[Spark内核] 第28课:Spark天堂之门解密
本課主題
- 什么是 Spark 的天堂之门
- Spark 天堂之门到底在那里
- Spark 天堂之门源码鉴赏
引言
我说的 Spark 天堂之门就是SparkContext,这篇文章会从 SparkContext 创建3大核心对象 TaskSchedulerImpl、DAGScheduler 和 SchedulerBackend 开始到注册给 Master 这个过程中的源码鉴赏,SparkContext 是整个 Spark 程序通往集群的唯一通道,它是程序起点,也是程序终点,所以我把它称之为天堂之门,看过 Spark HelloWorld 程序的朋友都知道,你在程序的开头必需先定义SparkContext、接著调用 SparkContext 的方法,比如说 sc.textFile(file),最后也会调用 sc.stop( ) 来退出应用程序。现在我们就来看看 SparkContext 里面到底有什么密码,以及为什么它会被称为天堂之门。希望这篇文章能为读者带出以下的启发:
- 了解在 SparkContext 内部创建了那些实例对象以及如何创建
- 了解真正是那个实例对象向 Master 注册以及如何注册
什么是 Spark 的天堂之门
- Spark 程序在运行的时候分为 Driver 和 Executor 两部分
- Spark 程序编写是基于 SparkContext 的,具体来说包含两方面
- Spark 编程的核心 基础-RDD 是由 SparkContext 来最初创建的(第一个RDD一定是由 SparkContext 来创建的)
- Spark 程序的调度优化也是基于 SparkContext,首先进行调度优化。
- Spark 程序的注册时通过 SparkContext 实例化时候生产的对象来完成的(其实是 SchedulerBackend 来注册程序)
- Spark 程序在运行的时候要通过 Cluster Manager 获取具体的计算资源,计算资源获取也是通过 SparkContext 产生的对象来申请的(其实是 SchedulerBackend 来获取计算资源的)
- SparkContext 崩溃或者结束的时候整个 Spark 程序也结束啦!
Spark 天堂之门到底在那里
运行一个程序,你会看见 SparkContext 从程序开始到结束都有它的身影,SparkContext 是 Spark 应用程序的核心呀!
[下图是一个 HelloWord 应用程序在 IDEA 中的运行状况]
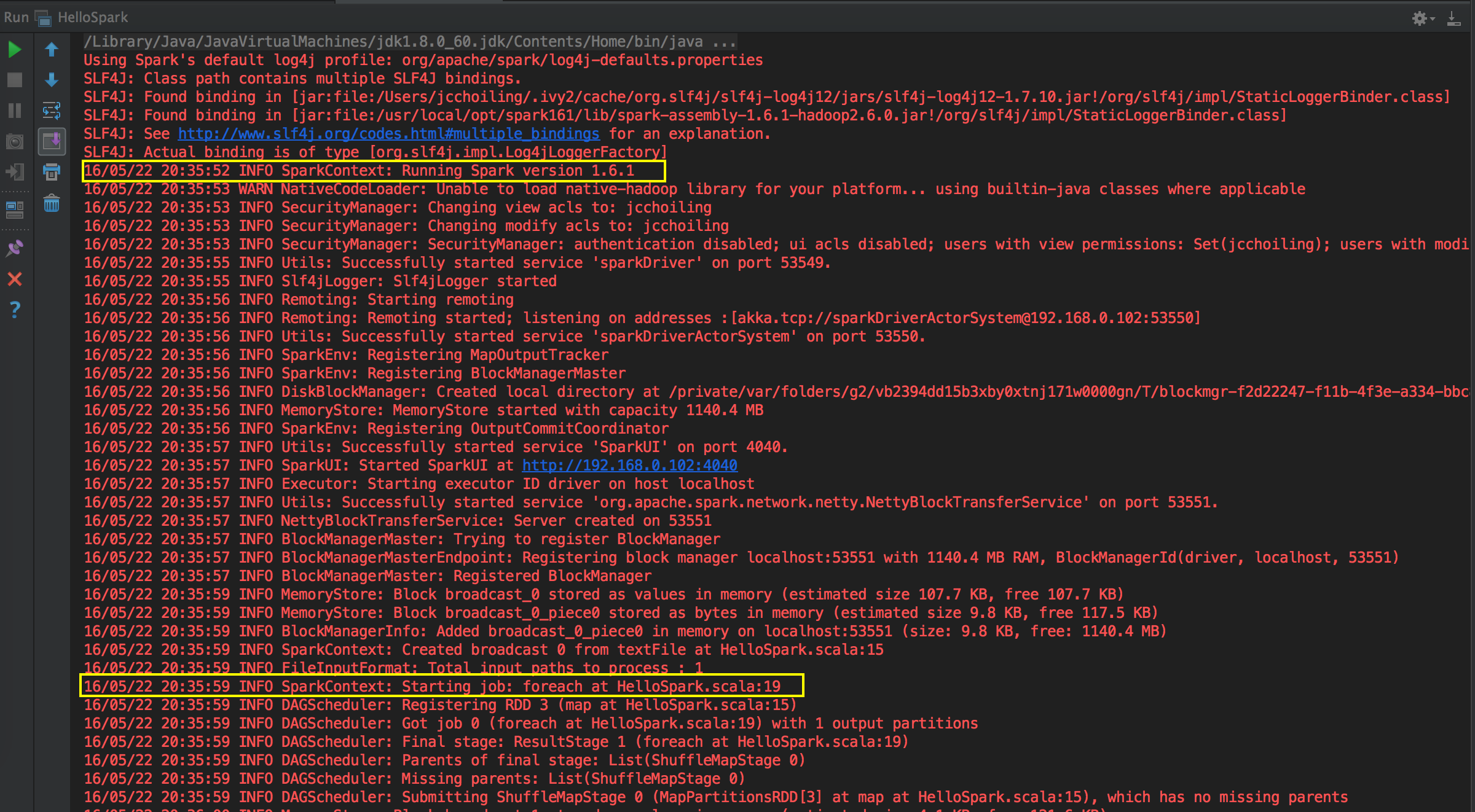
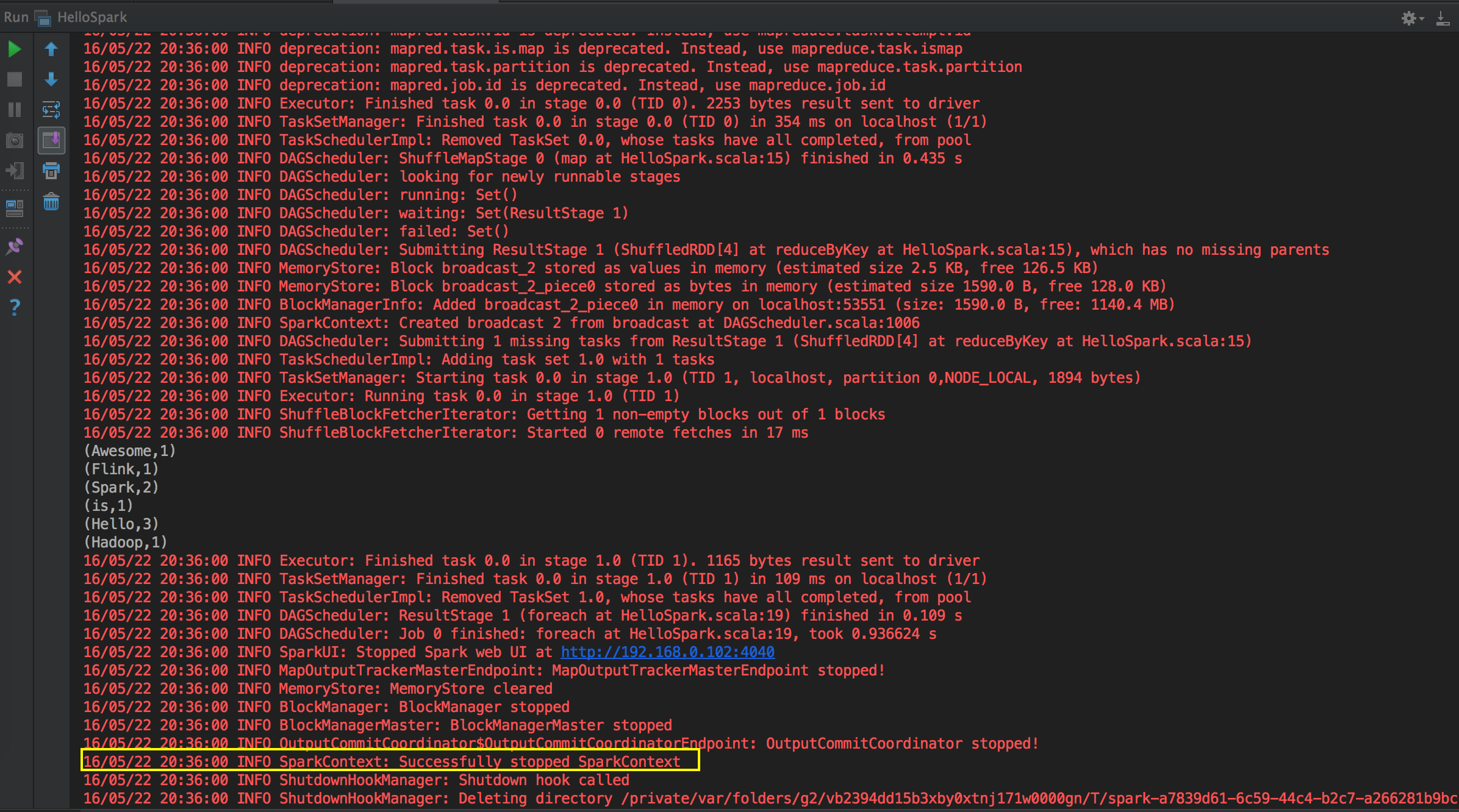
Spark 天堂之门源码鉴赏
这次主要是看当提交Spark程序后,在 SparkContext 实例化的过程中,里面会创建多少个核心实例来为应用程序完成注冊,SparkContext 最主要的是实例化 TaskSchedulerImpl。
[下图是 SparkContext 在创建核心对象后的流程图]
- SparkContext 構建的頂級三大核心:DAGScheduler, TaskScheduler, SchedulerBackend,其中:
- DAGScheduler 是面向 Job 的 Stage 的高層調度器;
- TaskScheduler 是一個接口,是低層調度器,根據具體的 ClusterManager 的不同會有不同的實現,Standalone 模式下具體的實現 TaskSchedulerImpl;
- SchedulerBackend 是一個接口,根據具體的 ClusterManager 的不同會有不同的實現,Standalone 模式下具體的實現是SparkDeploySchedulerBackend
- 從整個程序運行的角度來講,SparkContext 包含四大核心對象:DAGScheduler, TaskScheduler, SchedulerBackend, MapOutputTrackerMaster
- SparkDeploySchedulerBackend 有三大核心功能:
- 負責與 Master 連接注冊當前程序 RegisterWithMaster
- 接收集群中為當前應用程序而分配的計算資源 Executor 的注冊並管理 Executors;
- 負責發送 Task 到具體的 Executor 執行
補充說明的是 SparkDeploySchedulerBackend 是被 TaskSchedulerImpl 來管理的!
- 程序一开始运行时会实例化 SparkContext 里的东西,所以不在方法里的成员都会被实例化!一开始实例化的时候第一个关键的代码是 createTaskScheduler,它是位于 SparkContext 的 Primary Constructor 中,当它实例化时会直接被调用,这个方法返回的是 taskScheduler 和 dagScheduler 的实例,然后基于这个内容又构建了 DAGScheduler,然后调用 taskScheduler 的 start( ) 方法,要先创建taskScheduler然后再创建 dagScheduler,因为taskScheduler是受dagScheduler管理的。
[下图是 SparkContext.scala 中的创建 schedulerBackend 和 taskSchdulerImpl 的实例对象]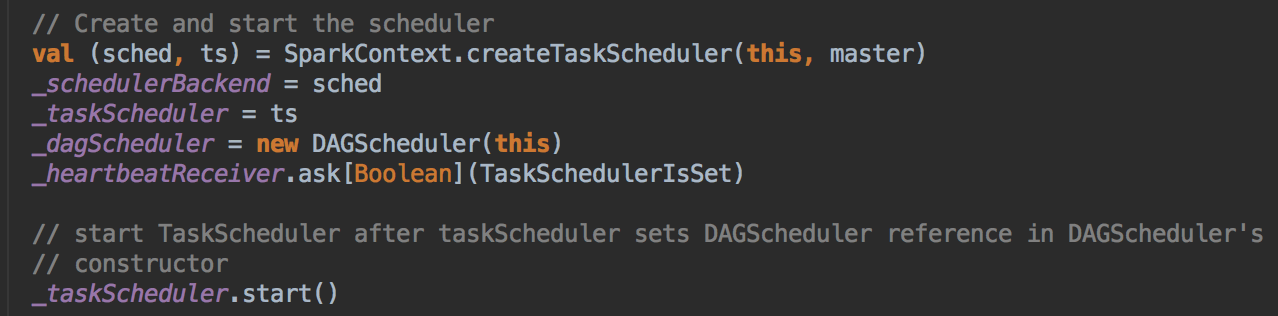
- 调用 createTaskSchedule,这个方法创建了 TaskSchdulerImpl 和 SparkDeploySchedulerBackend,接受第一个参数是 SparkContext 对象本身,然后是字符串,(这也是你平时转入 master 里的字符串)
[下图是 HelloSpark.scala 中创建 SparkConf 和 SparkContext 的上下文信息]
[下图是 SparkContext.scala 中的 createTaskScheduler 方法]
- 它会判断一下你的 master 是什么然后具体进行不同的操作!假设我们是Spark 集群模式,它会:
[下图是 SparkContext.scala 中的 SparkMasterRegex 静态对象]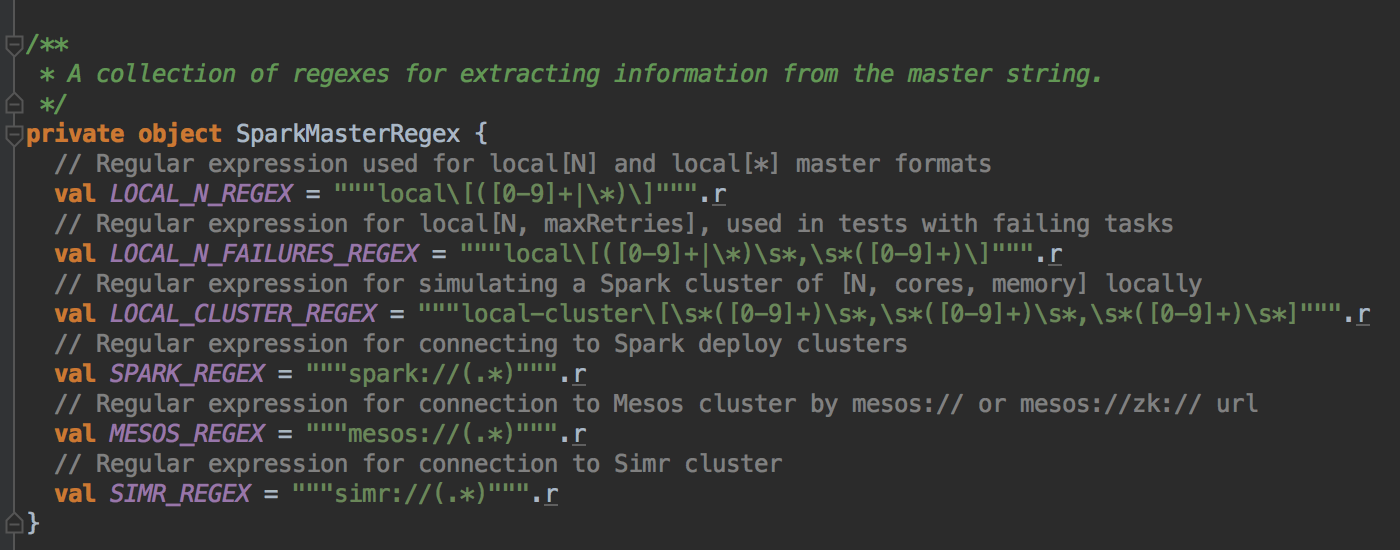
- 创建 TaskSchedulerImpl 实例然后把 SparkContext 传进去;
- 匹配集群中 master 的地址 e.g. spark://
- 创建 SparkDeploySchedulerBackend 实例,然后把 taskScheduler (这里是 TaskSchedulerImpl)、SparkContext 和 master 地址信息传进去;
- 调用 taskScheduler (这里是 TaskSchedulerImpl) 的 initialize 方法 最后返回 (SparkDeploySchedulerBackend, TaskSchedulerImpl) 的实例对象
- SparkDeploySchedulerBackend 是被 TaskSchedulerImpl 來管理的,所以这里要首先把 scheduler 创建,然后把 scheduler 的实例传进去。
[下图是 SparkContext.scala 中的调用模式匹配 SPARK_REGEX 的处理逻辑]
- Task 默认失败后重新启动次数为 4 次
[下图是 TaskSchedulerImpl.scala 中的类和主构造器的调用方法]
TaskSchedulerImpl.initialize( )方法是
- 创建一个 Pool 来初定义资源分布的模式 Scheduling Mode,默认是先进先出的 模式。

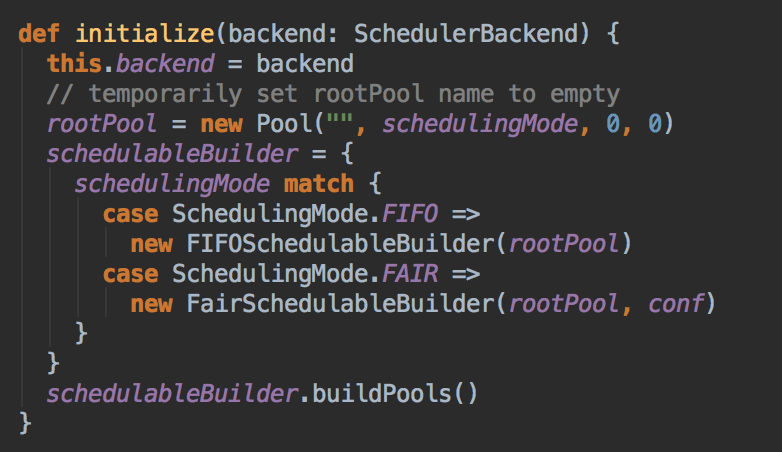
调用 taskScheduler 的 start( ) 方法
- 在这个方法中再调用 backend (SparkDeploySchedulerBackend) 的 start( ) 方法。
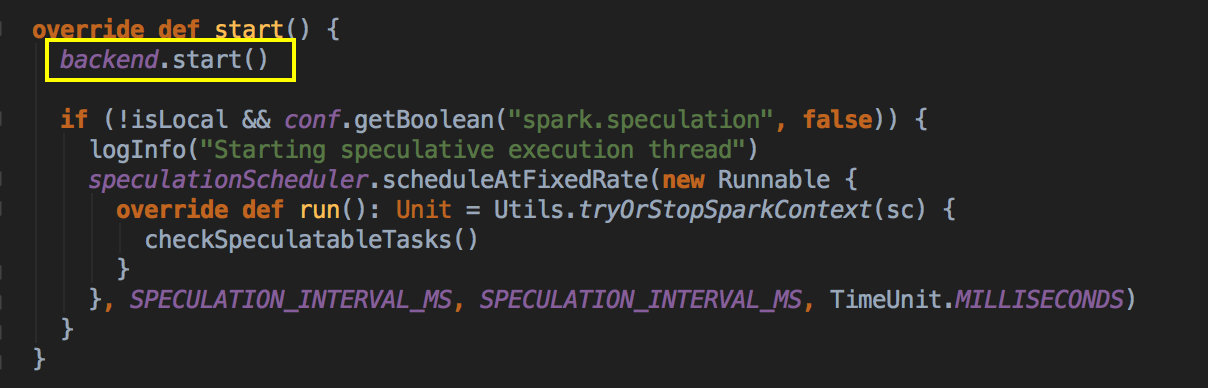

- 當通過 SparkDeploySchedulerBackend 注冊程序給 Master 的時候會把以上的 command 提交給 Master
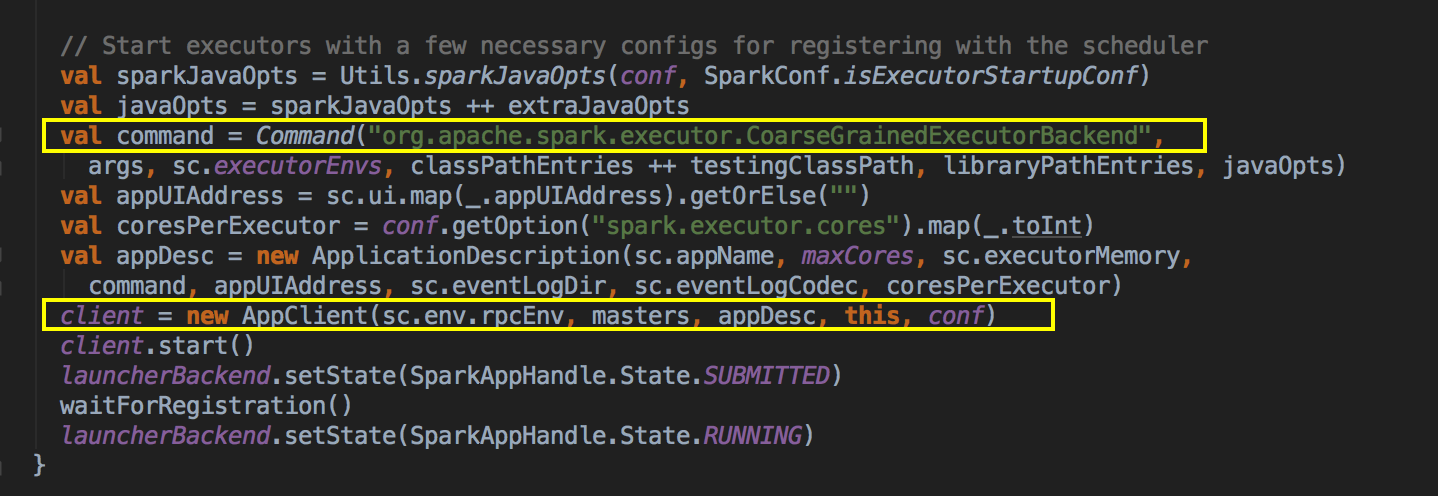
- Master 發指令給 Worker 去啟動 Executor 所有的進程的時候加載的 Main 方法所在的入口類就是 command 中的 CoarseGrainedExecutorBackend,當然你可以實現自己的 ExecutorBackend,在 CoarseGrainedExecutorBackend 中啟動 Executor (Executor 是先注冊再實例化),Executor 通過线程池並發執行 Task。
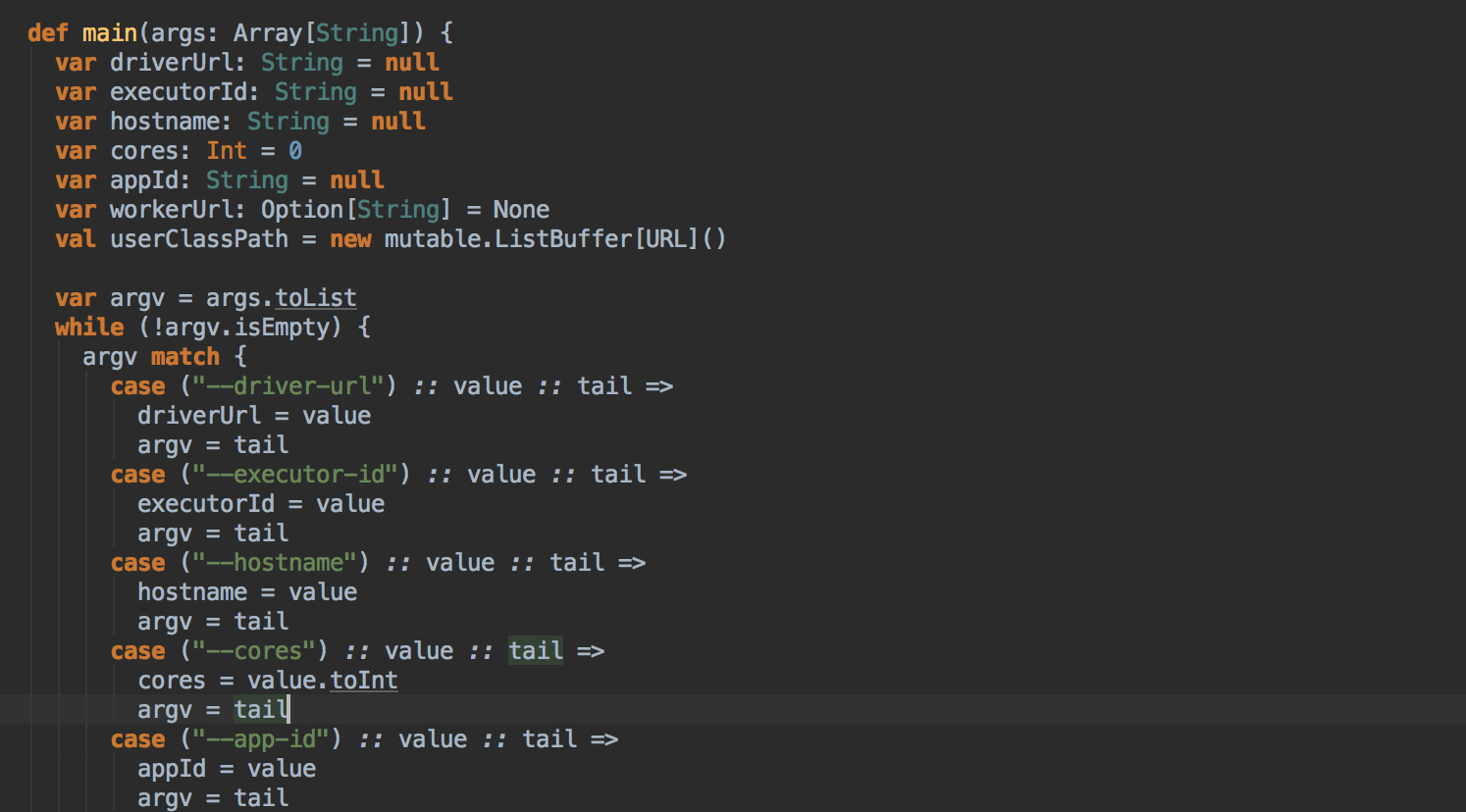
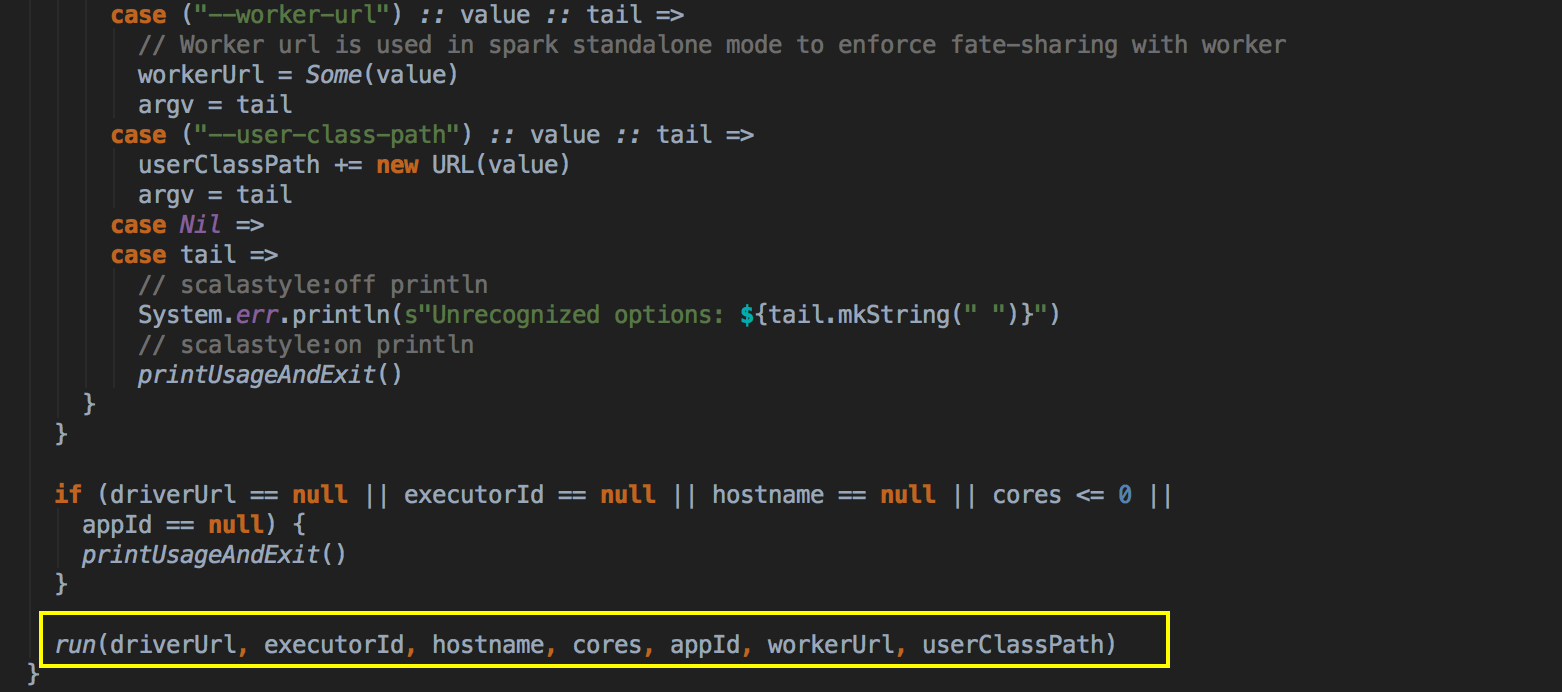
- 这里调用了它的 run 方法
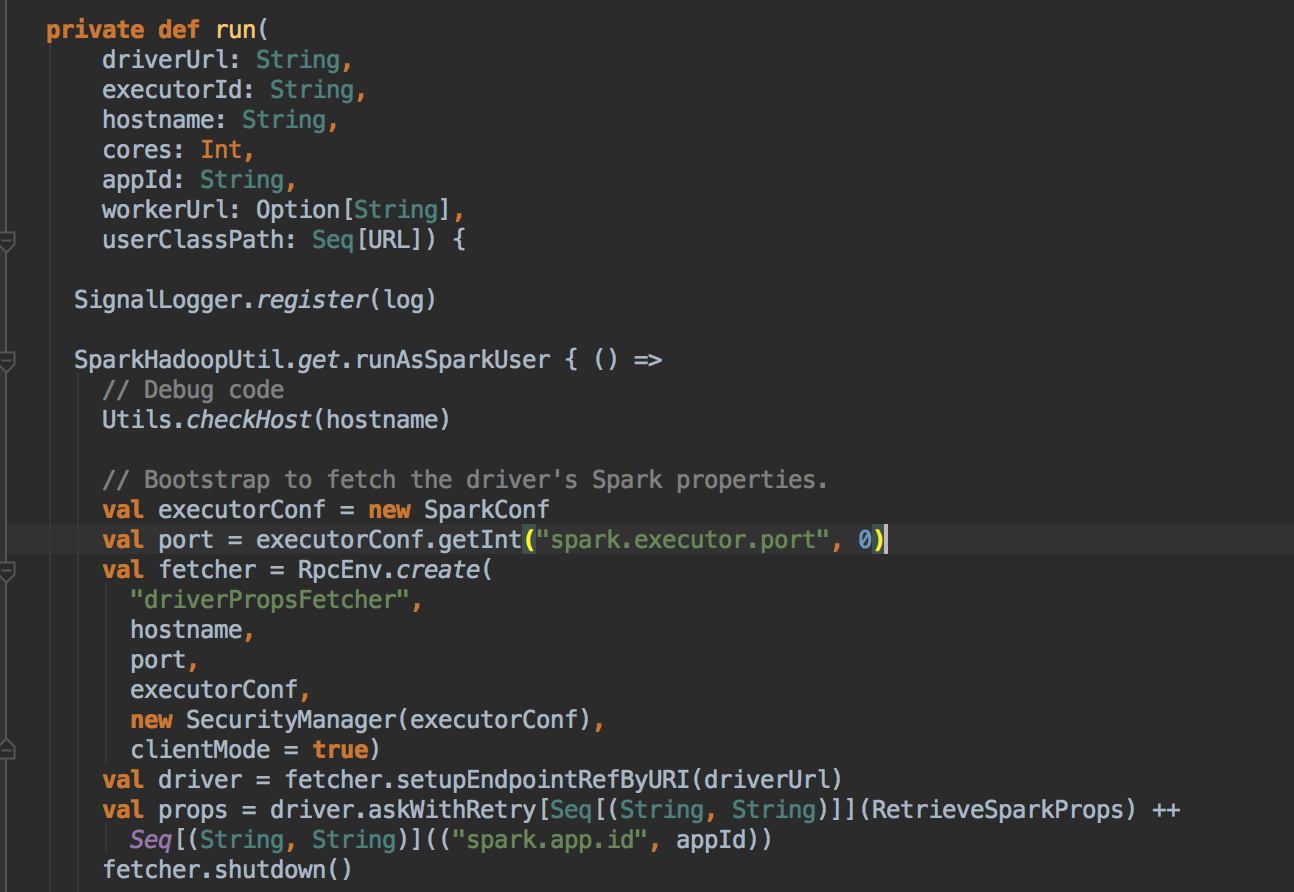
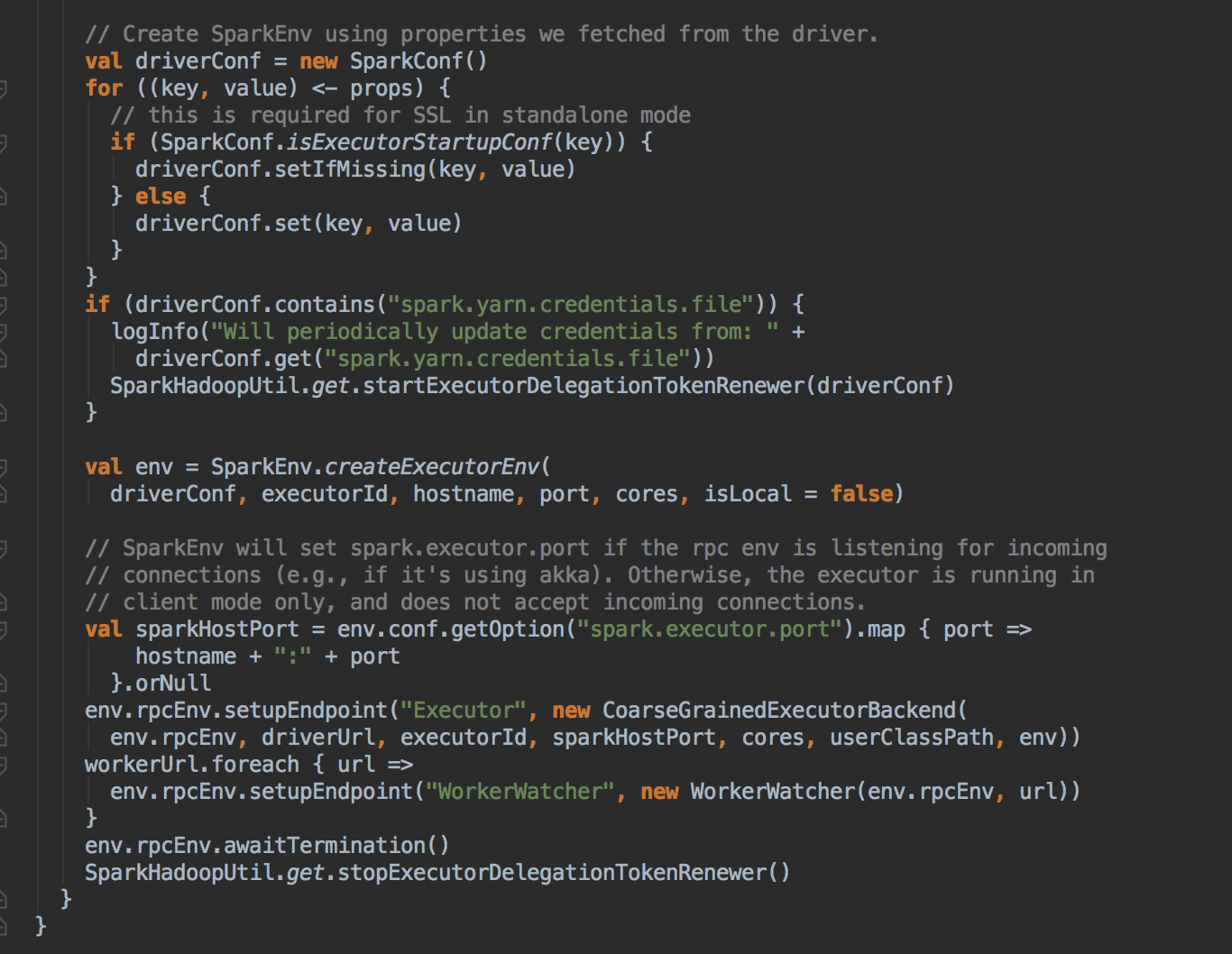
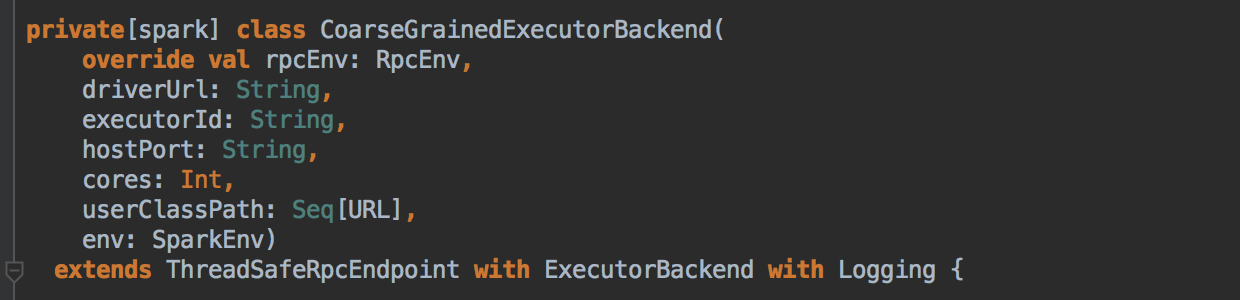
- 注冊成功后再实例化

- 然后创建一个很重要的对象,AppClient 对象,然后调用它的 client (AppClient) 的 start( ) 方法,创建一个 ClientEndpoint 对象。


- 它是一个 RpcEndPoint,然后接下来的故事就是向 Master 注冊,首先调用自己的 onStart 方法
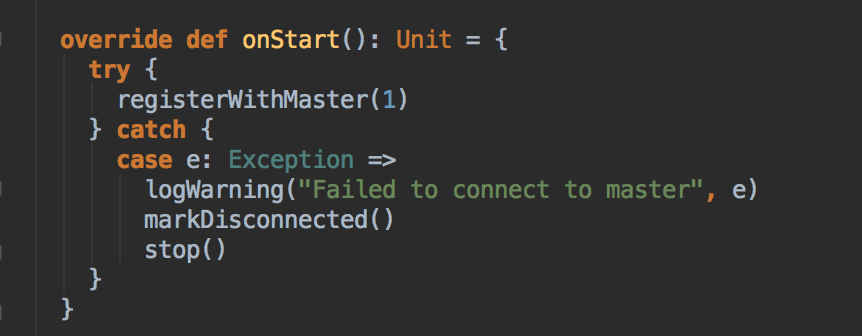
- 然后再调用 registerWithMaster 方法
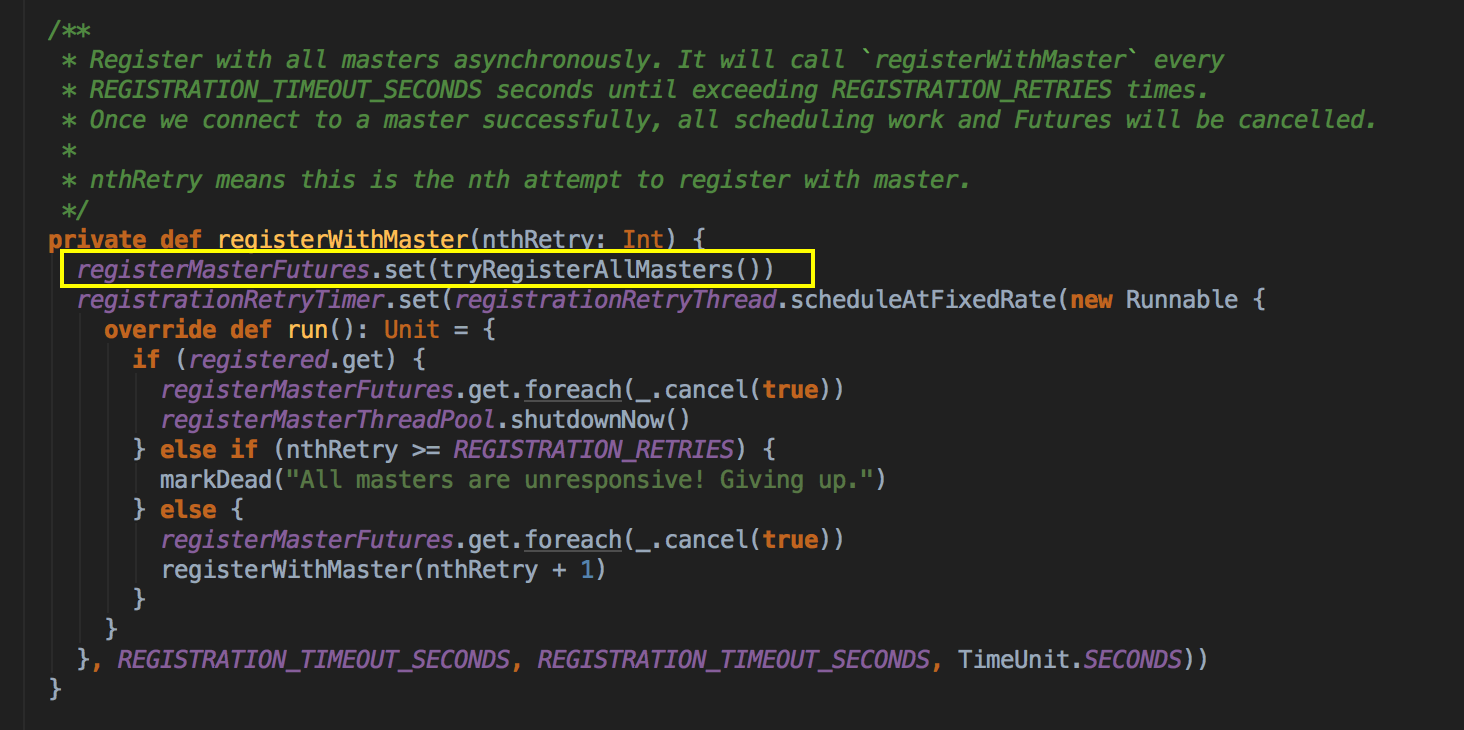
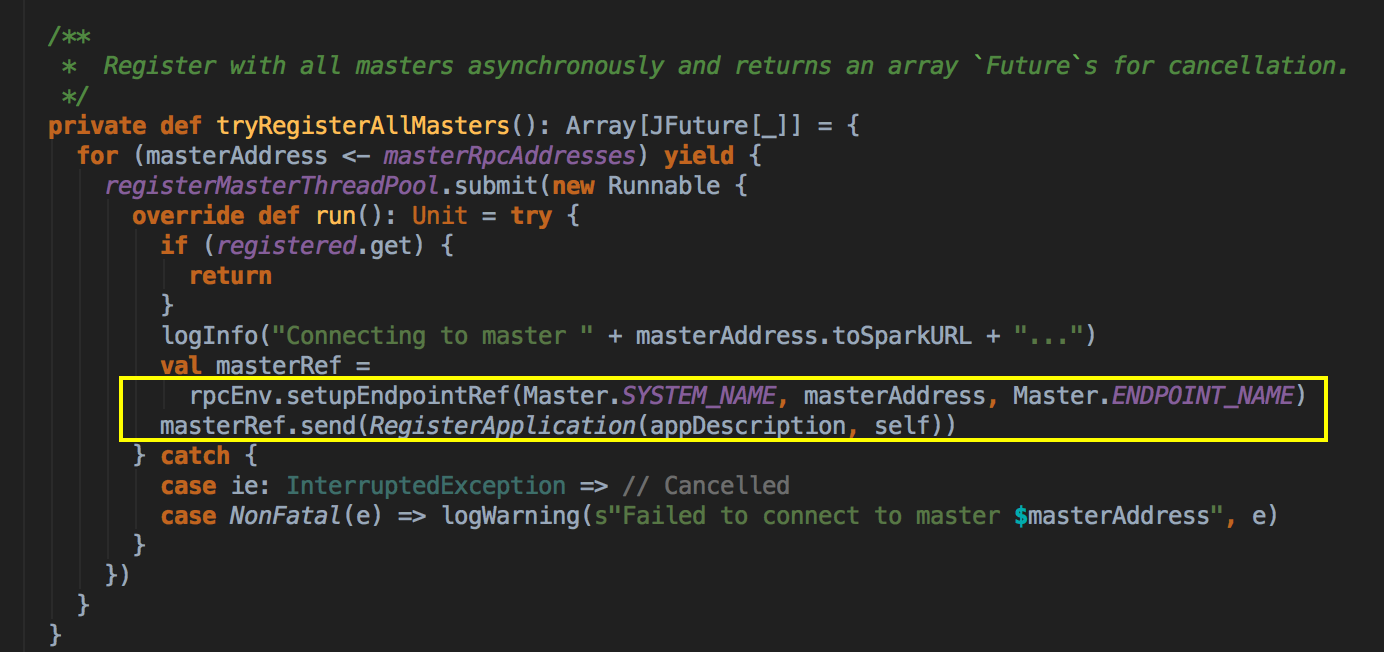
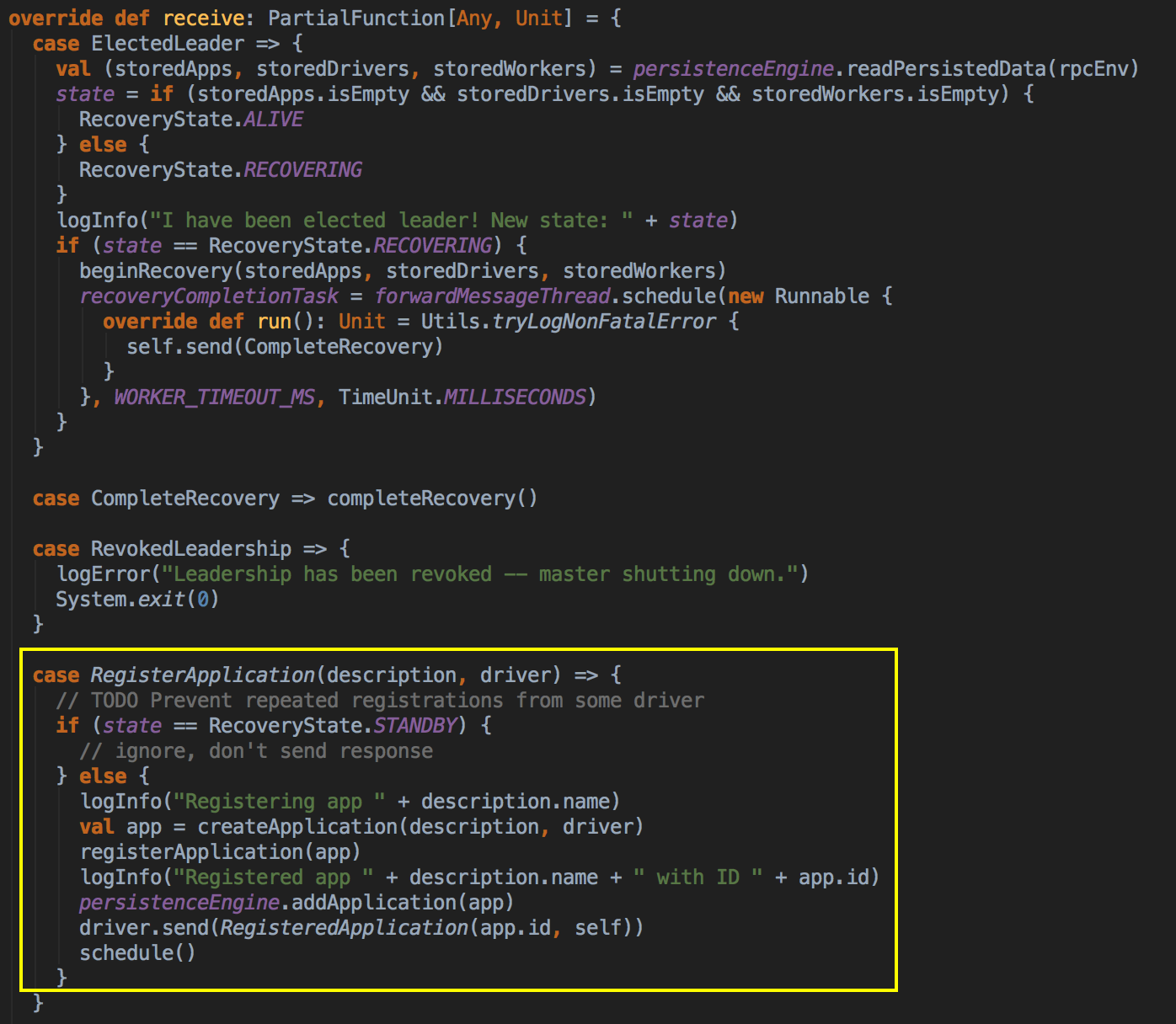
- 从 registerWithMaster 调用 tryRegisterAllMasters,开一条新的线程来注冊,然后发送一条信息(RegisterApplication 的case class ) 给 Master,注冊是通过 Thread 来完成的。

ApplicationDescription 的 case class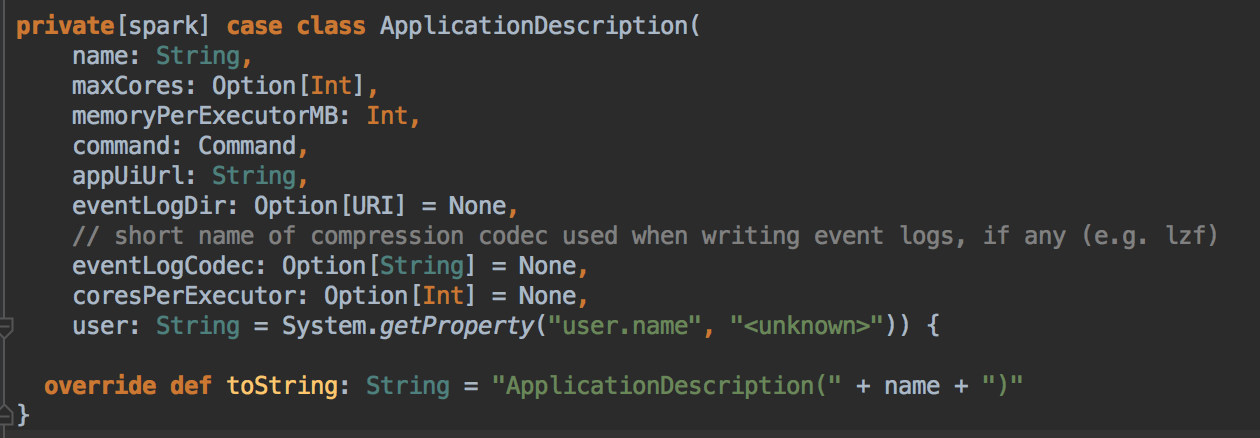
- Master 收到了这个信息便开始注冊,注冊后最后再次调用 schedule( ) 方法
总结
SparkContext 开启了天堂之门:Spark 程序是通过 SparkContext 发布到 Spark集群的SparkContext 导演了天堂世界:Spark 程序运行都是在 SparkContext 为核心的调度器的指挥下进行的:SparkContext 关闭了天堂之门:SparkContext 崩溃或者结束的是偶整个 Spark 程序也结束啦!
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第28课:Spark天堂之门解密视频
Spark源码图片取自于 Spark 1.6.0版本
[Spark内核] 第28课:Spark天堂之门解密的更多相关文章
- [Spark内核] 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本課主題 Spark Executor 工作原理图 ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕 Executor 具体是如何工作的 [引言部份:你希望读者看完这篇博客 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
本课主题 BlockManager 运行實例 BlockManager 原理流程图 BlockManager 源码解析 引言 BlockManager 是管理整个Spark运行时的数据读写的,当然也包 ...
- [Spark内核] 第35课:打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是從后往前划分的,执行的时候是從前往后执行的,每 ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- [Spark内核] 第29课:Master HA彻底解密
本课主题 Master HA 解析 Master HA 解析源码分享 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... Master HA 解析 生产环境下一般 ...
- [Spark内核] 第30课:Master的注册机制和状态管理解密
本課主題 Master 接收 Worker, Driver, Application Master 处理 Driver 狀态变换 Master 处理 Executor 狀态变换 [引言部份:你希望读者 ...
- [Spark内核] 第31课:Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本課主題 Master 资源调度的源码鉴赏 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... 资源调度管理 任务调度与资源是通过 DAGScheduler.Ta ...
- [Spark内核] 第34课:Stage划分和Task最佳位置算法源码彻底解密
本課主題 Job Stage 划分算法解密 Task 最佳位置算法實現解密 引言 作业调度的划分算法以及 Task 的最佳位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这 ...
随机推荐
- beautifulSoup模块
这个库用来对网页进行解析功能,十分强大,有了它我们可以减少对正则的使用,也能顺利的从网页源码中拿到我们要的值.他是一个灵活,方便的网页解析库,处理高效,支持多种解析器. 这个库把HTML源码解析成对象 ...
- linux_Mysql导入数据基本操作
创建数据库:Databases 数据库名字;导入数据: mysql -uroot -proot use 数据库名字 source < sql文件名.sql
- VBScripts and UAC elevation(visa以后的系统)
这两天由于工作须要.在写一些vbs的脚本,才知道.vbs不能像其它可运行文件一样.在 须要提升訪问权限时.弹出UAC窗体.那么,怎样通过UAC提升vbs脚本的訪问权限呢? 查了一些资料,将结果整理一下 ...
- IEEE Trans 2009 Stagewise Weak Gradient Pursuits论文学习
论文在第二部分先提出了贪婪算法框架,如下截图所示: 接着根据原子选择的方法不同,提出了SWOMP(分段弱正交匹配追踪)算法,以下部分为转载<压缩感知重构算法之分段弱正交匹配追踪(SWOMP)&g ...
- shell编辑crontab任务
crontab是Linux下执行定时任务的工具,之前偶尔需要用到时都是通过执行crontab -e命令或者通过root身份直接编辑/etc/cron.*/下的文件来添加定时任务.这段时间遇到了需要通过 ...
- Oracle数据库(三)表操作,连接查询,分页
复制表 --复制表 create table new_table as select * from Product --复制表结构不要数据 在where后面跟一个不成立的条件,就会仅复制表的结构而不复 ...
- Java之数据类型,变量赋值
Java中的基础数据类型(四类八种): 1.整数型 byte----使用byte关键字来定义byte型变量,可以一次定义多个变量并对其进行赋值,也可以不进行赋值.byte型是整型中所分配的内存空间是最 ...
- ios 访问隐私信息 info.plist 中的字段
1.iOS10相册相机闪退bug: iOS10系统下调用系统相册,相机功能,遇到闪退的情况,描述如下: This app has crashed because it attempted to acc ...
- SpringMVC总结
本文是对慕课网上"搞定SSM开发"路径的系列课程的总结,详细的项目文档和课程总结放在github上了.点击查看 MVC简介 Model-View-Control,MVC是一种架构模 ...
- AntData.ORM框架 之 DotnetCore
开源地址:https://github.com/yuzd/AntData.ORM CodeGen使用请参考http://www.cnblogs.com/yudongdong/p/6421312.h ...