吴恩达《Machine Learning Yearning》总结(21-30章)
21.偏差和方差举例
前提:对于人类而言,可以达到近乎完美的表现(即人类去做分类是误差可以接近0)。
(1)假设算法的表现如下:训练误差率:1%,开发误差率:11%;此时即为高方差(high variance),也被称为过拟合(overfitting)。
(2)假设算法的表现如下:训练误差:15&,开发误差率:16%;此时即为高偏差(high bias),也被称为欠拟合(underfitting)。
(3)假设算法的表现如下:训练误差:15%,开发误差率:30%;此时即为高偏差和高方差。
(4)假设算法的表现如下:训练误差:0.5%,开发误差率:1%;此时算法已经非常完美。
22.与最优误差率比较
举例:当一个连人类都很难完成(如很多噪音的语音识别)的分类任务,人类的误差率达到14%,此时最完美的误差为14%,该误差称为最优误差率,也称为贝叶斯错误率(Bayes error rate)。以上的最优错误率是可以确定的,但是有些问题如电影推荐,很难去确定其最优误差率是多少。
此时偏差和进一步细化:偏差=最优误差率+可避免偏差;其中可避免偏差高时才值得去优化。
23..处理偏差和方差
(1)如果具有较高的可避免偏差,那么可以加大模型的规模(例如增加神经元的层数、每层神经元的个数)。
(2)如果具有较高的方差,那么可以向训练集增加数据。
其他(3)改变网络的架构,这样会带来新的结果。
在增大网络模型时,会带来高方差的风险,但只要通过适当的正则化(如L2),或者dropout等策略,就不会出现这样的问题。
24.偏差和方差间的均衡
在现如今,往往可以获得足够的数据,并且足够的算力来支撑非常大的网络,所以不会出现此消彼长的情况。
25.减少可避免偏差的技术
(1)加大模型规模(例如层数/神经元个数),此时加入正则化可以抵消方差的增加。
(2)根据误差分析结果修改输入特征。
(3)减少或者去除正则化。这种方式会增加方差。
(4)修改模型架构。这项技术会同时影响方差和偏差。
26.训练集误差分析
在训练集上也做类似于开发集上的误差分析。
27.减少方差的技术
(1)添加更多的训练数据。
(2)加入正则化(L1,L2,Dropout),该项会增大偏差。
(3)加入提前终止(比如根据开发集提前终止梯度下降),这项技术会增加偏差,一些学者将其归入正则化技术之一。
(4)通过特征选择减少特征的数量和种类,当数据集很小时,特征选择非常有用。
(5)减小模型规模,谨慎使用。
以下两种方式和减少偏差的策略相同
(6)根据误差分析结果修改输入特征。
(7)修改模型架构。
28.诊断偏差与方差:学习曲线
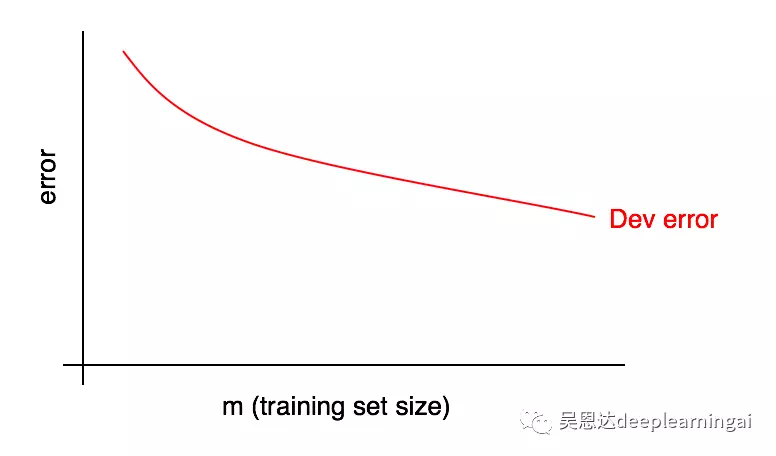
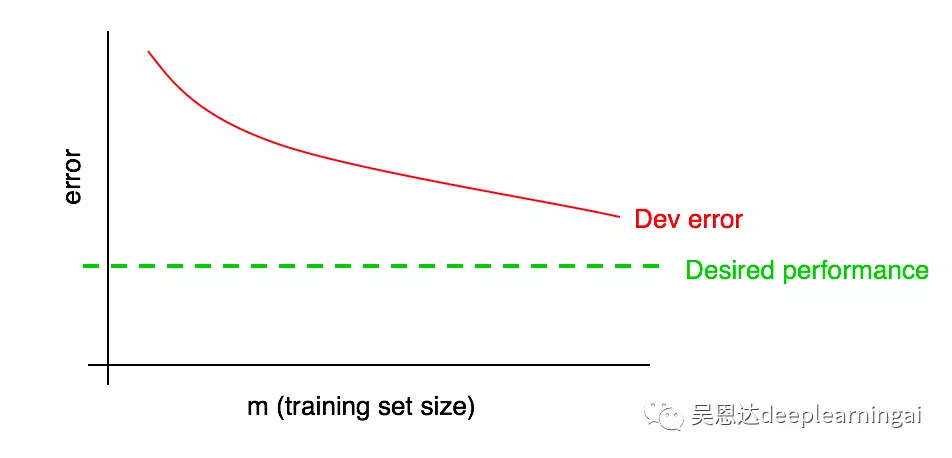
学习1曲线:误差随数据量增加的变化趋势。
学习曲线有一个缺点:当数据量变得越来越多是,将很难预测后续红色曲线的走向。
29.绘制训练误差曲线
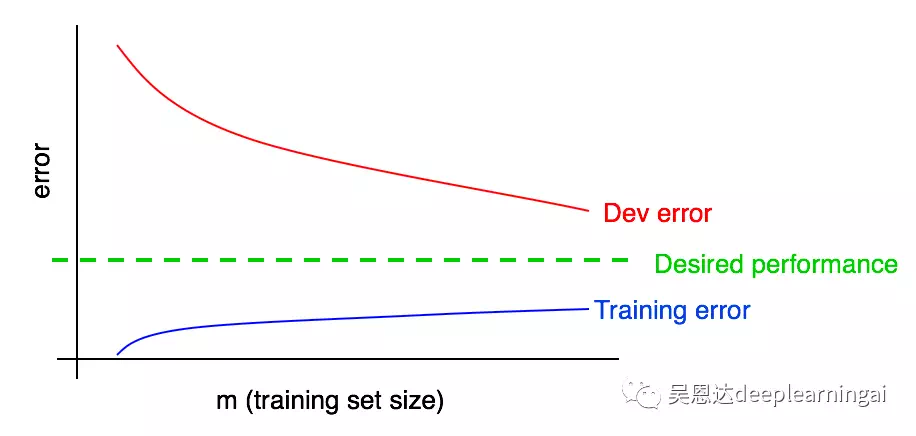
训练误差上升说明:比如两张图片算法很容易就分辨出来,其误差为0,当增加到100张时,就不一定都能正确识别了。
30.解读学习曲线:高偏差
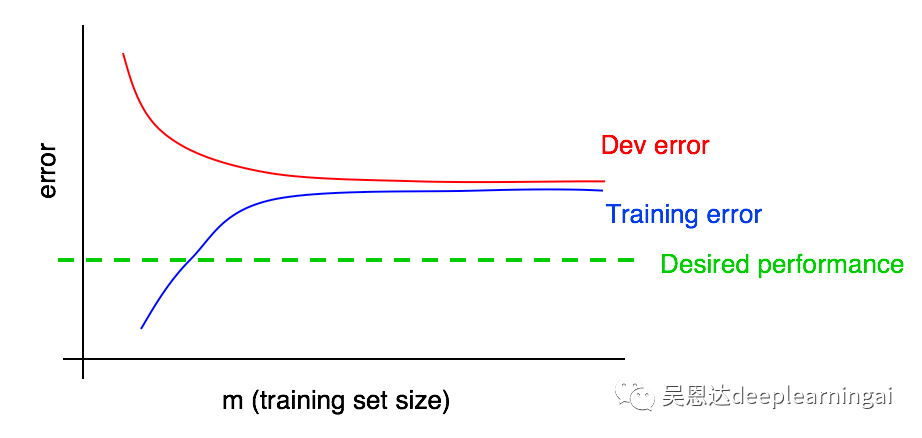
观察结果:
(1)随着我们添加更多的训练数据,训练误差只会变得更糟,因此蓝色的训练误差曲线只会保持不动或上升,这表明它只会远离期望的性能水平(绿色的线)。
(2)红色的开发误差曲线通常要高于蓝色的误差曲线,因此只要训练误差高于期望性能水平,通过添加更多数据来让红色开发误差曲线下降到期望性能水平之下也基本不可能。
之前我们讨论的都是曲线的最右端,而通过学习曲线则更加的群面了解算法。
吴恩达《Machine Learning Yearning》总结(21-30章)的更多相关文章
- 吴恩达Machine Learning 第一周课堂笔记
1.Introduction 1.1 Example - Database mining Large datasets from growth of automation/ ...
- 吴恩达Machine Learning学习笔记(一)
机器学习的定义 A computer program is said to learn from experience E with respect to some class of tasks T ...
- 吴恩达Machine Learning学习笔记(四)--BP神经网络
解决复杂非线性问题 BP神经网络 模型表示 theta->weights sigmoid->activation function input_layer->hidden_layer ...
- 吴恩达Machine Learning学习笔记(三)--逻辑回归+正则化
分类任务 原始方法:通过将线性回归的输出映射到0-1,设定阈值来实现分类任务 改进方法:原始方法的效果在实际应用中表现不好,因为分类任务通常不是线性函数,因此提出了逻辑回归 逻辑回归 假设表示--引入 ...
- 吴恩达Machine Learning学习笔记(二)--多变量线性回归
回归任务 多变量线性回归 公式 h为假设,theta为模型参数(代表了特征的权重),x为特征的值 参数更新 梯度下降算法 影响梯度下降算法的因素 (1)加速梯度下降:通过让每一个输入值大致在相同的范围 ...
- 吴恩达 Deep learning 第二周 神经网络基础
逻辑回归代价函数(损失函数)的几个求导特性 1.对于sigmoid函数 2.对于以下函数 3.线性回归与逻辑回归的神经网络图表示 利用Numpy向量化运算与for循环运算的显著差距 import nu ...
- 吴恩达 Deep learning 第一周 深度学习概论
知识点 1. Relu(Rectified Liner Uints 整流线性单元)激活函数:max(0,z) 神经网络中常用ReLU激活函数,与机器学习课程里面提到的sigmoid激活函数相比有以下优 ...
- Github | 吴恩达新书《Machine Learning Yearning》完整中文版开源
最近开源了周志华老师的西瓜书<机器学习>纯手推笔记: 博士笔记 | 周志华<机器学习>手推笔记第一章思维导图 [博士笔记 | 周志华<机器学习>手推笔记第二章&qu ...
- 我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)【中英双语】
我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)[中英双语] 视频地址:https://www.bilibili.com/video/av9912938/ t ...
- Coursera课程《Machine Learning》吴恩达课堂笔记
强烈安利吴恩达老师的<Machine Learning>课程,讲得非常好懂,基本上算是无基础就可以学习的课程. 课程地址 强烈建议在线学习,而不是把视频下载下来看.视频中间可能会有一些问题 ...
随机推荐
- linux下利用httpd搭建tomcat集群,实现负载均衡
公司使用运营管理平台是单点tomcat,使用量大,或者导出较大的运营数据时,会造成平台不可用,现在需要搭建tomcat集群,调研后,决定使用apache的httpd来搭建tomcat集群.以下是搭建步 ...
- 函数形参为基类数组,实参为继承类数组,下存在的问题------c++程序设计原理与实践(进阶篇)
示例: #include<iostream> using namespace std; class A { public: int a; int b; A(int aa=1, int bb ...
- java 中 ==
@Test public void fuu2(){ String a = new String("aw"); String b = new String("aw" ...
- 简单概括下浏览器事件模型,如何获得资源dom节点
在各种浏览器中存在三种事件模型:原始事件模型,DOM2事件模型,IE事件模型.其中原始的事件模型被所有浏览器所支持,而DOM2中所定义的事件模型目前被除了IE以外的所有主流浏览器支持. 浏览器事件模型 ...
- 八大排序算法的python实现(四)快速排序
代码: #coding:utf-8 #author:徐卜灵 #交换排序.快速排序 # 虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤.因此我的对快速排序作了进一步的说明: ...
- HMTL5 本地数据库
数据库这个东东现在也可以用在web上了,目前为止, chrom 6 以上版本,opera 10 以上,safari 5以上支持这个功能. htm4中数据库只能放在服务器,只能通过服务器来访问,但是在h ...
- Linux磁盘占满 no space left on device
假如当前文件删除了,如果还有其他进程还在使用这个文件,这个文件删不干净:https://www.cnblogs.com/heyonggang/p/3644736.html 在Linux下查看磁盘空间使 ...
- Python中的if __name__ == '__main__'
如何简单地理解Python中的if __name__ == '__main__' 1. 摘要 通俗的理解__name__ == '__main__':假如你叫小明.py,在朋友眼中,你是小明(__ ...
- Python + gevent模块对单个接口进行并发测试 1
本文知识点 利用gevent模块进行并发测试 代码如下 from gevent import monkey monkey.patch_all() import requests import geve ...
- bzoj1221软件开发 费用流
题目传送门 思路: 网络流拆点有的是“过程拆点”,有的是“状态拆点”,这道题应该就属于状态拆点. 每个点分需要用的,用完的. 对于需要用的,这些毛巾来自新买的和用过的毛巾进行消毒的,流向终点. 对于用 ...