Python 爬取 北京市政府首都之窗信件列表-[数据处理]
日期:2020.01.24
博客期:132
星期五
【代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明】
//博客总体说明
1、准备工作
2、爬取工作
3、数据处理(本期博客)
4、信息展示
好了今天是除夕,先给大家说句吉利话,“祝大家打代码代代顺利,码码成功”!我因为回家了,今天没做太多东西... ...呼~
登录虚拟机,启动hadoop和hive,准备做数据处理部分!
//建数据库的语句
create table govdata(
kind string,
asker string,
responser string,
asktime string,
responsetime string,
title string,
questionSupport int,
responseSupport string,
responseUnsupport string,
questiontext string,
responsetext string
) row format delimited
fields terminated by '\t';
处理如下:

之后通过文件导入数据(以"\t"为分隔符进行数据导入):
//从路径为"/data/edu3/govdata"的文件导入数据
load data local inpath '/data/edu3/govdata' into table govdata;
处理如下:

之后对应需求部分的处理正在进行
下面是对数据库的测试:

之后使用文件导入方式导入到mysql (因为是以\t为分隔符所以对应以下代码)
LOAD DATA INFILE
'E:\\课件\\3-2\\大数据\\大三寒假作业\\2020-01-23\\datas.txt'
INTO TABLE govdata
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
导入以后分别使用sql语句去建立三个需求的表:
CREATE table kinddata
As
(
select
kind as kind,
count(1) as num
from govdata
group by kind
order by num desc
); CREATE table yeardata
AS
(
select
SUBSTRING(asktime,1,4) as dt,
count(*) as num
from govdata
group by dt
)
; CREATE table responserdata
AS
(
select
gd.responser as responser,
count(*) as num
from govdata gd
group by responser
order by num desc
);
得到数据表(可以提供制作网页的数据):

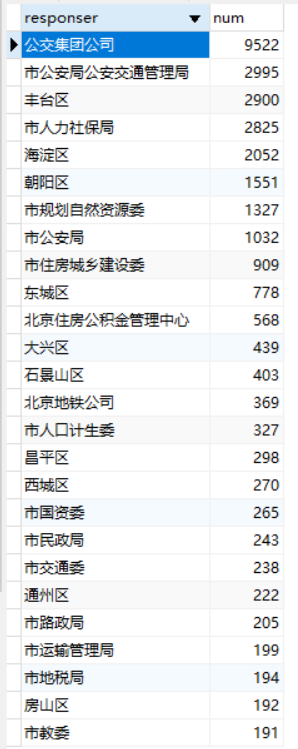

这分别对应的是每年的信件量,回答方对应的信件数,和不同类型的信件数
Python 爬取 北京市政府首都之窗信件列表-[数据处理]的更多相关文章
- Python 爬取 北京市政府首都之窗信件列表-[Scrapy框架](2020年寒假小目标04)
日期:2020.01.22 博客期:130 星期三 [代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明] //博客总体说明 1.准备工作(本期博客) 2.爬取工作 3.数据处理 4.信息展 ...
- Python 爬取 北京市政府首都之窗信件列表-[后续补充]
日期:2020.01.23 博客期:131 星期四 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] //博客总体说明 1.准备工作 2.爬取工作(本期博客) 3.数据处理 ...
- Python 爬取 北京市政府首都之窗信件列表-[信息展示]
日期:2020.01.25 博客期:133 星期六 [代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明] //博客总体说明 1.准备工作 2.爬取工作 3.数据处理 4.信息展示(本期博客 ...
- python爬取北京政府信件信息01
python爬取,找到目标地址,开始研究网页代码格式,于是就开始根据之前学的知识进行爬取,出师不利啊,一开始爬取就出现了个问题,这是之前是没有遇到过的,明明地址没问题,就是显示网页不存在,于是就在百度 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
随机推荐
- FULL OUTER JOIN
FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行. SELECT Web.name, access.count, access.dat ...
- Jmeter_正则表达式提取器_提取单组数据
1.用处:提取登录信息/获取session或者token数值 2.举例:获取登录结果的获取:msg":"登录成功" 这个数据 3.HTTP->后置处理器->正 ...
- 【PAT甲级】1097 Deduplication on a Linked List (25 分)
题意: 输入一个地址和一个正整数N(<=100000),接着输入N行每行包括一个五位数的地址和一个结点的值以及下一个结点的地址.输出除去具有相同绝对值的结点的链表以及被除去的链表(由被除去的结点 ...
- 【PAT甲级】1089 Insert or Merge (25 分)(插入排序和归并排序)
题意: 输入一个正整数N(<=100),接着输入两行N个整数,第一行表示初始序列,第二行表示经过一定程度的排序后的序列.输出这个序列是由插入排序或者归并排序得到的,并且下一行输出经过再一次排序操 ...
- NAT穿透的详细讲解及分析
原文地址:http://bbs.pediy.com/thread-131961.htm 一.什么是NAT?为什么要使用NAT?NAT是将私有地址转换为合法IP地址的技术,通俗的讲就是将内网与内网通信时 ...
- angular9 学习笔记
前言: AngularJS作为Angular的最早版本,2010年发布其初始版本,至今已经10年了.除了这个最初版本(没学过),项目上一直从2.x 到至今项目使用8.x版本,现在Angular在201 ...
- git 使用点
git checkout HEAD 只是缓存恢复到head 头版本,文件还没恢复,最后要执行 git checkout . (点) 才能恢复文件内容 git checkout 只是 ...
- 转专业后补修C语言的一些体会(3)
1.指针:指针是C语言最为强大的工具之一,有着很多优点,比如可以改善子程序的效率,为动态数据结构提供支持,为C的动态内存分配系统提供支持,为函数提供修改变量值的手段.但指针的使用十分困难.会出现很多意 ...
- leetcode 0208
目录 ✅ 108. 将有序数组转换为二叉搜索树 描述 解答 py [tdo rev 0208]py知识:if not x: 和if x is not None:和if not x is None:使用 ...
- Nginx+Openssl实现HTTPs(重点)
[root@localhost ~]# rz -E //导入jdk源码包 z waiting to receive.**B0100000023 ...