Scikit-learn的kmeans聚类
1. 生成随机的二维数据:
import numpy as np
x1 = np.array([1, 2, 3, 1, 5, 6, 5, 5, 6, 7, 8, 9, 9])
x2 = np.array([1, 3, 2, 2, 8, 6, 7, 6, 7, 1, 2, 1, 3])
x = np.array(list(zip(x1, x2))).reshape(len(x1), 2) #先将x1和x2用zip组合,然后再转换成list,最后reshape print (x)
2.生成聚类标签:
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=3) #n_clusters:number of cluster
kmeans.fit(x)
print (kmeans.labels_)
3.显示聚类效果:
import matplotlib.pyplot as plt
plt.figure(figsize=(5,5))
colors = ['b', 'g', 'r']
markers = ['o', 's', 'D']
for i,l in enumerate(kmeans.labels_):
plt.plot(x1[i],x2[i],color=colors[l],marker=markers[l],ls='None')
plt.show()
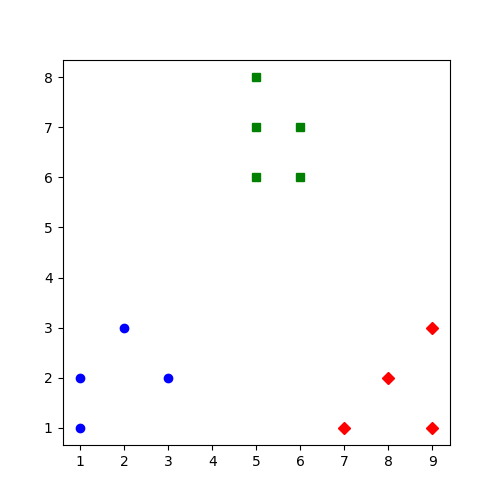
参考: https://blog.csdn.net/qq_34264472/article/details/53217748 (此为python2代码)
Scikit-learn的kmeans聚类的更多相关文章
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- kmeans聚类中的坑 基于R shiny 可交互的展示
龙君蛋君 2015年5月24日 1.背景介绍 最近公司在用R 建模,老板要求用shiny 展示结果,建模的过程中用到诸如kmean聚类,时间序列分析等方法.由于之前看过一篇讨论kmenas聚类针对某一 ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- 用scikit-learn学习K-Means聚类
在K-Means聚类算法原理中,我们对K-Means的原理做了总结,本文我们就来讨论用scikit-learn来学习K-Means聚类.重点讲述如何选择合适的k值. 1. K-Means类概述 在sc ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- K-means聚类算法
聚类分析(英语:Cluster analysis,亦称为群集分析) K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般.最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中, ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
随机推荐
- ZCMU训练赛-A(模拟)
A - Applications https://vjudge.net/contest/174208#overview Recently, the ACM/ICPC team of Marjar Un ...
- 学习LSM(Linux security module)之三:Apparmor的前世今生和基本使用
感冒了,感觉一脑子浆糊,真是蛋疼. 先粗略讲一些前置知识. 一:MAC和DAC DAC(Discretionary Access Control),自主访问控制,是最常用的一类访问控制机制,意思为主体 ...
- rsync用于同步目录
rsync是unix/linux下同步文件的一个高效算法,它能同步更新两处计算机的文件与目录,并适当利用查找文件中的不同块以减少数据传输.rsync中一项与其他大部分类似程序或协定中所未见的重要特性是 ...
- Gitlab运维
安装Gitlab 新建 /etc/yum.repos.d/gitlab-ce.repo [gitlab-ce] name=gitlab-ce baseurl=http://mirrors.tuna.t ...
- 列(Column)
同样是生肉,不同的生肉又有不同的特性,有的生肉是里脊肉,有的生肉是前臀尖,这块生肉是18公斤,而那块生肉是12公斤,这块生肉是12.2 元/公斤,而那块生肉是13.6 元/公斤.每块肉都有各自的不同 ...
- Windows 10 作为无线显示器无法被搜索到
症状描述: Windows 10 的投影到此电脑功能失效,但是其它功能正常.同一网络,室友的电脑正常. 解决办法: 设备管理器启用“Microsoft Wi-Fi Direct Virtual Ada ...
- 【MySQL笔记】数据操纵语言DML
1.数据插入 INSERT INTO table_name (列1, 列2,...) VALUES(值1, 值2,....),(第二条),(第三条)... 注: 1)如果表中的每一列均有数据插 ...
- 《ggplot2:数据分析与图形艺术》,读书笔记
第1章 简介 1.3图形的语法 第2章从qplot开始入门 1.基本用法:qplot(x,y,data) x是自变量横轴,y是因变量纵轴,data是数据框 2.图形参数 colour=I(&quo ...
- 【R笔记】日期处理
R语言学习笔记:日期处理 1.取出当前日期 Sys.Date() [1] "2014-10-29" date() #注意:这种方法返回的是字符串类型 [1] "Wed O ...
- 理解Android绘制视图的方式
在创建自定义ViewGroup前,读者首先需要理解Android绘制视图的方式.我不会涉及过多细节,但是需要读者理解Android开发文档(见3.5节)中的一段话,这段话解释如何绘制一个布局.内容如下 ...