哪吒票房超复联4,100行python代码抓取豆瓣短评,看看网友怎么说
《哪吒之魔童降世》这部国产动画巅峰之作,上映快一个月时间,票房口碑双丰收。
迄今已有超一亿人次观看,票房达到42.39亿元,超过复联4,跻身中国票房纪录第三名,仅次于《战狼2》和《流浪地球》。

去看豆瓣的评论,网友们对《哪吒》的喜爱溢于言表:
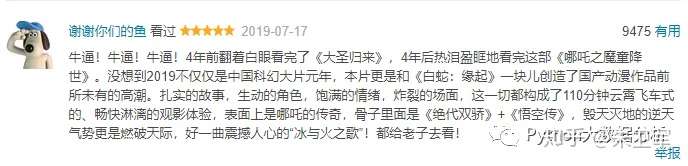


那么,网友评价哪吒这部动画用的最多的词是什么呢?
不把这些短评都爬取下来,再做个词云分布,就能了解网友都说了啥了。
这次是用python登录并爬取豆瓣短评,并做词云分布,分别用到requests、xpath、lxml、jieba、wordcloud等python库。
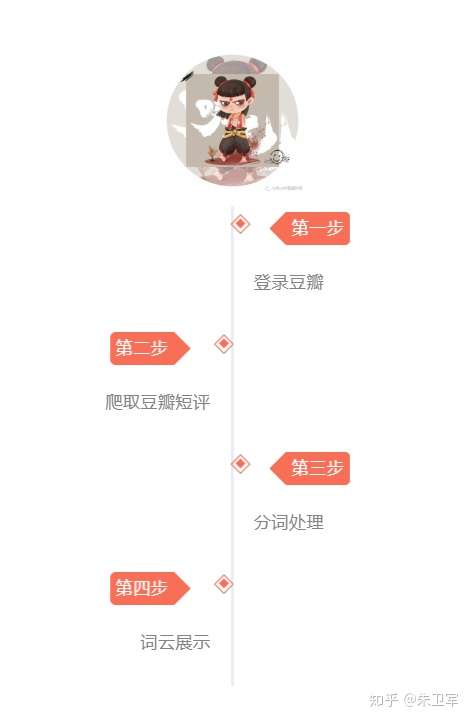
全文步骤如下:
话不多说,开始上代码吧!
# 导入需要的库
import requests
import time
import pandas as pd
import random
from lxml import etree
from io import BytesIO
import jieba
from wordcloud import WordCloud
import numpy as np
from PIL import Image # 为该项目创建一个类,命名nezha
# 该类有三个方法,分别是爬虫、分词、词云
class nezha():
def __init__(self):
# 定义session,用以加载HTML
self.session = requests.session()
# 定义爬虫的header,输入你浏览器上的header
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}
# 豆瓣登录网址
self.url_login = 'https://www.douban.com/login'
#哪吒电影短评网址,注意有改动,为了动态翻页,start后加了格式化数字,短评页面有20条数据,每页增加20条
self.url_comment = 'https://movie.douban.com/subject/26794435/comments?start=%d&limit=20&sort=new_score&status=P' def scrapy_(self):
# 加载登录界面HTML
login_request = self.session.get(self.url_login, headers=self.headers)
# 解析HTML
selector = etree.HTML(login_request.content)
# 以下是登录需要填的一些信息
post_data = {'source': 'None', # 不需要改动
'redir': 'https://www.douban.com', # 不需要改动
'form_email': 'your douban account', # 填账号
'form_password': 'your password', # 填密码
'login': '登录'} # 不需要改动
# 下面是获取验证码图片的链接
captcha_img_url = selector.xpath('//img[@id="captcha_image"]/@src')
# 如果有验证码,获取验证码图片,并填写图片上的验证码
if captcha_img_url != []:
# 获取验证码图片
pic_request = requests.get(captcha_img_url[0])
# 打开验证码图片
img = Image.open(BytesIO(pic_request.content))
img.show()
# 填写验证码
string = input('请输入验证码:')
post_data['captcha-solution'] = string
# 获取验证码匹配的字符
captcha_id = selector.xpath('//input[@name="captcha-id"]/@value')
# 将字符放入登录信息里
post_data['captcha-id'] = captcha_id[0]
# 登录
self.session.post(self.url_login, data=post_data)
print('已登录豆瓣') # 下面开始抓取短评
# 初始化4个list用于存储信息,分别存用户名,评星,时间,评论文字
users = []
stars = []
times = []
comment_texts = []
# 抓取500条,每页20条,这也是豆瓣给的上限
for i in range(0, 500, 20):
# 获取HTML
data = self.session.get(self.url_comment % i, headers=self.headers)
# 状态200表明页面获取成功
print('进度', i, '条', '状态是:',data.status_code)
# 暂停0~1秒时间,防止IP被封
time.sleep(random.random())
# 解析HTML
selector = etree.HTML(data.text)
# 用xpath获取单页所有评论
comments = selector.xpath('//div[@class="comment"]')
# 遍历所有评论,获取详细信息
for comment in comments:
# 获取用户名
user = comment.xpath('.//h3/span[2]/a/text()')[0]
# 获取评星
star = comment.xpath('.//h3/span[2]/span[2]/@class')[0][7:8]
# 获取时间
date_time = comment.xpath('.//h3/span[2]/span[3]/@title')
# 有的时间为空,需要判断下
if len(date_time) != 0:
date_time = date_time[0]
else:
date_time = None
# 获取评论文字
comment_text = comment.xpath('.//p/span/text()')[0].strip()
# 添加所有信息到列表,以下相同
users.append(user)
stars.append(star)
times.append(date_time)
comment_texts.append(comment_text)
# 用字典包装
comment_dic = {'user': users, 'star': stars, 'time': times, 'comments': comment_texts}
comment_df = pd.DataFrame(comment_dic) # 转换成DataFrame格式
comment_df.to_csv('duye_comments.csv') # 保存数据
comment_df['comments'].to_csv('comment.csv', index=False) # 将评论单独再保存下来,方便分词
print(comment_df) def jieba_(self):
# 打开评论数据文件
content = open('comment.csv', 'r', encoding='utf-8').read()
# jieba分词
word_list = jieba.cut(content)
# 添加自定义词,该片经典台词‘我命由我不由天’必须加进去
with open('自定义词.txt') as f:
jieba.load_userdict(f)
# 新建列表,收集词语
word = []
# 去掉一些无意义的词和符号,我这里自己整理了停用词库
for i in word_list:
with open('停用词库.txt') as f:
meaningless_file = f.read().splitlines()
f.close()
if i not in meaningless_file:
word.append(i.replace(' ', ''))
# 全局变量,方便词云使用
global word_cloud
# 用逗号隔开词语
word_cloud = ','.join(word)
print(word_cloud) def word_cloud_(self):
# 打开你喜欢的词云展现背景图,这里选用哪吒电影里的图片
cloud_mask = np.array(Image.open('nezha.jpg'))
# 定义词云的一些属性
wc = WordCloud(
background_color="white", # 背景图分割颜色为白色
mask=cloud_mask, # 背景图样
max_words=300, # 显示最大词数
font_path='./fonts/simhei.ttf', # 显示中文
min_font_size=5, # 最小尺寸
max_font_size=100, # 最大尺寸
width=400 # 图幅宽度
)
# 使用全局变量,刚刚分出来的词
global word_cloud
# 词云函数
x = wc.generate(word_cloud)
# 生成词云图片
image = x.to_image()
# 展示词云图片
image.show()
# 保存词云图片
wc.to_file('pic.png') # 创建类对象
nezha = nezha()
# 抓取豆瓣短评
nezha.scrapy_()
# 使用jieba对短评进行分词
nezha.jieba_()
# 使用wordcloud展示词云
nezha.word_cloud_()
看看我们抓取到的短评:

然后对短评分词处理:

选一张喜欢的图片做词云背景:

最后,制作词云图:

可以看到几个关键词:
哪吒、故事、国漫、大圣归来、我命由我不由天、喜欢、偏见
看来,大家对这部动画的故事情节比较满意,不经意地和大圣归来作对比。让人最感动的台词是“我命由我不由天”,一部良心的国产动画,大家期待已久,怎么能让人不喜欢呢?
END
如果大家想要学习更多的python数据分析知识,请关注我的公众号:pydatas
回复:数据分析,可领取《利用python进行数据分析 第二版》电子书

哪吒票房超复联4,100行python代码抓取豆瓣短评,看看网友怎么说的更多相关文章
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 100行Python代码实现一款高精度免费OCR工具
近期Github开源了一款基于Python开发.名为 Textshot 的截图工具,刚开源不到半个月已经500+Star. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语 ...
- 用python+selenium抓取豆瓣读书中最受关注图书并按评分排序
抓取豆瓣读书中的(http://book.douban.com/)最受关注图书,按照评分排序,并保存至txt文件中,需要抓取书籍的名称,作者,评分,体裁和一句话评 方法一: #coding=utf-8 ...
- 用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序
抓取豆瓣电影(http://movie.douban.com/nowplaying/chengdu/)中的正在热映前12部电影,并按照评分排序,保存至txt文件 #coding=utf-8 from ...
- python爬虫抓取豆瓣电影
抓取电影名称以及评分,并排序(代码丑炸) import urllib import re from bs4 import BeautifulSoup def get(p): t=0 k=1 n=1 b ...
- 一个 11 行 Python 代码实现的神经网络
一个 11 行 Python 代码实现的神经网络 2015/12/02 · 实践项目 · 15 评论· 神经网络 分享到:18 本文由 伯乐在线 - 耶鲁怕冷 翻译,Namco 校稿.未经许可,禁止转 ...
- 200行Python代码实现2048
200行Python代码实现2048 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面 ...
- 200行PYTHON代码实现贪吃蛇
200行Python代码实现贪吃蛇 话不多说,最后会给出全部的代码,也可以从这里Fork,正文开始: 目前实现的功能列表: 贪吃蛇的控制,通过上下左右方向键: 触碰到边缘.墙壁.自身则游戏结束: 接触 ...
随机推荐
- 双层for循环用java中的stream流来实现
//双重for循环for (int i = 0; i < fusRecomConfigDOList.size(); i++) { for (int j = 0; j < fusRecomC ...
- Spring Boot整合tk.mybatis及pageHelper分页插件及mybatis逆向工程
Spring Boot整合druid数据源 1)引入依赖 <dependency> <groupId>com.alibaba</groupId> <artif ...
- 25个Apache性能优化技巧推荐
25个Apache性能优化技巧推荐 Apache至今仍处于web服务器领域的霸主,无人撼动,没有开发者不知道.本篇文章介绍25个Apache性能优化的技巧,如果你能理解并掌握,将让你的Apache性能 ...
- 【SaltStack官方版】—— states教程, part 4 - states 说明
STATES TUTORIAL, PART 4 本教程建立在第1部分.第2部分.第3部分涵盖的主题上.建议您从此开始.这章教程我们将讨论更多 sls 文件的扩展模板和配置技巧. This part o ...
- 【Heaven Cow与God Bull】题解
题目 Description __int64 ago,there's a heaven cow called sjy... A god bull named wzc fell in love with ...
- [洛谷P2154] SDOI2009 虔诚的墓主人
问题描述 小W是一片新造公墓的管理人.公墓可以看成一块N×M的矩形,矩形的每个格点,要么种着一棵常青树,要么是一块还没有归属的墓地. 当地的居民都是非常虔诚的基督徒,他们愿意提前为自己找一块合适墓地. ...
- react native 之 AsyncStorage
新版本中不时从react-native导入了,而是 react-native-async-storage 使用static setItem(key: string, value: string, [c ...
- [ZJU 1010] Area
ZOJ Problem Set - 1010 Area Time Limit: 2 Seconds Memory Limit: 65536 KB Special Judge Jer ...
- 纯CSS手动滑动轮播图(隐藏滚动条)
HTML: <div class="bigder"> <div class="big"> <dl> <dt>&l ...
- Csharp随机生成序列码的方式Guid方法
主要用于邮箱激活,加密等用处 Guid.NewGuid().ToString()得几种格式显示 .Guid.NewGuid().ToString("N") 结果为: 38bddf4 ...