入门大数据---SparkSQL_Dataset和DataFrame简介
一、Spark SQL简介
Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据。它具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种开发语言;
- 支持多达上百种的外部数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC 等;
- 支持 HiveQL 语法以及 Hive SerDes 和 UDF,允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性;
- 支持扩展并能保证容错。

二、DataFrame & DataSet
2.1 DataFrame
为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由具名列组成的数据集。它在概念上等同于关系数据库中的表或 R/Python 语言中的 data frame。 由于 Spark SQL 支持多种语言的开发,所以每种语言都定义了 DataFrame 的抽象,主要如下:
| 语言 | 主要抽象 |
|---|---|
| Java | Dataset[T] |
| Python | DataFrame |
| Scala | Dataset[T] & DataFrame (Dataset[Row] 的别名) |
| R | DataFrame |
2.2 DataFrame 对比 RDDs
DataFrame 和 RDDs 最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据,它们内部的数据结构如下:
DataFrame 内部的有明确 Scheme 结构,即列名、列字段类型都是已知的,这带来的好处是可以减少数据读取以及更好地优化执行计划,从而保证查询效率。
DataFrame 和 RDDs 应该如何选择?
- 如果你想使用函数式编程而不是 DataFrame API,则使用 RDDs;
- 如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,
- 如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的 (如日志),出于性能上的考虑,应优先使用 DataFrame。
2.3 DataSet
Dataset 也是分布式的数据集合,在 Spark 1.6 版本被引入,它集成了 RDD 和 DataFrame 的优点,具备强类型的特点,同时支持 Lambda 函数,但只能在 Scala 和 Java 语言中使用。在 Spark 2.0 后,为了方便开发者,Spark 将 DataFrame 和 Dataset 的 API 融合到一起,提供了结构化的 API(Structured API),即用户可以通过一套标准的 API 就能完成对两者的操作。
这里注意一下:DataFrame 被标记为 Untyped API,而 DataSet 被标记为 Typed API,后文会对两者做出解释。
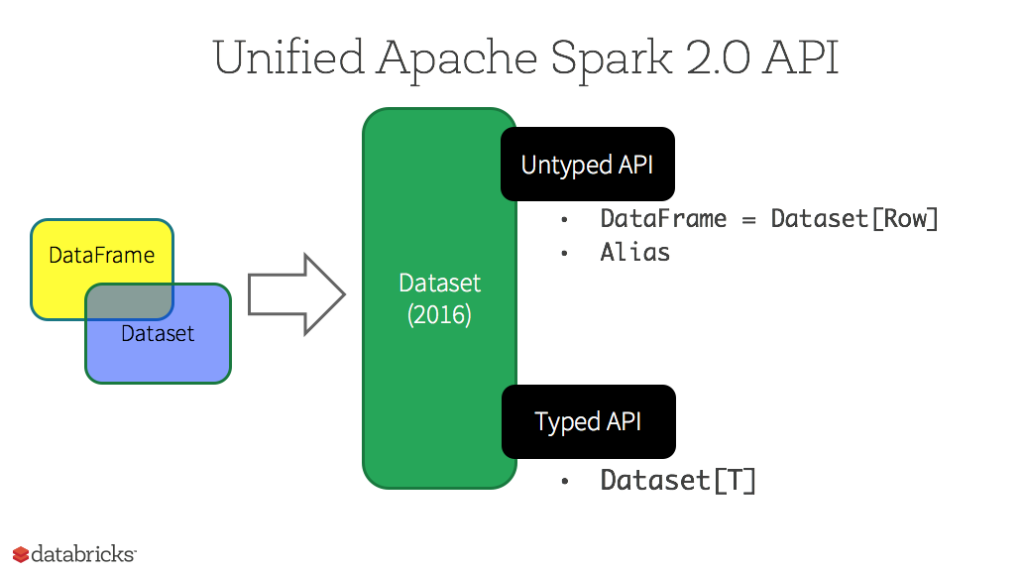
2.4 静态类型与运行时类型安全
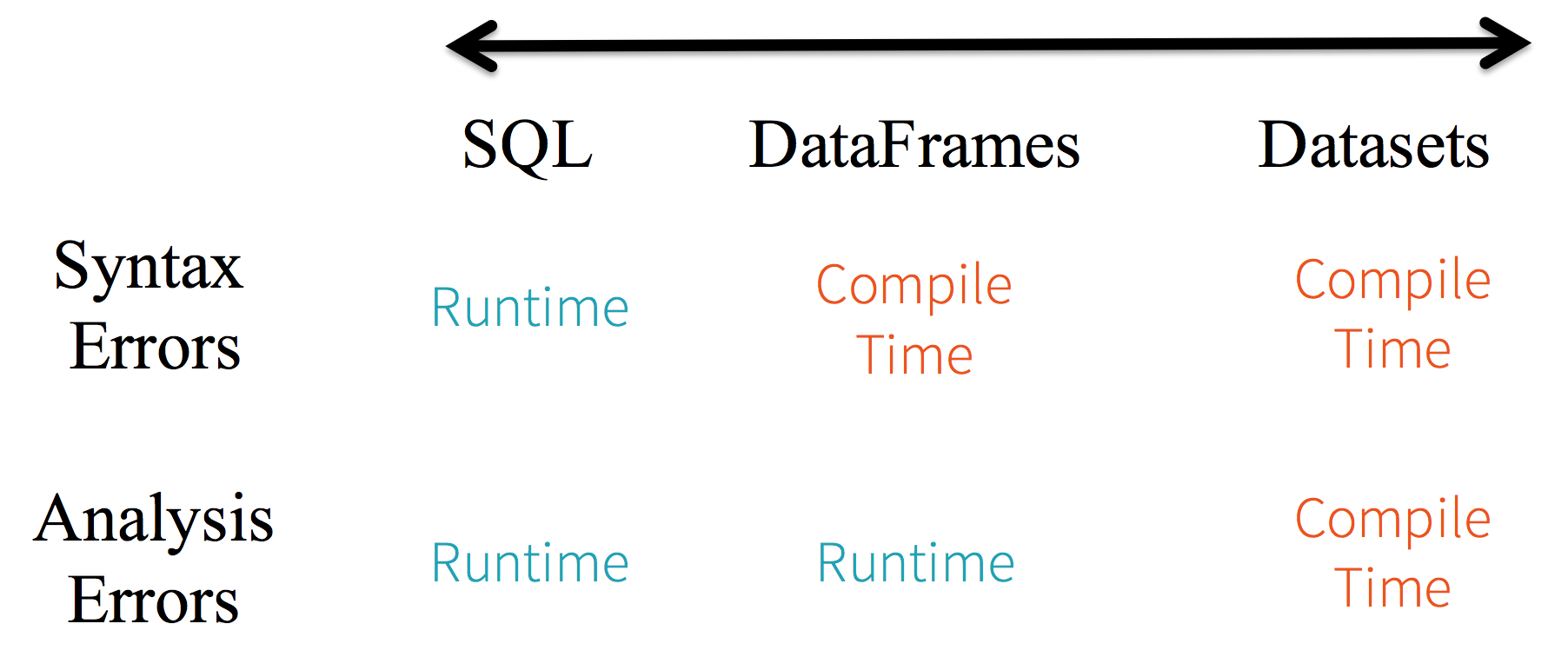
静态类型 (Static-typing) 与运行时类型安全 (runtime type-safety) 主要表现如下:
在实际使用中,如果你用的是 Spark SQL 的查询语句,则直到运行时你才会发现有语法错误,而如果你用的是 DataFrame 和 Dataset,则在编译时就可以发现错误 (这节省了开发时间和整体代价)。DataFrame 和 Dataset 主要区别在于:
在 DataFrame 中,当你调用了 API 之外的函数,编译器就会报错,但如果你使用了一个不存在的字段名字,编译器依然无法发现。而 Dataset 的 API 都是用 Lambda 函数和 JVM 类型对象表示的,所有不匹配的类型参数在编译时就会被发现。
以上这些最终都被解释成关于类型安全图谱,对应开发中的语法和分析错误。在图谱中,Dataset 最严格,但对于开发者来说效率最高。
上面的描述可能并没有那么直观,下面的给出一个 IDEA 中代码编译的示例:
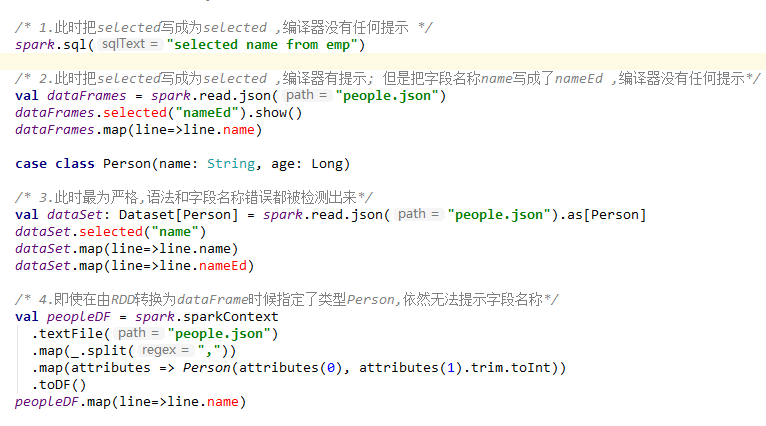
这里一个可能的疑惑是 DataFrame 明明是有确定的 Scheme 结构 (即列名、列字段类型都是已知的),但是为什么还是无法对列名进行推断和错误判断,这是因为 DataFrame 是 Untyped 的。
2.5 Untyped & Typed
在上面我们介绍过 DataFrame API 被标记为 Untyped API,而 DataSet API 被标记为 Typed API。DataFrame 的 Untyped 是相对于语言或 API 层面而言,它确实有明确的 Scheme 结构,即列名,列类型都是确定的,但这些信息完全由 Spark 来维护,Spark 只会在运行时检查这些类型和指定类型是否一致。这也就是为什么在 Spark 2.0 之后,官方推荐把 DataFrame 看做是 DatSet[Row],Row 是 Spark 中定义的一个 trait,其子类中封装了列字段的信息。
相对而言,DataSet 是 Typed 的,即强类型。如下面代码,DataSet 的类型由 Case Class(Scala) 或者 Java Bean(Java) 来明确指定的,在这里即每一行数据代表一个 Person,这些信息由 JVM 来保证正确性,所以字段名错误和类型错误在编译的时候就会被 IDE 所发现。
case class Person(name: String, age: Long)
val dataSet: Dataset[Person] = spark.read.json("people.json").as[Person]
三、DataFrame & DataSet & RDDs 总结
这里对三者做一下简单的总结:
- RDDs 适合非结构化数据的处理,而 DataFrame & DataSet 更适合结构化数据和半结构化的处理;
- DataFrame & DataSet 可以通过统一的 Structured API 进行访问,而 RDDs 则更适合函数式编程的场景;
- 相比于 DataFrame 而言,DataSet 是强类型的 (Typed),有着更为严格的静态类型检查;
- DataSets、DataFrames、SQL 的底层都依赖了 RDDs API,并对外提供结构化的访问接口。
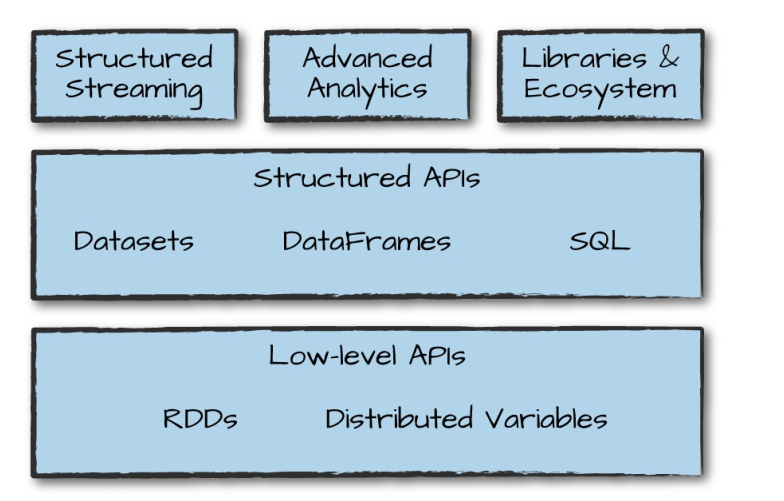
四、Spark SQL的运行原理
DataFrame、DataSet 和 Spark SQL 的实际执行流程都是相同的:
- 进行 DataFrame/Dataset/SQL 编程;
- 如果是有效的代码,即代码没有编译错误,Spark 会将其转换为一个逻辑计划;
- Spark 将此逻辑计划转换为物理计划,同时进行代码优化;
- Spark 然后在集群上执行这个物理计划 (基于 RDD 操作) 。
4.1 逻辑计划(Logical Plan)
执行的第一个阶段是将用户代码转换成一个逻辑计划。它首先将用户代码转换成 unresolved logical plan(未解决的逻辑计划),之所以这个计划是未解决的,是因为尽管您的代码在语法上是正确的,但是它引用的表或列可能不存在。 Spark 使用 analyzer(分析器) 基于 catalog(存储的所有表和 DataFrames 的信息) 进行解析。解析失败则拒绝执行,解析成功则将结果传给 Catalyst 优化器 (Catalyst Optimizer),优化器是一组规则的集合,用于优化逻辑计划,通过谓词下推等方式进行优化,最终输出优化后的逻辑执行计划。

4.2 物理计划(Physical Plan)
得到优化后的逻辑计划后,Spark 就开始了物理计划过程。 它通过生成不同的物理执行策略,并通过成本模型来比较它们,从而选择一个最优的物理计划在集群上面执行的。物理规划的输出结果是一系列的 RDDs 和转换关系 (transformations)。
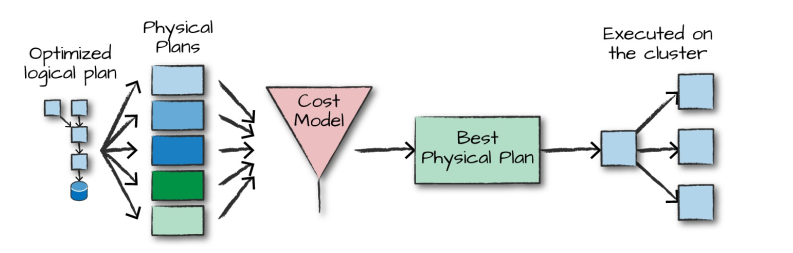
4.3 执行
在选择一个物理计划后,Spark 运行其 RDDs 代码,并在运行时执行进一步的优化,生成本地 Java 字节码,最后将运行结果返回给用户。
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
- Spark SQL, DataFrames and Datasets Guide
- 且谈 Apache Spark 的 API 三剑客:RDD、DataFrame 和 Dataset(译文)
- A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets(原文)
入门大数据---SparkSQL_Dataset和DataFrame简介的更多相关文章
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 大数据:Hadoop(简介)
一.简介 定义:开源的,做分布式存储与分布式计算的平台: 功能:搭建大型数据仓库,对PB级数据进行存储.处理.分析.统计等业务:(如日志分析.数据挖掘) Hadoop工作模块 Common:提供框架和 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
随机推荐
- 50个SQL语句(MySQL版) 问题八
--------------------------表结构-------------------------- student(StuId,StuName,StuAge,StuSex) 学生表 tea ...
- PAT1033 旧键盘打字 (20分) (关于测试点4超时问题)
1033 旧键盘打字 (20分) 旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现.现在给出应该输入的一段文字.以及坏掉的那些键,打出的结果文字会是怎样? 输入格式: 输入在 2 ...
- 面试官问我会不会Elasticsearch,我语塞了...
少点代码,多点头发 本文已经收录至我的GitHub,欢迎大家踊跃star 和 issues. https://github.com/midou-tech/articles 从今天开始准备给大家带来全新 ...
- (Java实现) 最大团问题 部落卫队
首先介绍下最大团问题: 问题描述:给一个无向图G=(V,E) ,V是顶点集合,E是边集合.然后在这顶点集合中选取几个顶点,这几 个顶点任意两个之间都有边在E中.求最多可以选取的顶点个数.这几个顶点就构 ...
- Java实现 LeetCode 22 括号生成
22. 括号生成 给出 n 代表生成括号的对数,请你写出一个函数,使其能够生成所有可能的并且有效的括号组合. 例如,给出 n = 3,生成结果为: [ "((()))", &quo ...
- Java实现LeetCode_0028_ImplementStrStr
package javaLeetCode.primary; import java.util.Scanner; public class ImplementStrStr_28 { public sta ...
- java实现最大连续和问题
/* 10 5 -3 12 -31 15 22 -7 6 -8 -9 10 .... 暴力:O(n^3) 分治:[ mid ) 三种情况求最大 基线法: O(n) 2个数组: 从左到本位:出现的最大累 ...
- Java实现第九届蓝桥杯螺旋折线
螺旋折线 题目描述 如图p1.pgn所示的螺旋折线经过平面上所有整点恰好一次. 对于整点(X, Y),我们定义它到原点的距离dis(X, Y)是从原点到(X, Y)的螺旋折线段的长度. 例如dis(0 ...
- Java实现第八届蓝桥杯兴趣小组
兴趣小组 为丰富同学们的业余文化生活,某高校学生会创办了3个兴趣小组 (以下称A组,B组,C组). 每个小组的学生名单分别在[A.txt],[B.txt]和[C.txt]中. 每个文件中存储的是学生的 ...
- 死啃了String源码之后
Java源码之String 说在前面: 为什么看源码: 最好的学习的方式就是模仿,接下来才是创造.而源码就是我们最好的模仿对象,因为写源码的人都不是一般的人,所以用心学习源码,也就可能变成牛逼的人.其 ...