MRS +Apache Zeppelin,让数据分析更便捷
摘要:选择轻量化、免运维、低成本的大数据云服务是业界趋势,如果搭建Zeppelin再同步自建一套Hadoop生态成本太高!因此我们通过结合华为云MRS服务构建数据中台。
本文分享自华为云社区《MRS大数据平台结合Apache Zeppelin让数据分析更便捷》,作者: dullman。
Apache Zeppelin:一款大数据分析和可视化工具,可以让数据分析师在一个基于Web的notebook中,采用不同语言对不同数据源中的数据进行交互式分析,并对结果进行可视化图表的展示。
云服务MRS:华为云提供的一站式大数据平台,包含Hudi、ClickHouse、Spark、Flink、Kafka、Hive、HBase等丰富的大数据组件,完全兼容开源生态。 本文介绍如何搭建Zeppelin并连接Hive、HBase进行简单的数据开发。
为什么写这篇文章?
- Zeppelin相关的文章虽然很多,但是都没有与实际大数据平台结合的实践案例指导。
- Zeppelin的搭建存在不少坑,因此记录下部署中的各个问题,为后人填坑。
- 选择轻量化、免运维、低成本的大数据云服务是业界趋势,如果搭建Zeppelin再同步自建一套Hadoop生态成本太高!因此我们通过结合华为云MRS服务构建数据中台。
环境准备
- Apache Zeppelin 0.9.0安装包
- MRS 3.1.0普通集群 (包含Hive、HBase组件)
- ECS centos7.6
安装MRS客户端
MRS客户端提供java、python开发环境,也提供开通集群中各组件的环境变量:Hadoop、Hive、HBase、flink等。
参见登录ECS安装集群外客户端
安装Zeppelin
- 使用Xftp等工具导入主机并采用以下命令安装在/opt/zeppelin目录。
tar -zxvf zeppelin-0.9.0-bin-all.tgz
mv zeppelin-0.9.0-bin-all /opt/zeppelin
- 配置Zeppelin环境变量,在profile文件中加入变量
vi /etc/profile
export ZEPPELIN_HOME=/opt/zeppelin
export PATH=ZEPPELIN_HOME/bin:ZEPPELINHOME/bin:PATH
- 导入环境变量
source /etc/profile
- 编辑zeppelin-env.sh文件,加入JAVA_HOME,这里需要替换成自己的环境变量
cd /opt/zeppelin/conf/
cp zeppelin-env.sh.template zeppelin-env.sh
source /opt/hadoopclient/bigdata_env
echo “export JAVA_HOME=/opt/hadoopclient/JDK/jdk-8u201”>>zeppelin-env.sh
- 编辑zeppelin-site.xml文件,将zeppelin.server.port 8080替换成18081(可自定义,也可以不改);将zeppelin.anonymous.allowed参数的true修改为false
cd /opt/zeppelin/conf
cp zeppelin-site.xml.template zeppelin-site.xml
vi zeppelin-site.xml
<property>
<name>zeppelin.server.port</name>
<value>18081</value>
<description>Server port.</description>
</property>
<property>
<name>zeppelin.anonymous.allowed</name>
<value>falase</value>
<description>Anonymous user allowed by default</description>
</property>
- 编辑shiro.ini文件,新增用户developuser
cp shiro.ini.template shiro.ini
vi shiro.ini
在[users]下新增用户developuser,密码Huawei@123,权限admin
developuser=Huawei@123, admin

- 运行Zeppelin(并检查启动参数)
cd /opt/zeppelin
bin/zeppelin-daemon.sh start

ps ef | grep zeppelin
- 关闭防火墙,允许端口18081(此为测试环境,生产环境建议采取更安全措施) systtemctl stop firewalld
- 完成以上配置,并启动成功后,在浏览器中输入地址zeppelin_ip:18081(zeppelin_ip为安装zeppelin的HD客户端IP),即可看到如下界面。

- 使用developuser登录,就可以基于note进行大数据的交互式开发了!
Zeppelin连接Hive
1、将Zeppelin中jdbc依赖的jar包替换成MRS客户端中Hive/Beeline/lib中的jar包,保证hive Interpreter依赖的Jar包存在
cp -f /opt/Bigdata/client/Hive/Beeline/lib/*.jar /opt/zeppelin/interpreter/jdbc/
2、修改Zeppelin配置,添加Client Hive Url
查询CLIENT_HIVE_URL
source /opt/hadoopclient/bigdata_env
echo $CLIENT_HIVE_URI
编辑interpreter.json,位置/usr/zeppelin/conf/interpreter.json,修改JDBC default.url,default.driver.
"jdbc": {
"id": "jdbc",
"name": "jdbc",
"group": "jdbc",
"properties": {
"default.url": {
"name": "default.url",
"value": "jdbc:hive2://192.168.1.188:24002,192.168.1.234:24002,192.168.1.241:24002/;serviceDiscoveryMode\u003dzooKeeper;zooKeeperNamespace\u003dhiveserver2",
"type": "string",
"description": "The URL for JDBC."
},
"default.user": {
"name": "default.user",
"value": "gpadmin",
"type": "string",
"description": "The JDBC user name"
},
"default.password": {
"name": "default.password",
"value": "",
"type": "password",
"description": "The JDBC user password"
},
"default.driver": {
"name": "default.driver",
"value": "org.apache.hive.jdbc.HiveDriver",
"type": "string",
"description": "JDBC Driver Name"
}
3、重启zeppelin
bin/zeppelin-daemon.sh restart
4、创建Notebook,选择default interpreter 为jdbc
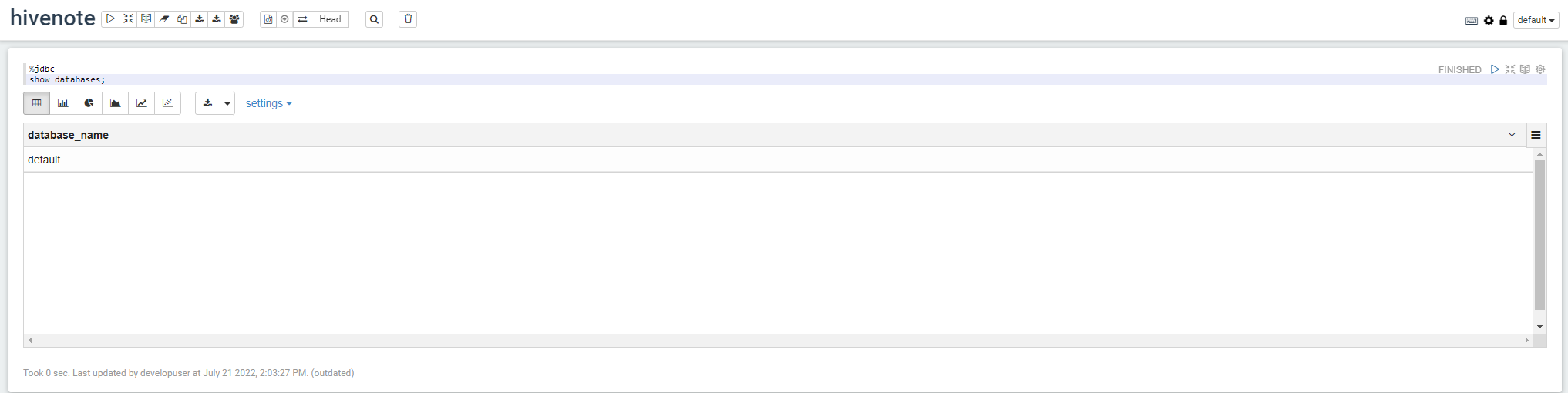
5、在notebook上使用Hive SQL进行查询
查询数据库
%jdbc
show databases;
创建Hive表
%jdbc
create external table stu (s_id string,s_name string) row format delimited fields terminated by ‘\t’;

Zeppelin连接HBase
1、将Zeppelin中hbase依赖的jar包替换成MRS客户端中HBase中的jar包,保持jar的一致
- 先将/opt/zeppelin/interpreter/hbase/目录下原本的Jar包移走
cd /opt/zeppelin/interpreter/hbase
mkdir hbase_old_jar
mv hbase*.jar hbase_old_jar
mv hadoop*.jar hbase_old_jar
mv zookeeper-3.4.6.jar hbase_old_jar
- 再将/opt/hadoopclient/HBase/hbase/lib/下的jar包拷贝至/opt/zeppelin/interpreter/hbase/。
cp -f /opt/hadoopclient/HBase/hbase/lib/*.jar /usr/zeppelin/interpreter/hbase/
2、修改Zeppelin配置
编辑zeppelin-env.sh,加入hbase环境变量
export HBASE_HOME=/opt/hadoopclient/HBase/hbase
编辑interpreter.json,位置/opt/zeppelin/conf/interpreter.json,修改hbase.home
"hbase.home": {
"name": "hbase.home",
"value": "/opt/hadoopclient/HBase/hbase",
"type": "string"
}
3、重启zeppelin
bin/zeppelin-daemon.sh restart

4、配置Interpreter
从web界面右上角菜单中Interpreter中进入,配置Interpreter
选择Hbase,修改如下配置,并保存配置。
hbase.home : /opt/client/HBase/hbase
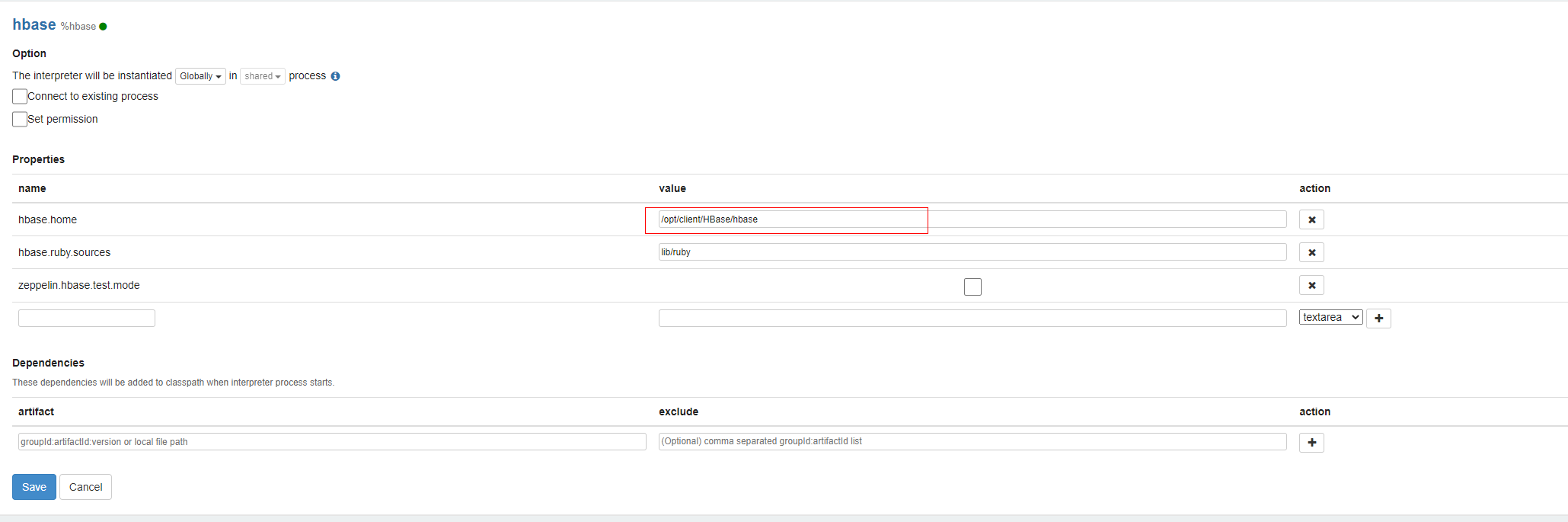
5、创建note进行数据开发
页面选择Notebook →create new note
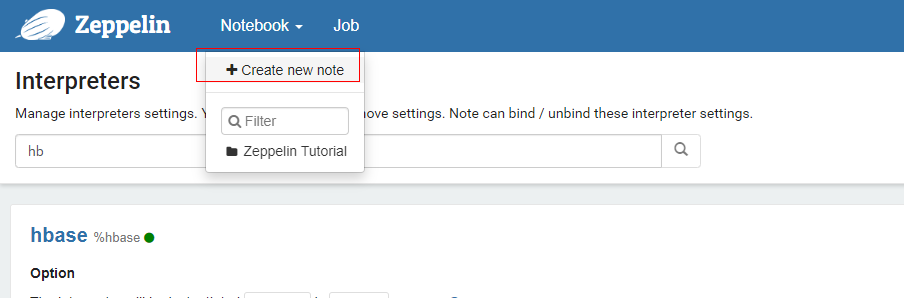
自定义Note名称,例如hbaseNote,并指定Interpreter为HBase。
编辑Note,点击右侧“执行”按钮(三角标志)
%hbase
create ‘test6’, ‘cf’
put ‘test6’, ‘row1’, ‘cf:a’, ‘value1’
若在创建Interpreter未指定default Interpreter,需要在note最前面加上%hbase进行指定。
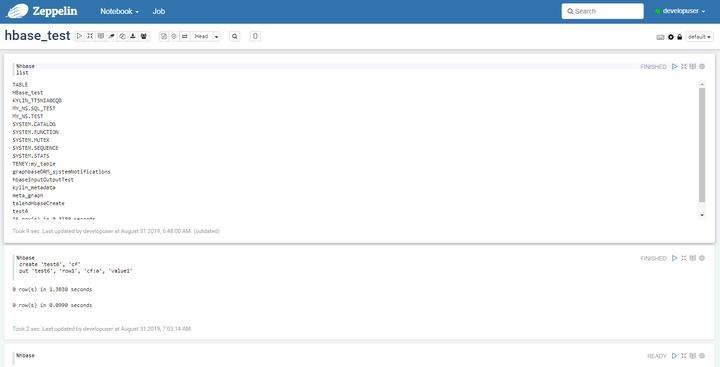
6、在FusionInsight客户端下查看刚刚通过Zeppelin创建的hbase表test6和数据

其他Hadoop生态组件在云服务MRS上的实践参考
基于云服务MRS构建DolphinScheduler2调度系统
MRS +Apache Zeppelin,让数据分析更便捷的更多相关文章
- Apache Hudi集成Apache Zeppelin实战
1. 简介 Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本.方便你做出可数据驱动的.可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spa ...
- Apache Zeppelin
介绍 用于做数据分析和可视化 一.二进制安装 1)下载二进制包 wget http://mirrors.tuna.tsinghua.edu.cn/apache/incubator/zeppelin/0 ...
- Apache Zeppelin是什么?
Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化.背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持scala ...
- 微信公众平台自定义菜单新增扫一扫、发图片、发位置 LBS运作更便捷
今天微信公众平台发布更新,自定义菜单新增扫一扫.发图片.发送位置等功能,这对于有意挖掘微信LBS服务的运营者来说更便捷了,订阅号不用返回微信界面就能扫图.发送图片.调用地理位置,用户体验更友好,自然也 ...
- 更便捷的css处理方式-postcss
更便捷的css处理方式-PostCSS 一般来说介绍一个东西都是要从是什么,怎么用的顺序来讲.我感觉这样很容易让大家失去兴趣,先看一下postcss能做点什么,有兴趣的话再往下看,否则可能没有耐心看下 ...
- Android源码浅析(三)——Android AOSP 5.1.1源码的同步sync和编译make,搭建Samba服务器进行更便捷的烧录刷机
Android源码浅析(三)--Android AOSP 5.1.1源码的同步sync和编译make,搭建Samba服务器进行更便捷的烧录刷机 最近比较忙,而且又要维护自己的博客,视频和公众号,也就没 ...
- 使用Zeppelin时出现at org.apache.zeppelin.interpreter.thrift.RemoteInterpreterService$Client.recv_getFormType(RemoteInterpreterService.java:288)错误的解决办法(图文详解)
不多说,直接上干货! 问题详解 org.apache.thrift.TApplicationException: Internal error processing getFormType at or ...
- 更便捷的Mybatis增强插件——EasyMybatis
easy-mybatis是一个对Mybatis的增强框架(插件).在Spring集成Mybatis的基础上,将项目开发中对数据库的常用操作统一化.使用本框架可以很便捷的对数据库进行操作,提高开发效率, ...
- HarmonyOS新能力让数据多端协同更便捷,数据跨端迁移更高效!
作者:yijian,终端OS分布式文件系统专家:gongashi,终端OS分布式数据管理专家 HarmonyOS作为分布式操作系统,其分布式数据管理能力非常重要.我们也一直围绕持续为开发者带来全局&q ...
- Exception in thread "main" java.lang.UnsupportedClassVersionError: org/apache/zeppelin/server/ZeppelinServer : Unsupported major.minor version 52.0
在启动Zeppelin时遇到了该问题: [root@quickstart bin]# ./zeppelin-daemon.sh restart Please specify HADOOP_CONF_D ...
随机推荐
- mysql语句操作
1.从login表中选出name字段包含admin的前10条结果所有信息的sql语句 select * from login where name like %admin% limit 0 ,10; ...
- 更改Kali Linux系统语言以及安装zenmap
更改Kali Linux系统语言以及安装zenmap 在使用kali的过程中,会遇到许多问题,其中一个就是看不懂英语,下面是如何更换语言的步骤. 更改Kali Linux系统语言 首先,打开kali, ...
- 关于react提问以及解答
1. 请教个工程问题. 团队运用webpack打包前端代码,转译后的文件每次都需要push到代码库远端:从开发角度而言,是不希望这部分代码在代码库的:两个原因:1是不方便代码review,2是代码仓库 ...
- Grafana新手教程-实现仪表盘创建和告警推送
前言 最近在使用Grafana的时候,发现Grafana功能比想象中要强大,除了配合Prometheus使用之外,他自身都可以做很多事情,可视化和监控平台,还可以直接根据用户自定义的告警规则完成告警和 ...
- Modbus转Profinet--TS-180 网关连接西门子 PLC 和工业称重仪表
项目 随着科技的高速发展,工业自动化行业对日益多样的称重需求越来越高,上海某公司在国内的一个 工业自动化项目中,监控中心系统需要远程实时采集工业称重仪表测量的各种称重参数.该系统使用的是 西门子 S7 ...
- Vue01-简介与入门
Vue 01. 简介 1.1 前端三大框架 目前前端最流行的三大框架: Vue React angular 1.2 Vue简介 Vue (读音 /vjuː/,类似于 view) ,也可以写成Vue.j ...
- Hnswlib 介绍与入门使用
Hnswlib是一个强大的近邻搜索(ANN)库, 官方介绍 Header-only C++ HNSW implementation with python bindings, insertions a ...
- 手把手教你用python做一个年会抽奖系统
引言 马上就要举行年会抽奖了,我们都不知道是否有人能够中奖.我觉得无聊的时候可以尝试自己写一个抽奖系统,主要是为了娱乐.现在人工智能这么方便,写一个简单的代码不是一件困难的事情.今天我想和大家一起构建 ...
- 华企盾DSC导致金蝶导入Excel导入不了的问题
需要把Excel的OLE控制关掉,并且金蝶的进程和Excel的进程高级设置要么都启用重定向,要么都不启用重定向
- NetSuite 开发日记:SDF 基础指南
VS Code 使用 SDF SuiteCloud : Create Project SuiteCloud : Set Up Account (连接沙盒环境) SuiteCloud : Import ...