Elasticsearch入门和查询语法分析(ik中文分词)
全文搜索现在已经是很常见的功能了,当然你也可以用mysql加Sphinx实现。但开源的Elasticsearch(简称ES)目前是全文搜索引擎的首选。目前像GitHub、维基百科都使用的是ES,它可以快速的存储,搜索和分析数据。
一、安装与启动
ES的运行需要依赖java环境,可以在命令行运行 java --version 。如果出现

说明已经安装了,否则你就需要安装下java环境。
然后我们就可以开始装ES了。1、可以用docker容器安装。2、用压缩包安装。
我是用压缩包安装的。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.1.tar.gz
tar -xzf elasticsearch-6.3..tar.gz
cd elasticsearch-6.3./
然后输入 ./bin/elasticsearch 就可以启动ES了。在浏览器上输入 localhost: ,如果出现
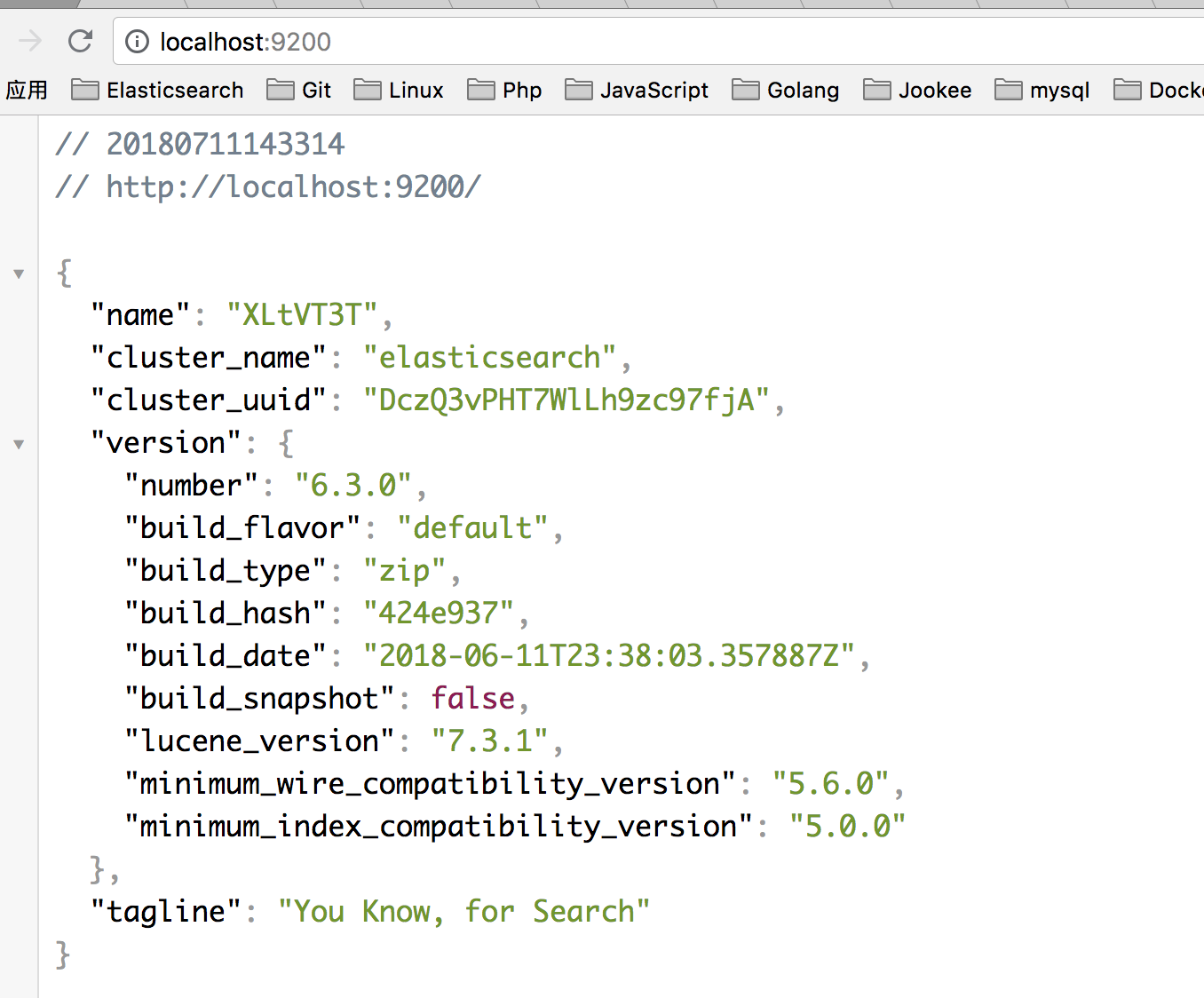
就说明ES成功跑起来了。
不了解ES的同学可以去看看阮老师的这篇文章http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html。
二、IK分词
ES默认的分词是英文分词,对中文分词支持的并不好。所以我们就需要安装ik中文分词。让我们看看区别。
在这里需要说明的一点时,ES很多API请求都是GET带上了Request Body。所以通过浏览器或者postman等工具发起GET请求时会报错。有两种方法可以解决。
1、通过命令含的curl请求。
curl -X GET "localhost:9200/_analyze" -H 'Content-Type: application/json' -d'
{
"analyzer" : "standard",
"text" : "this is a test"
}
'
2、在代码中通过curl请求。
// 通过php的guzzle包发起的请求
$client = new Client();
$response = $client->get('localhost:9200/_analyze', [
'json' => [
'analyzer' => 'standard',
'text' => "功能进阶",
]
]); $res = ($response->getBody()->getContents());
然后我们来看看ik中文分词和ES默认的分词区别。同样是上面的请求
ES默认分词结果
{
"tokens": [
{
"token": "功",
"start_offset": ,
"end_offset": ,
"type": "<IDEOGRAPHIC>",
"position":
},
{
"token": "能",
"start_offset": ,
"end_offset": ,
"type": "<IDEOGRAPHIC>",
"position":
},
{
"token": "进",
"start_offset": ,
"end_offset": ,
"type": "<IDEOGRAPHIC>",
"position":
},
{
"token": "阶",
"start_offset": ,
"end_offset": ,
"type": "<IDEOGRAPHIC>",
"position":
}
]
}
ik中文分词结果
ik分词也分两种分析器。ik_smart:尽可能少的进行中文分词。ik_max_word:尽可能多的进行中文分词。
$response = $client->get('localhost:9200/_analyze', [
'json' => [
'analyzer' => 'ik_max_word',
'text' => "功能进阶",
]
]);
得到的结果为:
{
"tokens": [
{
"token": "功能",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "能进",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "进阶",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
而ik_smart
$response = $client->get('localhost:9200/_analyze', [
'json' => [
'analyzer' => 'ik_smart',
'text' => "功能进阶",
]
]);
的结果为
{
"tokens": [
{
"token": "功能",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "进阶",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
其实他们的区别通过名字你也可以略知一二。哈哈。。。
假如有人想问,我就想把“功能进阶”当成一个词来搜索,可以吗?
Of course!!
这时候我们就要自定义分词。进入你的ES目录,运行 cd config/analysis-ik/ 进去ik分词的配置。找到IKAnalyzer.cfg.xml文件,然后 vi IKAnalyzer.cfg.xml 。

我在 elasticsearch-6.3./config/analysis-ik 目录下,创建了 custom/mydict.dic ,然后添加到上图的红色框框中,这就是你自定义分词的文件。如果有多个文件,可以用英文分号(;)隔开。

可以看到,我在自定义中文分词文件中添加了“功能进阶”这个词。这时候用ik_smart分析器的结果是:
{
"tokens": [
{
"token": "功能进阶",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
很好,这就是我们想要的。
三、Query DSL
- match
查询语法如下:title是需要查询的字段名,可以被替换成任何字段。query对应的是所需的查询。比如这里会被拆分成‘php’和‘后台’,应为operator是or,所以ES会去所有数据里的title字段查询包含‘后台’和‘php’的,如果operator为and,这查询的是即包含‘后台’又有‘php’的数据,这应该很好理解。
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'match' => [
'title' => [
'query' => '后台php',
'operator' => 'or',
]
]
]
]
]);
- multi_match
如果想在多个字段中查找,那就需要用到multi_match查询,语法如下:
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'multi_match' => [
'query' => '张三 php',
'fields' => ['title', 'desc', 'user']
]
]
]
]);
- query_string
查询语法如下:类似match查询的operator,在这里需要在query中用OR或AND实现。
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'query_string' => [
'query' => '(张三) OR (php)',
'default_field' => 'title',
]
]
]
]);
多字段查询如下:
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'query_string' => [
'query' => '(张三) OR (php)',
'fields' => ['title', 'user'],
]
]
]
]);
- range query
这是范围查询,例如查询年龄在10到20岁之间的。查询语法如下:
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'range' => [
'age' => [
'gte' => 10,
'lte' => 20,
],
]
]
]
]);
gte表示>=,lte表示<=,gt表示>,lt表示<。
- bool查询
bool查询的语法都是一样的。如下:
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'bool' => [
'must/filter/should/must_not' => [
[
'query_string' => [
'query' => '研发',
]
],
[
'range' => [
'age' => [
'gt' => 20
]
]
],
],
]
]
]
]);
1)must:must查询是查询字段中必须满足上面两个条件,并且会计算到score中。
2)filter:filter查询与must一样,都必须满足上面两个条件,只不过查询结果不会计算score,也就是score始终为0.
3)should:should查询只需要满足上面两种查询条件中的一种即可。
4)must_not:must_not查询是必须不满足上面两个查询条件。
以上也是我看文档总结出来的,如有不对的地方,望大神指点。
Elasticsearch入门和查询语法分析(ik中文分词)的更多相关文章
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- elasticsearch使用ik中文分词器
elasticsearch使用ik中文分词器 一.背景 二.安装 ik 分词器 1.从 github 上找到和本次 es 版本匹配上的 分词器 2.使用 es 自带的插件管理 elasticsearc ...
- Elasticsearch:IK中文分词器
Elasticsearch内置的分词器对中文不友好,只会一个字一个字的分,无法形成词语,比如: POST /_analyze { "text": "我爱北京天安门&quo ...
- Solr5.5.1 IK中文分词配置与使用
前言 用过Lucene.net的都知道,我们自己搭建索引服务器时和解决搜索匹配度的问题都用到过盘古分词.其中包含一个词典. 那么既然用到了这种国际化的框架,那么就避免不了中文分词.尤其是国内特殊行业比 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
随机推荐
- 算法之冒泡排序(Java语言)
冒泡排序(英语:Bubble Sort) 是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也就是说 ...
- 获取表SQLSERVER 的表结构信息(字段名,长度,精度,类型,NULL,ID,PRI)
select sys.columns.name, sys.types.name, sys.columns.precision,sys.columns.scale, sys.columns.is_nul ...
- POP动画[1]
POP动画[1] pop动画是facebook扩展CoreAnimation的,使用及其方便:) 1:Spring系列的弹簧效果(两个动画kPOPLayerBounds与kPOPLayerCorner ...
- Nginx学习---企业级nginx环境搭建
1.1. nginx安装环境 1.系统要求 nginx是C语言开发,建议在linux上运行,本教程使用Centos6.5作为安装环境. 1-1 安装 GCC 源码安装nginx需要依赖gcc环境,需要 ...
- 数据库相关文章转载(2) MySQL自带的性能压力测试工具mysqlslap详解
PS:今天一同事问我有木有比较靠谱的mysql压力测试工具可用.其实mysql自带就有一个叫mysqlslap的压力测试工具,还是模拟的不错的.下面举例说说.mysqlslap是从5.1.4版开始的一 ...
- java内部类之成员内部类之局部内部类
局部内部类特点: 1.定义在代码块.方法体内的类叫局部内部类 2.局部内部类访问外部类的属性和方法使用“外部类名.this.属性名”和“外部类名.this.方法名(参数)”的形式 3.对外部世界完全隐 ...
- Angular2 Router路由相关
路由设置 Angular中路由的配置应该按照先具体路由到通用路由的设置,因为Angular使用先匹配者优先的原则. 示例: 路由设置如下: export const reportRoute: Rout ...
- 组合数取模方法总结(Lucas定理介绍)
1.当n,m都很小的时候可以利用杨辉三角直接求. C(n,m)=C(n-1,m)+C(n-1,m-1): 2.n和m较大,但是p为素数的时候 Lucas定理是用来求 c(n,m) mod p,p为素数 ...
- cogs 2355. [HZOI 2015] 有标号的DAG计数 II
题目分析 来自2013年王迪的论文<浅谈容斥原理> 设\(f_{n,S}\)表示n个节点,入度为0的点集恰好为S的方案数. 设\(g_{n,S}\)表示n个节点,入度为0的点集至少为S的方 ...
- iOS--性能优化--保持界面流畅
卡顿产生的原因和解决方案 在 VSync 信号到来后,系统图形服务会通过 CADisplayLink 等机制通知 App,App 主线程开始在 CPU 中计算显示内容,比如视图的创建.布局计算.图片解 ...