python爬虫入门(5)-Scrapy概述
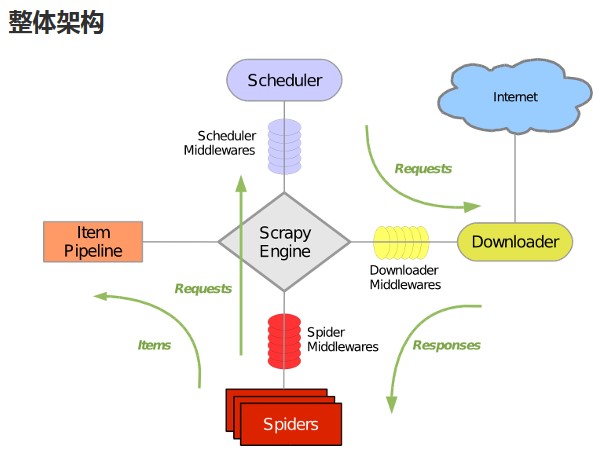
- 引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
- 调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器(Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛(Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
- 项目管道(Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares),位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件(Spider Middlewares),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middlewares),介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
python爬虫入门(5)-Scrapy概述的更多相关文章
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- 1.Python爬虫入门一之综述
要学习Python爬虫,我们要学习的共有以下几点: Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy Python爬虫 ...
- 转 Python爬虫入门一之综述
转自: http://cuiqingcai.com/927.html 静觅 » Python爬虫入门一之综述 首先爬虫是什么? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为 ...
- 爬虫入门三 scrapy
title: 爬虫入门三 scrapy date: 2020-03-14 14:49:00 categories: python tags: crawler scrapy框架入门 1 scrapy简介 ...
- python爬虫入门-开发环境与小例子
python爬虫入门 开发环境 ubuntu 16.04 sublime pycharm requests库 requests库安装: sudo pip install requests 第一个例子 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
随机推荐
- Ansible VMware模块使用示例
vmware_vm_facts模块使用示例 执行条件: 安装Pyvmimo: pip install pyvmomi 方法一,直接编写单个yaml文件: - hosts: localhost # 注 ...
- [JavaWeb]关于DBUtils中QueryRunner的一些解读(转)
QueryRunner类 QueryRunner中提供对sql语句操作的API它主要有三个方法 query() 用于执行select update() 用于执行insert/update/delete ...
- db2快照
一.获取快照日志 #1.查看数据库编目 db2 list db directory #2.attach 到要分析的数据库 db2 attach to pm1_9 user db2dev #3.conn ...
- UVA 814 The Letter Carrier's Rounds(JAVA基础map)
题解:就是按照题目模拟就好 但是这个题目让我发现了我Java里面许多问题 具体看代码,但是还是分为这几个方面 属性的作用域问题,缓冲区问题,map与list映射的问题,输出多个空格不一定是/t,反转思 ...
- Kruskal算法初步
2017-09-18 21:53:00 writer:pprp 代码如下: /* @theme: kruskal @writer:pprp @date:2017/8/19 @begin:21:19 @ ...
- asp.net core + log4net+exceptionles+DI
参考了ABP的代码,我也用依赖注入的原则,设计了日志模块. 与abp不同之处在于:1)DI容器使用的是.net core自带的注入容器,2)集成了excetpionless日志模块,3)不依赖于abp ...
- jmeter-负载
主: remote_hosts=10.0.70.35:1099,10.0.70.47:1099 server.rmi.localport=1099 从: remote_hosts=10.0.70.3 ...
- git bash 出显错误不能用,怎么解决
解决方法: 好像就是64的会出问题,其实32位的git也可以安装在64位的系统上. 将你64位的git卸掉了后,下载一个32位的git安装,就可以正常使用了, 当然,你的32位的出了错,卸了后也这样处 ...
- 《Think in Java》(十二)通过异常处理错误
异常虽然简单,但是很有用!学完这一章还是发现 Java 异常还是有很多可学之处的,比如:异常说明,异常链等.
- 《Think in Java》(十一)持有对象
Java 中的持有对象就是容器啦,看完这一章粗略的了解了 Java 中的容器框架以及常用实现!但是容器框架中的接口以及实现类有好多,下午还得好好看看第 17 章--容器深入研究以及 Java 官方的文 ...