【深度学习】批量归一化 BatchNormalization
一、背景
- 每层的参数需不断适应新的输入数据分布,降低学习速度,增大学习的难度(层数多)
- 输入可能趋向于变大或者变小(分布变广),导致激活值落入饱和区,阻碍学习
二、Batch Normalization
注:Batch Normalization 最开始的动机是缓解内部协变量偏移,但后来的研究者发现其主要优点是归一化会导致更平滑的优化地形。

if self.training:
mean = input.mean([0, 2, 3]) # 计算当前 batch 的均值
var = input.var([0, 2, 3], unbiased=False) # 计算当前 batch 的方差
n = input.numel() / input.size(1)
with torch.no_grad():
# 使用移动平均更新对数据集均值的估算
self.running_mean = exponential_average_factor * mean\
+ (1 - exponential_average_factor) * self.running_mean
# 使用移动平均更新对数据集方差的估算
self.running_var = exponential_average_factor * var * n / (n - 1)\
+ (1 - exponential_average_factor) * self.running_var
else:
mean = self.running_mean
var = self.running_var # 使用均值和方差将每个元素标准化
input = (input - mean[None, :, None, None]) / (torch.sqrt(var[None, :, None, None] + self.eps))
# 对标准化的结果进行缩放(可选)
if self.affine:
input = input * self.weight[None, :, None, None] + self.bias[None, :, None, None]
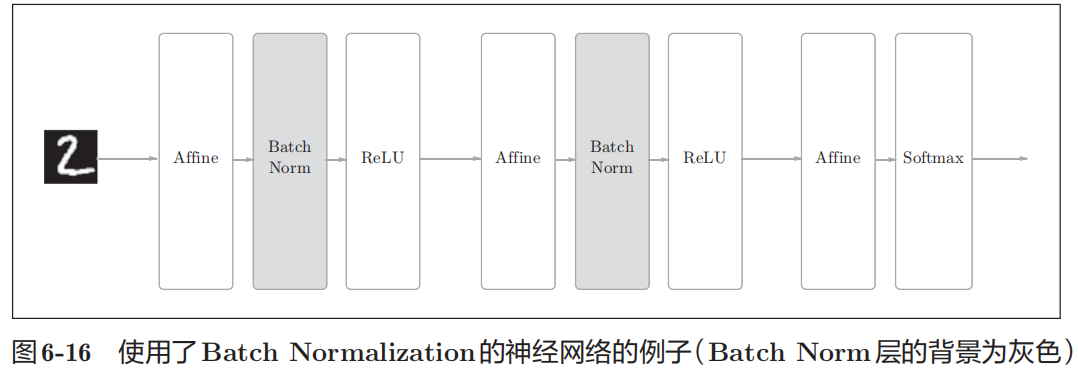
图解BatchNorm

m = nn.BatchNorm1d(100) # With Learnable Parameters
m = nn.BatchNorm1d(100, affine=False) # Without Learnable Parameters
input = torch.randn(20, 100)
output = m(input)
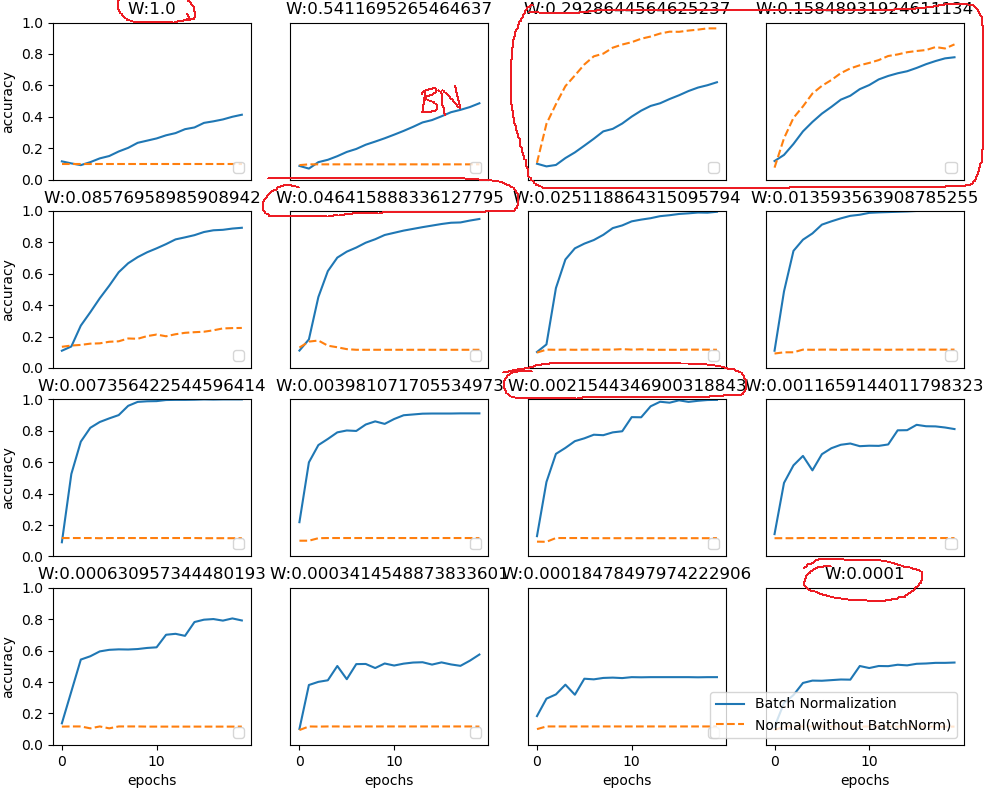
- 使用Batch Norm后,可以使学习快速进行,(学习得更快了)。(可以增大学习率)。
- 不那么依赖参数初始值。
- 抑制过拟合(降低Dropout等的必要性)
效果展示
解释: 由于在选取批次时具有随机性,因此使得神经网络不会“过拟合”到某个特定样本,从而提高网络的泛化能力。
参考内容
1、深度学习入门
2、李宏毅机器学习
【深度学习】批量归一化 BatchNormalization的更多相关文章
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- GIS地理处理脚本案例教程——批量栅格分割-批量栅格裁剪-批量栅格掩膜-深度学习样本批量提取
GIS地理处理脚本案例教程--批量栅格分割-批量栅格裁剪-批量栅格掩膜-深度学习样本批量提取 商务合作,科技咨询,版权转让:向日葵,135-4855_4328,xiexiaokui#qq.com 关键 ...
- 如何理解归一化(Normalization)对于神经网络(深度学习)的帮助?
如何理解归一化(Normalization)对于神经网络(深度学习)的帮助? 作者:知乎用户链接:https://www.zhihu.com/question/326034346/answer/730 ...
- Pytorch1.0深度学习:损失函数、优化器、常见激活函数、批归一化详解
不用相当的独立功夫,不论在哪个严重的问题上都不能找出真理:谁怕用功夫,谁就无法找到真理. —— 列宁 本文主要介绍损失函数.优化器.反向传播.链式求导法则.激活函数.批归一化. 1 经典损失函数 1. ...
- 深度学习归一化:BN、GN与FRN
在深度学习中,使用归一化层成为了很多网络的标配.最近,研究了不同的归一化层,如BN,GN和FRN.接下来,介绍一下这三种归一化算法. BN层 BN层是由谷歌提出的,其相关论文为<Batch No ...
- 【深度学习】线性回归(Linear Regression)——原理、均方损失、小批量随机梯度下降
1. 线性回归 回归(regression)问题指一类为一个或多个自变量与因变量之间关系建模的方法,通常用来表示输入和输出之间的关系. 机器学习领域中多数问题都与预测相关,当我们想预测一个数值时,就会 ...
- 深度学习中 --- 解决过拟合问题(dropout, batchnormalization)
过拟合,在Tom M.Mitchell的<Machine Learning>中是如何定义的:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比 ...
- L18 批量归一化和残差网络
批量归一化(BatchNormalization) 对输入的标准化(浅层模型) 处理后的任意一个特征在数据集中所有样本上的均值为0.标准差为1. 标准化处理输入数据使各个特征的分布相近 批量归一化(深 ...
- 深度学习系列 Part(3)
这是<GPU学习深度学习>系列文章的第三篇,主要是接着上一讲提到的如何自己构建深度神经网络框架中的功能模块,进一步详细介绍 Tensorflow 中 Keras 工具包提供的几种深度神经网 ...
- [DeeplearningAI笔记]神经网络与深度学习人工智能行业大师访谈
觉得有用的话,欢迎一起讨论相互学习~Follow Me 吴恩达采访Geoffrey Hinton NG:前几十年,你就已经发明了这么多神经网络和深度学习相关的概念,我其实很好奇,在这么多你发明的东西中 ...
随机推荐
- 【题解】P9749 [CSP-J 2023] 公路
\(Meaning\) \(Solution\) 这道题我来讲一个不一样的解法:\(dp\) 在写 \(dp\) 之前,我们需要明确以下几个东西:状态的表示,状态转移方程,边界条件和答案的表示. 状态 ...
- 使用 WPF + Chrome 内核实现高稳定性的在线客服系统复合应用程序
对于在线客服与营销系统,客服端指的是后台提供服务的客服或营销人员,他们使用客服程序在后台观察网站的被访情况,开展营销活动或提供客户服务.在本篇文章中,我将详细介绍如何通过 WPF + Chrome 内 ...
- 深入浅出 testing-library
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 本文作者:佳岚 The more your tests resemb ...
- 吉特日化MES 与周边系统集成架构
作者:情缘 出处:http://www.cnblogs.com/qingyuan/ 关于作者:从事仓库,生产软件方面的开发,在项目管理以及企业经营方面寻求发展之路 版权声明:本文版权归作者和博客园 ...
- Linux命令-文件、磁盘管理
Linux命令-文件.磁盘管理 1.文件管理 查看文件信息:ls ls是英文单词list的简写,其功能为列出目录的内容,是用户最常用的命令之一,它类似于DOS下的dir命令. Linux文件或者目 ...
- NC19777 卡牌游戏
题目链接 题目 题目描述 小贝喜欢玩卡牌游戏.某个游戏体系中共有N种卡牌,其中M种是稀有的.小贝每次和电脑对决获胜之后都会有一个抽卡机会,这时系统会随机从N种卡中选择一张给小贝.普通卡可能多次出现,而 ...
- 使用 .NET 8.0 和 OpenGL 创建一个简易的渲染器
前言我个人对三维渲染领域的开发有着浓厚的兴趣,尽管并未在相关行业工作过,我的了解还很片面.去年,在与群友聊天时,他们推荐了一本<Unity Shader入门精要>,说适合像我这样想自学的新 ...
- 【OpenGL ES】绘制圆形
1 前言 [OpenGL ES]绘制三角形 中介绍了绘制三角形的方法,[OpenGL ES]绘制正方形中介绍了绘制正方形的方法,本文将介绍绘制圆形的方法. OpenGL 以点.线段.三角形为图 ...
- MySQL日志:slow query log
ySQL的慢查询日志可以用来找出执行时间过长的查询语句,并进行针对性的优化. 一.slow log相关参数 以下参数都是动态参数,可以在实例运行时修改. slow_query_log=1 #是否启 ...
- Oracle 高水位(HWM: High Water Mark) 说明
一. 准备知识:ORACLE的逻辑存储管理. ORACLE在逻辑存储上分4个粒度: 表空间, 段, 区 和 块. 1.1 块: 是粒度最小的存储单位,现在标准的块大小是8K,ORACLE每一次I/O操 ...