Monte Carlo Policy Evaluation
Model-Based and Model-Free
In the previous several posts, we mainly talked about Model-Based Reinforcement Learning. The biggest assumption for Model-Based learning is the whole knowledge of the environment is given, but it is unrealistic in real life or even video games. I do believe unknown makes life (game) interesting. Personally, everytime I know what will happen in a game, I get rid of it! So, people like playing games with some uncertainties. That is what Model-Free Reinforcement Learning does: lean the unknown environment, and then come up with the best policy.
Two Task for Model-Free Learning
For Model-Based Learning,we have two tasks: Evaluation and Control. We use Dynamic Programming to evaluate a policy, while two algorithms called Policy Iteration and Value Iteration are used to extract the optimal policy. In Model-Free Learning, we have the same two tasks:
Evaluation: we need to estimate State-Value functions for every state, although Transition Matrices and Reward Function are not given.
Control: we need to find the best policy to solve the interesting game.
Monte Carlo Method in Daily Life
One of the algorithms for Evaluation is Monte Carlo Method. Probably the superior name 'Monte Carlo' is scaring, but you would feel comfortable while following my example below.
Assume our task is traveling from London to Toronto, and the policy is 'random walk'. we define travel distance and time as rewards. There are cities, towns, even villages on the map on which agents would randomly draw diverse trajectories from London to Toronto. Even it is possible that an agent arrives and departs some places more than once. But finally every agent will complete an episode when it arrives at Toronto, and then we can review paths, learning experience from trials.
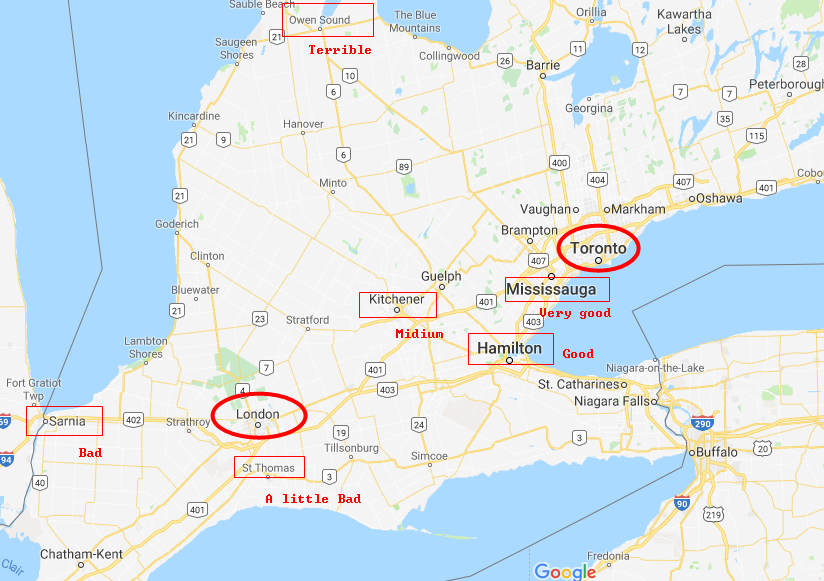
Finally, we will know goodnesses of being in every place on the map. Mississauga is a very good state for our task, but the state Owen Sound is terrible. The reason why we can get this conclusion is: states closed to the final state usually have great State-Value functions, because they tend to win the game soon. Episodes in our example that get to Mississauga have great probabilities getting to Toronto soon, so the Expectation of their State-Value functions is also high. On the other hand, the expectation of Owen Sound's State-Value function pretty low. That's why most people choose 401 Highway passing Mississauga to Toronto, but nobody go Owen Sound first. It's from daily life experience.
Definition of Monte Carlo Method
1. First-Visit Monte Carlo Evaluation Algorithm
Initialize:
a. π is the policy that needs to be evaluated;
b. V(St) is an arbitary State-Value function;
c. Counter matrix N(St), to record the appearance time of each state;
Repeat in loops:
a. Generate an episode from π
b. For each state s appearing in the episode for the first time, calculate new State-Value function V(St)
To avoid storing all returns or the sum of returns for all episodes, we transform the equation a little bit when we calculate the new State-Value function:
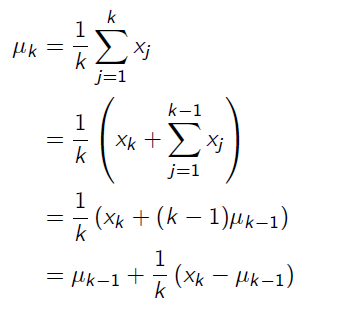
And we get the equation for updating State-Value function:
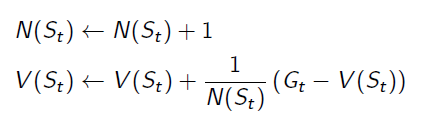
it can also be rewritten to:
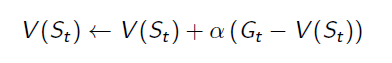
2. Every-Visit Monte Carlo Evaluation Algorithm
Initialize:
a. π is the policy that needs to be evaluated;
b. V(St) is an arbitary State-Value function;
c. Counter matrix N(St), to record the appearance time of each state;
Repeat in loops:
a. Generate an episode from π
b. For each state s appearing in the episode for every time, calculate new State-Value function V(St)
Population vs. Sample
A online video from MIT(Here we go) reminds me the idea of Population and Sample from Statistics. Population is quite like the whole knowledge on Model-Based learning, but getting samples is easier and more realistic in real life. Monte Carlo is similar to using the distribution of samples to do inference of the population.
Monte Carlo Policy Evaluation的更多相关文章
- 增强学习(四) ----- 蒙特卡罗方法(Monte Carlo Methods)
1. 蒙特卡罗方法的基本思想 蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法.该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基 ...
- 蒙特卡罗方法、蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)初探
1. 蒙特卡罗方法(Monte Carlo method) 0x1:从布丰投针实验说起 - 只要实验次数够多,我就能直到上帝的意图 18世纪,布丰提出以下问题:设我们有一个以平行且等距木纹铺成的地板( ...
- Monte Carlo Control
Problem of State-Value Function Similar as Policy Iteration in Model-Based Learning, Generalized Pol ...
- Introduction to Monte Carlo Tree Search (蒙特卡罗搜索树简介)
Introduction to Monte Carlo Tree Search (蒙特卡罗搜索树简介) 部分翻译自“Monte Carlo Tree Search and Its Applicati ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- Programming a Hearthstone agent using Monte Carlo Tree Search(chapter one)
Markus Heikki AnderssonHåkon HelgesenHesselberg Master of Science in Computer Science Submission dat ...
- Ⅳ Monte Carlo Methods
Dictum: Nutrition books in the world. There is no book in life, there is no sunlight; wisdom withou ...
- Monte Carlo方法简介(转载)
Monte Carlo方法简介(转载) 今天向大家介绍一下我现在主要做的这个东东. Monte Carlo方法又称为随机抽样技巧或统计实验方法,属于计算数学的一个分支,它是在上世纪四十年代 ...
- PRML读书会第十一章 Sampling Methods(MCMC, Markov Chain Monte Carlo,细致平稳条件,Metropolis-Hastings,Gibbs Sampling,Slice Sampling,Hamiltonian MCMC)
主讲人 网络上的尼采 (新浪微博: @Nietzsche_复杂网络机器学习) 网络上的尼采(813394698) 9:05:00 今天的主要内容:Markov Chain Monte Carlo,M ...
随机推荐
- man - 格式化并显示在线帮助手册页
总览 man [-acdfFhkKtwW] [-m 系统名] [-p <前处理程序>] [-C <配置文件>] [-M <路径>] [-P <浏览方式> ...
- PAT Basic 1036 跟奥巴马一起编程 (15 分)
美国总统奥巴马不仅呼吁所有人都学习编程,甚至以身作则编写代码,成为美国历史上首位编写计算机代码的总统.2014 年底,为庆祝“计算机科学教育周”正式启动,奥巴马编写了很简单的计算机代码:在屏幕上画一个 ...
- 1118. Birds in Forest (25)
Some scientists took pictures of thousands of birds in a forest. Assume that all the birds appear in ...
- 【学习】 015 Linux相关
Linux入门 什么是Linux Linux简介 Linux是一种自由和开放源码的操作系统,存在着许多不同的Linux版本,但它们都使用了Linux内核.Linux可安装在各种计算机硬件设备中,比如手 ...
- 高并发-原子性-AtomicInteger
线程不安全: //请求总次数private static int totalCount = 10000;//最大并发数private static int totalCurrency = 100;// ...
- Centos修改默认运行级别
一.centos默认运行级别 下面是linux的默认运行级别.vim /etc/inittab即可查看. # Default runlevel. The runlevels used are: # - ...
- MongoDB之自动启动服务
安装详细步骤请点我 为了能让NoSQLBooster for MongoDB连接的时候不报错,将mongodb添加到系统服务中. 在C:\Program Files\MongoDB\Server\3. ...
- Linux kswapd0 进程CPU占用过高
图便宜买了个1核1G虚拟机,启动两个jar后cpu飙升直接卡死,查看cpu及内存占用 发现kswapd0进程cpu占用一直居高不下,于是查询资料,总结如下. swap分区的作用是当物理内存不足时,会将 ...
- STM32内部硬核的认识
STM32内部含有硬核,对于一些协议(例如:UART,SPI,IIC,CRC等)我们只要调用硬核就可以了,同时我们也可以自己写通信协议. 这些硬核最终肯定是要有引脚输出的,这就是为什么STM32的引脚 ...
- POJ 3691 DNA repair ( Trie图 && DP )
题意 : 给出 n 个病毒串,最后再给出一个主串,问你最少改变主串中的多少个单词才能使得主串中不包含任何一个病毒串 分析 : 做多了AC自动机的题,就会发现这些题有些都是很套路的题目.在构建 Trie ...