storm(一) window机制
Watermark作用
在解释storm的window之前先说明一下watermark原理。
Watermark中文翻译为水位线更为恰当。
顺序的数据从源头开始发送到到操作,中间过程肯定会出现数据乱序情况,比如网络原因,数据并发发送等。如何区分乱序的数据和正常的数据,就引申出了watermark。
Watermark是每一个时间窗口的下限,意思是说当watermark大于了窗口截止时间,那么该窗口就应该被关闭。而watermar也会随着时间窗口的变化不断更新自己。
参考下图,列举了几个关键的术语以及它们的定位。
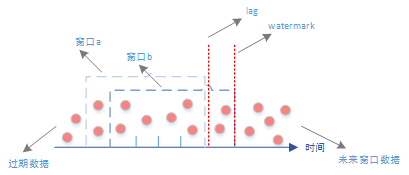
watermark可以理解为自定义的可以代表整个流的时间点,并且会不断更新。一般情况,当watermark-lastWindowEndTs>slidingInterval,那么就会触发一个新的窗口。
lag可以理解为自定义的最大数据延迟时间范围,由于实时计算对实时性的需求,而数据在网络波动等情况下不是按顺序到达计算,所以lag的出现就是为了解决那些能到达的数据但是时间比正常数据晚的情况,当该数据的时间小于watermark-lag。那么就判定该数据为延迟数据,可以选择直接丢弃或者其他自定义操作。
概述
总体来看,抽象 tuple和watermark为Event,这样可以方便的把watermark注入到tuple。做统一化处理。
有5大组件组成
·WindowBoltExecutor
·WindowManager
·WaterMarkEventGenerator
·Trigger
·Eviction
WindowBoltExecutor负责整个window的初始化,参数配置和封装,
WindowManager负责存取数据,包括所有的数据操作
WaterMarkEventGenerator负责watermark的生成和维护
Trigger负责时间窗口的判断,决定是否触发窗口事件
Eviction负责数据状态的判断,得到数据是哪一种状态(KEEP,STOP,PROCESS,EXPIRED)
Watermark算法
所有流数据不一起处理,而是分开计算各个流最大时间,再根据最大时间集合计算出最小时间,这个时间就是watermark的时间。
这样做的目的是为了防止不同流传输的延迟不同,比方说,有2个上游A,B同时发数据,A由于网络较好,发送的数据比B快,导致了A的时间戳比B的大,如果watermark采用了全局最大值,那么时间窗口就会被提早关闭,而B发来的数据会被排除在该时间窗口
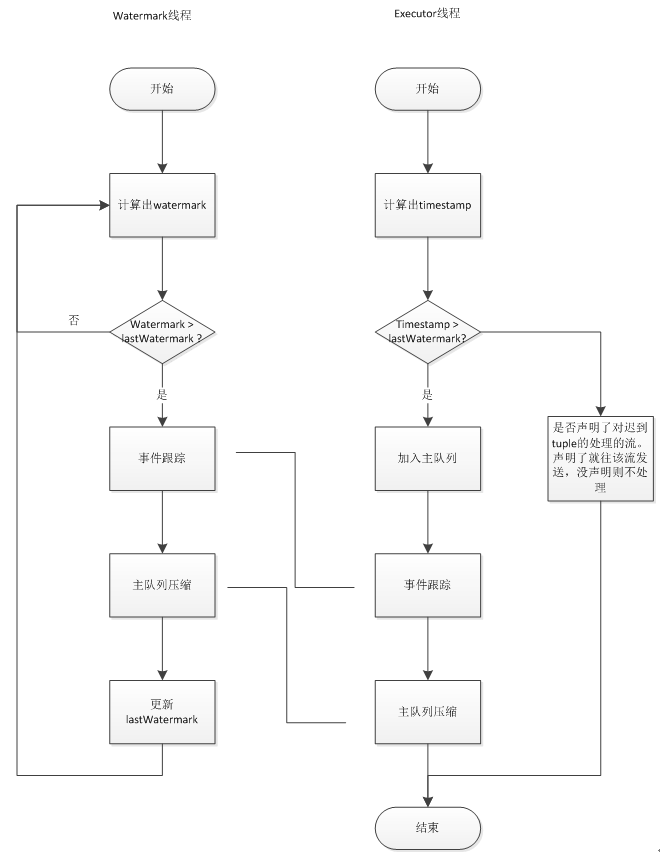
主逻辑流程
重要参数
|
英文 |
解释 |
|
windowLength |
窗口大小 |
|
slidingInterval |
窗口滑动步长 |
|
windowEndTs |
窗口截止时间 |
|
watermark |
水位线,判断是否关闭时间窗口的标志 |
|
maxLag |
时间窗口的最大延迟时间(网络等问题造成) |
|
eventTimestamp |
数据时间,每个数据都有自带的时间戳 |
数据4种状态
|
状态 |
解释 |
|
KEEP |
当前窗口不处理。是未来窗口的数据 |
|
STOP |
停止处理,数据时间戳比窗口截止时间+lag还大,说明不属于该窗口,之后的数据也不属于 |
|
PROCESS |
当前窗口内的数据 |
|
EXPIRE |
过期数据,需要被移除 当 窗口截止时间 – 数据时间 > 窗口大小 |
storm(一) window机制的更多相关文章
- 理解storm的ACKER机制原理
一.简介: storm中有一个很重要的特性: 保证发出的每个tuple都会被完整处理.一个tuple被完全处理的意思是: 这个tuple以及由这个tuple所产生的所有的子tuple都被成 ...
- Storm的ack机制在项目应用中的坑
正在学习storm的大兄弟们,我又来传道授业解惑了,是不是觉得自己会用ack了.好吧,那就让我开始啪啪打你们脸吧. 先说一下ACK机制: 为了保证数据能正确的被处理, 对于spout产生的每一个tup ...
- 【原】Storm 消息处理保障机制
Storm入门教程 1. Storm基础 Storm Storm主要特点 Storm基本概念 Storm调度器 Storm配置 Guaranteeing Message Processing(消息处理 ...
- storm的并发机制
storm的并发机制 storm计算支持在多台机器上水平扩容,通过将计算切分为多个独立的tasks在集群上并发执行来实现. 一个task可以简单地理解:在集群某节点上运行的一个spout或者bolt实 ...
- Storm(三)Storm的原理机制
一.Storm的数据分发策略 1. Shuffle Grouping 随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同. 轮询,平均分配 2. ...
- Storm消息容错机制(ack-fail机制)
storm消息容错机制(ack-fail) 1.介绍 在storm中,可靠的信息处理机制是从spout开始的. 一个提供了可靠的处理机制的spout需要记录他发射出去的tuple,当下游bolt处理t ...
- storm的acker机制
一.简介: storm中有一个很重要的特性: 保证发出的每个tuple都会被完整处理.一个tuple被完全处理的意思是: 这个tuple以及由这个tuple所产生的所有的子tuple都被成功处理.如果 ...
- storm(二) 事务机制
前言 为了保证tuple的强有序和exactly-once语义,storm提供了事务机制,为每个tuple提供一个id 设计方法1 为每个tuple设置一个事务id,在数据库保存事务id和当前处理的i ...
- Android全面解析之Window机制
前言 你好! 我是一只修仙的猿,欢迎阅读我的文章. Window,读者可能更多的认识是windows系统的窗口.在windows系统上,我们可以多个窗口同时运行,每个窗口代表着一个应用程序.但在安卓上 ...
随机推荐
- JavaScript中的原型与原型链
一直对JavaScript的原型与继承不了解,参考<JavaScript权威指南(第六版)>和<JavaScript高级程序设计(第三版)>对这个点的知识做个整理,方便自己记忆 ...
- Centos配置nginx反向代理8090端口到80端口
下面,我就来说说怎么反向代理自己的项目到默认80端口. 1)安装nginx:yum install nginx -y 2)启动nginx:service nginx start或者systemctl ...
- js-jquery-003-条形码-二维码【QR码】
一.基本使用 插件地址:https://github.com/jeromeetienne/jquery-qrcode 1.首先在页面中加入jquery库文件和qrcode插件. <script ...
- sap 动态字段的使用
1.sap中的动态字段其实类似c#里面的指针,都是指向的地址. 只是写法不同,sap 中的field-symbols就是类似指针. , b TYPE i. FIELD-SYMBOLS <fs&g ...
- POJ1088:滑雪(简单dp)
题目链接: http://poj.org/problem?id=1088 题目要求: 一个人可以从某个点滑向上下左右相邻四个点之一,当且仅当高度减小.求可以滑落的最长长度. 题目解析: 首先要先排一 ...
- Linux系统常用命令汇总
命令格式:命令 -选项 参数,例如:ls -la /usr:当有多个选项时,可以写在一起.ifconfig:查看当前机器的IP信息service network restart:重启网络服务servi ...
- 打开关闭oracle自动表分析
oracle 表的统计信息,跟他的执行计划很有关联 执行计划的正常是否,跟SQL的执行速度很有关系 首先讲解一下如何查看一个数据库的是否开启自动统计分析 1.查看参数:STATISTICS_LEV ...
- Selenium2.0 Webdriver 随笔
Webdriver can't action the element when the element is out of view 1. Scroll to the element use Java ...
- 前端学习笔记之HTML DOM操作
HTML DOM 当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model). DOM节点类型 文档节点 (document,唯一) 元素节点 (那些个标签div ...
- 360急速浏览器JS的调试
1.代码中添加debugger关键字 2.360急速浏览器中选择工具--开发人员选项,如下图所示,在sources面板中可以看到正在运行的JS代码,F10可以单步函数执行,在鼠标放在变量上可以跟踪变量 ...