync修复数据【转】
1:下载工具包 登录网站下载相应的工具包 https://www.percona.com/downloads/percona-toolkit/LATEST/ 2:安装 (1)yum安装: sudo y ...
- eclipse remote system explorer operation
Remote System Explorer Operation卡死Eclipse解决方案 - 披萨大叔的博客 - CSDN博客https://blog.csdn.net/qq_27258799/ar ...