Solr5.5.1 IK中文分词配置与使用
前言
用过Lucene.net的都知道,我们自己搭建索引服务器时和解决搜索匹配度的问题都用到过盘古分词。其中包含一个词典。 那么既然用到了这种国际化的框架,那么就避免不了中文分词。尤其是国内特殊行业比较多。比如油田系统从勘探、打井、投产等若干环节都涉及一些专业词汇。 再像电商,手机、手机配件、笔记本、笔记本配件之类。汽车,品牌、车系、车型等等,这一系列数据背后都涉及各自领域的专业名次,所以中文分词就最终的目的还是为了解决搜索结果的精确度和匹配度的问题。
IK搜索预览
我的univeral Core里包含两条数据,第二条数据的title和author都是中文的。 然后我用关键字q=title:平凡来搜索,搜索出来第二条数据。 如果你在你的索引库里没搜索出来也不要奇怪,配置下IK中文分词就可以了。
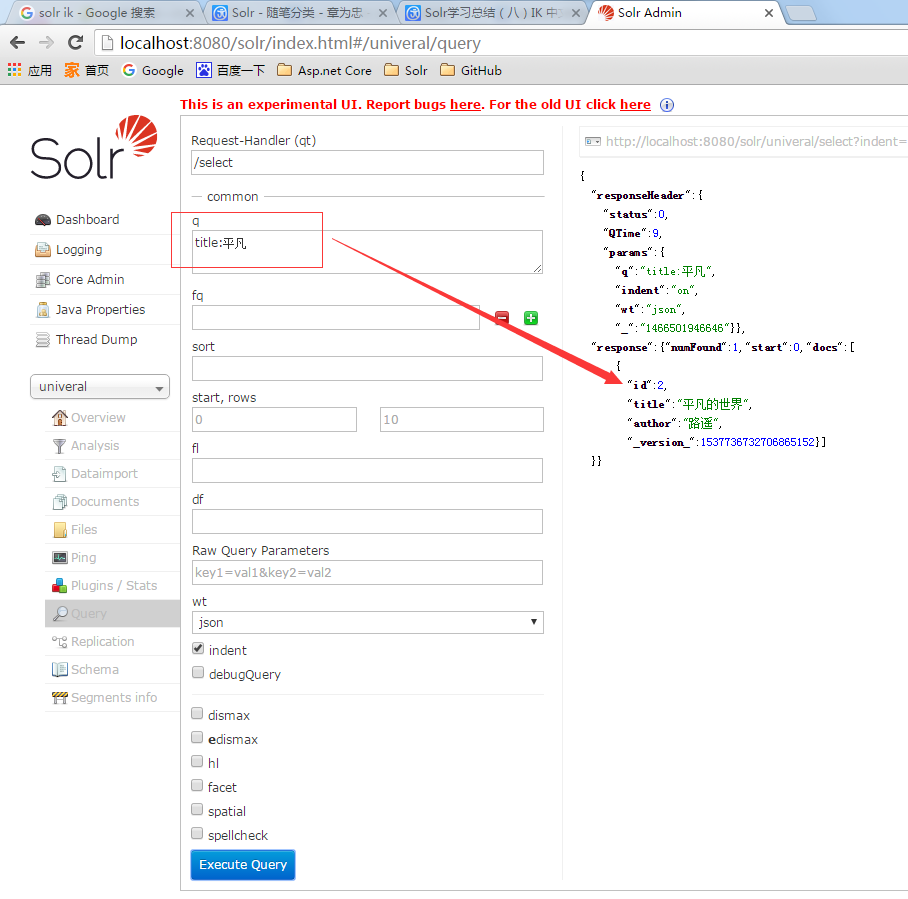
中文语义分析
在索引库Core左侧菜单Analysis中,你可以输入复杂的查询【关键字】,选择对应字段,点击【Analysis Values】会帮你分析出当前这个复杂的词组都会分解出那几个搜索关键字或关键词来。如果这里满足不了你的专业词汇,那就该从词典下手了。我这里输入了:平凡的世界。分析后得出两个词:平凡、世界。 也就是我在上一张图中用平凡搜索的结果。

中文分词的配置和使用
1、下载对应IK版本。我本地部署的Solr5.5.1。 所以就下载最新版本。
2、把ik目录下的文件复制到tomcat/webapps/solr/WEB-INF/lib目录下。 ik目录里有一个ext.dic、stopword.dic。 可以打开看一看里面内容。
3、修改schema.xml。我本地是univeral/conf/managed-schema。 增加中文分词配置节点,内容如下
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
4、修改对应field的类型。我修改了两个字段
<field name="title" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
<field name="author" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
参考教程:http://www.cnblogs.com/zhangweizhong/p/5593909.html
备注
如果之前你已经创建了索引,那么配置IK中文分词后先修改schema.xml中的field对应类型。 清空索引后重新创建索引。 OK。大功搞成。
Solr5.5.1 IK中文分词配置与使用的更多相关文章
- Solr学习总结(八)IK 中文分词的配置和使用
最近,很多朋友问我solr 中文分词配置的问题,都不知道怎么配置,怎么使用,原以为很简单,没想到这么多朋友都有问题,所以今天就总结总结中文分词的配置吧. 有的时候,用户搜索的关键字,可能是一句话,不是 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- Solr7.2.1环境搭建和配置ik中文分词器
solr7.2.1环境搭建和配置ik中文分词器 安装环境:Jdk 1.8. windows 10 安装包准备: solr 各种版本集合下载:http://archive.apache.org/dist ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- Elasticsearch 5 Ik+pinyin分词配置详解
版权声明:本文为博主原创文章,地址:http://blog.csdn.net/napoay,转载请留言. 一.拼音分词的应用 拼音分词在日常生活中其实很常见,也许你每天都在用.打开淘宝看一看吧,输入拼 ...
- Elasticsearch入门和查询语法分析(ik中文分词)
全文搜索现在已经是很常见的功能了,当然你也可以用mysql加Sphinx实现.但开源的Elasticsearch(简称ES)目前是全文搜索引擎的首选.目前像GitHub.维基百科都使用的是ES,它可以 ...
随机推荐
- jsp前端实现分页代码
前端需要订一page类包装,其参数为 private Integer pageSize=10; //每页记录条数=10 private Integer totalCount; //总记录条数 priv ...
- 实例操作JSONP原理
絮语:按这个步骤走,你就会明白JSONP是什么鬼. 1.工程目录: ng-mywork demo.html test.js 2.nginx的server配置 server { listen ; ser ...
- 有趣的 CSS 像素艺术
原文地址:https://css-tricks.com/fun-times-css-pixel-art/#article-header-id-4 译者:nzbin 友情提示:由于国内网络的原因,Cod ...
- Hbase的伪分布式安装
Hbase安装模式介绍 单机模式 1> Hbase不使用HDFS,仅使用本地文件系统 2> ZooKeeper与Hbase运行在同一个JVM中 分布式模式– 伪分布式模式1> 所有进 ...
- 在jekyll模板博客中添加网易云模块
最近使用GitHub Pages + Jekyll 搭建了个人博客,作为一名重度音乐患者,博客里面可以不配图,但是不能不配音乐啊. 遂在博客里面引入了网易云模块,这里要感谢网易云的分享机制,对开发者非 ...
- 【NLP】揭秘马尔可夫模型神秘面纱系列文章(一)
初识马尔可夫和马尔可夫链 作者:白宁超 2016年7月10日20:34:20 摘要:最早接触马尔可夫模型的定义源于吴军先生<数学之美>一书,起初觉得深奥难懂且无什么用场.直到学习自然语言处 ...
- Autofac - 方法注入
方法注入, 其实就是在注册类的时候, 把这个方法也注册进去. 那么在生成实例的时候, 会自动调用这个方法. 其实现的方法, 有两种. 准备工作: public interface IAnimal { ...
- Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/logging/LogFactory
学习架构探险,从零开始写Java Web框架时,在学习到springAOP时遇到一个异常: "C:\Program Files\Java\jdk1.7.0_40\bin\java" ...
- 【干货分享】流程DEMO-补打卡
流程名: 补打卡申请 业务描述: 当员工在该出勤的工作日出勤但漏打卡时,于一周内填写补打卡申请. 流程相关文件: 流程包.xml 流程说明: 直接导入流程包文件,即可使用本流程 表单: 流程: 图片 ...
- Web开发安全之文件上传安全
很长一段时间像我这种菜鸡搞一个网站第一时间反应就是找上传,找上传.借此机会把文件上传的安全问题总结一下. 首先看一下DVWA给出的Impossible级别的完整代码: <?php if( iss ...