Spark3.0 Standalone模式部署
之前介绍过Spark 1.6版本的部署,现在最新版本的spark为3.0.1并且已经完全兼容hadoop 3.x,同样仍然支持RDD与DataFrame两套API,这篇文章就主要介绍一下基于Hadoop 3.x的Spark 3.0部署,首先还是官网下载安装包,下载地址为:http://spark.apache.org/downloads.html,目前spark稳定版本有3.0.1与2.4.7两个版本,这里我们选择3.0.1的版本,然后是hadoop版本目前支持2.7和3.2,这里我们选择3.2的版本,如下:
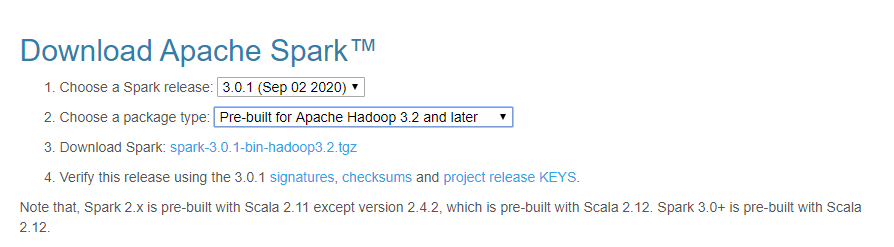
然后继续点击具体的包,选择合适的镜像下载,下载后的包名为:spark-3.0.1-bin-hadoop3.2.tgz,然后上传至服务器准备部署,集群环境同样符合之前的条件:例如主机名、免密、防火墙规则等,这里不再详细叙述,先说一下我们当前的环境,我们当前有4个节点如下:
192.168.122.5 bigdata1
192.168.122.6 bigdata2
192.168.122.7 bigdata3
192.168.122.8 bigdata4
其中每个节点都搭建了hadoop hdfs的环境,方便spark使用,hadoop版本为3.2,正常搭建的时候尽量也是hdfs的datanode节点和spark worker的节点一一对应,这样对数据传输也有利,如果确实无法对应,也要拷贝必要的配置文件到spark节点,因为接下来要配置,否则spark无法连接hdfs
我们这里计划bigdata1部署spark的master,bigdata2~bigdata4部署spark的worker或者说是slave,同样我们只在机器bigdata1上操作,然后配置好之后同步到其他节点再启动服务即可,下面开始spark集群的部署
1. 解压安装包并修改配置文件
tar -xzf spark-3.0.1-bin-hadoop3.2.tgz
cd spark-3.0.1-bin-hadoop3.2
然后配置文件都在conf目录下,执行 cd conf 进入目录,然后会看到有很多.template结尾的模板文件,里面写好的被注释的配置可以直接进行修改,我们拷贝模板文件出来作为spark的配置:
cp slaves.template slaves
cp spark-defaults.conf.template spark-defaults.conf
cp spark-env.sh.template spark-env.sh
spark主要用到的就是上面这3个配置文件,首先编辑slaves配置文件,写入我们的slaves节点如下:
bigdata2
bigdata3
bigdata4
这里就是bigdata2~4,然后继续配置spark-defaults.conf这个默认的配置文件,正常只配置下面的master选项即可:
spark.master spark://bigdata1:7077

其他配置项暂时默认即可,这个配置都是针对于spark任务级别的,比如driver、executor的内存,jvm参数等。
然后配置spark-env.sh,这个是最重要的配置文件,配置全局的spark服务级别的参数,我们这里配置如下:
HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
SPARK_MASTER_HOST=bigdata1
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=8
SPARK_WORKER_MEMORY=7g
#SPARK_WORKER_PORT
SPARK_WORKER_WEBUI_PORT=8081
SPARK_WORKER_DIR=/data/spark/work
SPARK_PID_DIR=/var/run
同样我们来解释一下这些配置项:
HADOOP_CONF_DIR:这个是hadoop配置文件的目录,我这安装的位置是/opt/hadoop所以配置文件应为/opt/hadoop/etc/hadoop,就是配置文件直接所在的目录
SPARK_MASTER_HOST: 这个配置spark master绑定的主机名或ip,注意不是web界面绑定的,而是master服务本身的,我这为bigdata1
SPARK_MASTER_PORT: 配置spark master监听的端口号,默认为7077
SPARK_MASTER_WEBUI_PORT: 配置spark master web ui监听的端口号,默认为8080,当然绑定的主机不用配置,会绑定ipv4和ipv6所有的网卡,这样也方便多网卡环境下,web ui都可以访问到,因此主机名无需配置
SPARK_WORKER_CORES: 配置当前spark worker进程可以使用的核心数,只有worker进程才会读取,默认值为当前机器的物理cpu核数,集群总的可用核数等于每个worker核数的累加
SPARK_WORKER_MEMORY: 这个是配置允许spark应用程序在当前机器上使用的内存总量,也是只有worker才会读取,如果没配置默认值为:总内存-1G,比如我这里机器内存为8G,那么默认值为7G。注意这个配置项是spark的可用内存,而不是限制某个任务,具体任务的限制在spark-defaults.conf中的spark.executor.memory配置项设置
SPARK_WORKER_PORT: 配置worker监听的端口,默认是随机的,这里通常不需要配置,随机选择就好
SPARK_WORKER_WEBUI_PORT: 配置worker webui监听的端口,可以查看worker的状态,默认端口为8081,同样会绑定至所有网卡的ip
SPARK_WORKER_DIR: 这个配置spark运行应用程序的临时目录,包括日志和临时空间,默认值为spark安装目录下的work目录,这里我们配置到专用的数据目录中
SPARK_PID_DIR: 配置spark运行时pid存放的目录,这个默认是在/tmp下,建议修改至/var/run,因为/tmp下的文件长时间不用会被操作系统清理掉,这样会造成spark停止进程时失败的现象,其实就是pid文件找不到的原因
通用的配置大致就是上面这些,另外在启动spark服务时其实也可以指定某些参数或者不同的配置文件,比如我们有多类配置spark-defaults.conf,spark-large.conf等,然后指定不同的配置文件启动也是可以的,具体查看文档参数即可,这里不再详细叙述
现在可以同步spark的配置到其他节点了,由于其他节点还没有spark程序,所以我们将spark程序连同配置一块同步至其他机器的节点:
rsync -av spark-3.0.1-bin-hadoop3.2 bigdata2:/opt/
rsync -av spark-3.0.1-bin-hadoop3.2 bigdata3:/opt/
rsync -av spark-3.0.1-bin-hadoop3.2 bigdata4:/opt/
这里我们安装目录直接是/opt/spark-3.0.1-bin-hadoop3.2,具体配置按照实际的目录来操作即可
2. 启动spark服务
现在我们可以启动spark服务了,可以单独启动也可以批量启动,这里整理常用到的命令如下:
# 单独启动当前节点master
./sbin/start-master.sh
# 单独启动当前节点slave 后面写具体master的配置
./sbin/start-slave.sh spark://bigdata1:7077
# 启动全部的slave节点
./sbin/start-slaves.sh
# 启动全部spark节点服务 包括master和slave
./sbin/start-all.sh # 单独停止当前节点的master
./sbin/stop-master.sh
# 单独停止当前节点的slave 不用加参数
./sbin/stop-slave.sh
# 停止全部的slave
./sbin/stop-slaves.sh
# 停止集群所有的服务 包括master和slave
./sbin/stop-all.sh
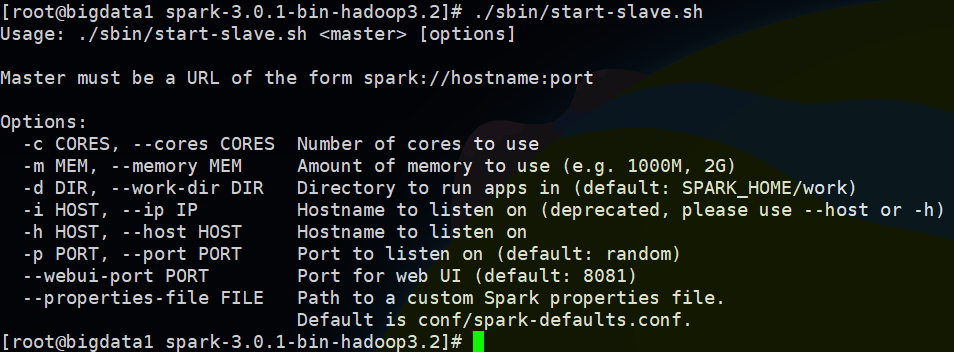
另外slave节点启动的参数可以直接执行 ./sbin/start-slave.sh 不加任何参数查看:
现在在各个节点执行 jps 可以看到master节点上存在Master进程,各slave节点上应该存在Worker进程说明启动成功,可以访问web ui页面查看集群状态:
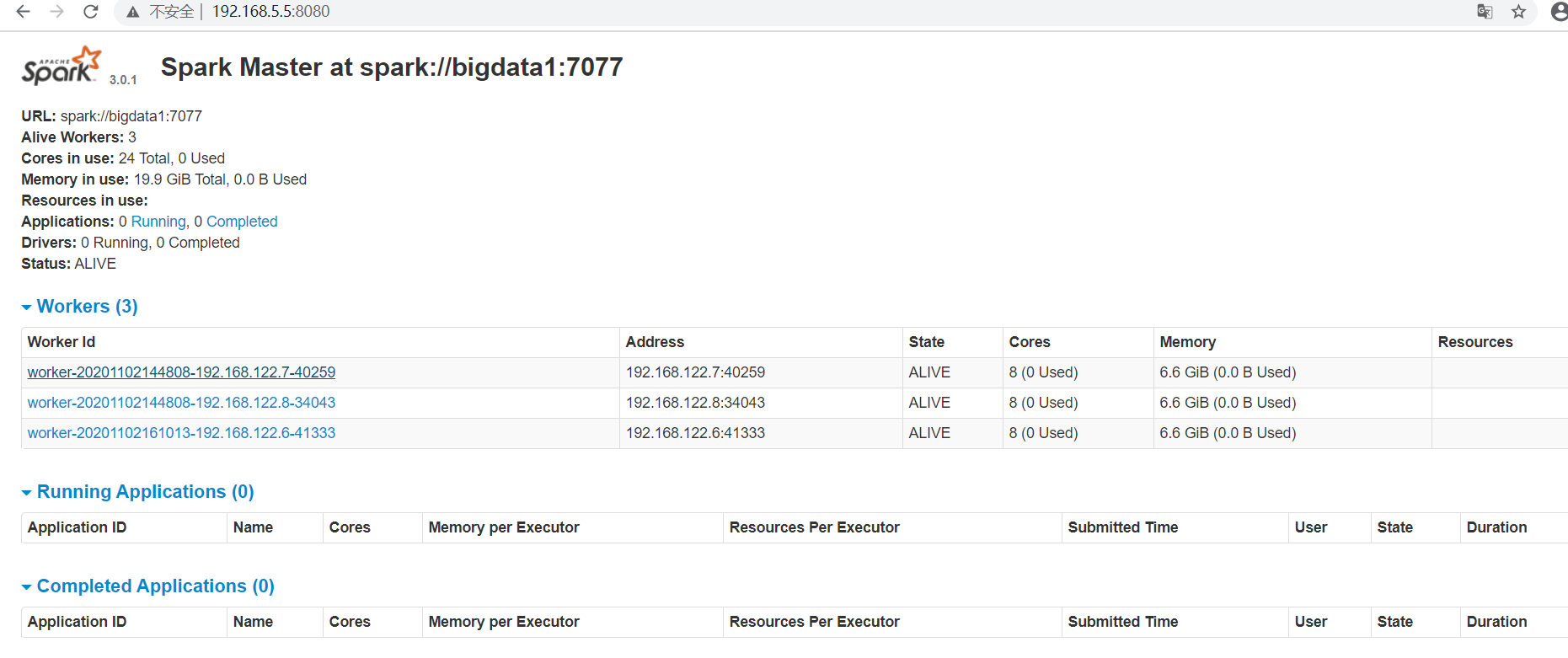
这里可以可以看到集群全部的资源以及每个节点的资源使用情况,之后运行了任务还会看到任务;然后访问每个slave节点的8081还可以看到每个节点上任务的运行情况,具体不再放图片了,这样spark集群就基本上部署成功了。可以尝试进入spark-shell调试应用,运行 ./bin/spark-shell 可以进入:
参考文档:
spark standalone配置项:https://spark.apache.org/docs/latest/spark-standalone.html
配置参数:https://spark.apache.org/docs/latest/configuration.html
以上如有不足,感谢交流指正~
Spark3.0 Standalone模式部署的更多相关文章
- spark 源码编译 standalone 模式部署
本文介绍如何编译 spark 的源码,并且用 standalone 的方式在单机上部署 spark. 步骤如下: 1. 下载 spark 并且解压 本文选择 spark 的最新版本 2.2.0 (20 ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- JBOSS EAP 6.0+ Standalone模式安装成Windows服务
网上有一些文章介绍用JavaService.exe来实现,但是到EAP 6以上版本,我试过好象没成功,幸好JBoss官方已经推出了专门的工具. 一.先到官网下载http://www.jboss.org ...
- Spark3.0.1各种集群模式搭建
对于spark前来围观的小伙伴应该都有所了解,也是现在比较流行的计算框架,基本上是有点规模的公司标配,所以如果有时间也可以补一下短板. 简单来说Spark作为准实时大数据计算引擎,Spark的运行需要 ...
- Spark部署三种方式介绍:YARN模式、Standalone模式、HA模式
参考自:Spark部署三种方式介绍:YARN模式.Standalone模式.HA模式http://www.aboutyun.com/forum.php?mod=viewthread&tid=7 ...
- Flink JobManager HA模式部署(基于Standalone)
参考文章:https://ci.apache.org/projects/flink/flink-docs-release-1.3/setup/jobmanager_high_availability. ...
- Flink部署-standalone模式
Flink部署-standalone模式 2018年11月30日 00:07:41 Xlucas 阅读数:74 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.cs ...
- Spark安装部署(local和standalone模式)
Spark运行的4中模式: Local Standalone Yarn Mesos 一.安装spark前期准备 1.安装java $ sudo tar -zxvf jdk-7u67-linux-x64 ...
- Centos6.3 下使用 Tomcat-6.0.43 非root用户 jsvc模式部署 生产环境 端口80 vsftp
一.安装JDK环境 方法一. 官方下载链接 http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260 ...
- Spark3.0 preview预览版尝试GPU调用(本地模式不支持GPU)
Spark3.0 preview预览版可以下载使用,地址:https://archive.apache.org/dist/spark/spark-3.0.0-preview/,pom.xml也可以进行 ...
随机推荐
- 【5分钟】W10 64bit系统本地安装postgresql 11
1.下载 官网下载地址 2.安装 一路默认,有一个选语言的可以选中chinese simple(中文简体). 3.初始化 1)进入bin: cd C:\Program Files\PostgreS ...
- day04-原生的API&注解方式
原生的API&注解方式 1.MyBatis原生的API调用 1.1原生API快速入门 需求:在前面的项目基础上,使用MyBatis原生的API完成,即直接通过SqlSession接口的方法来完 ...
- iOS端创建ReactNative容器第一步:打出jsbundle和资源包
react-native的打包流程是通过执行react-native bundle指令进行的. 添加构建指令 修改RN项目中的package.json文件,先其中添加构建命令build-relea ...
- RV1126编译过程
一.编译环境 1.目标系统:ubuntu 22.04 LTS 2.投屏器SDK下载: 链接:https://pan.baidu.com/s/1OJQafxm38FnbshMEu432Og 提取码:o6 ...
- 《TencentNCNN系列》 之bin文件(网络参数文件)格式分析
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 视野修炼-技术周刊第73期 | AI 春联生成
欢迎来到第 73 期的[视野修炼 - 技术周刊],下面是本期的精选内容简介 强烈推荐 AI 春联 Vue 10周年啦! 开源工具&技术资讯 2024 你应该知道的几个CSS特性 Vite 5. ...
- 高校刮起元宇宙风!3DCAT实时云渲染助力川轻化元校园建设
元宇宙,是一个虚拟的网络世界,它与现实世界相互连接,为人们提供了一个身临其境的数字体验.元宇宙的概念并不新鲜,早在上个世纪就有科幻作家和电影导演对它进行了想象和创造.但是,随着科技的发展,特别是5G. ...
- uniapp如何给空包进行签名操作
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 首先安装sdk https://www.oracle.com/java/technologies/downloads/ 正常下一步即可~安 ...
- Linunx安装wkhtmltox
1.下载wkhtmltox安装包 官网:https://wkhtmltopdf.org/downloads.html 根据系统类型选择下载wkhtmltox 环境:centos6 32位.wkhtml ...
- HashMap集合的map.values()返回的Collection集合执行add方法报空指针问题
一.方法1. private Collection<String> setPermissionTenant(List<SysPermission> ls, int tenant ...