Python爬虫实战:将网页转换为pdf电子书
写爬虫似乎没有比用 Python 更合适了,Python 社区提供的爬虫工具多得让你眼花缭乱,各种拿来就可以直接用的 library 分分钟就可以写出一个爬虫出来,今天就琢磨着写一个爬虫,将廖雪峰的 Python 教程 爬下来做成 PDF 电子书方便大家离线阅读。
开始写爬虫前,我们先来分析一下该网站1的页面结构,网页的左侧是教程的目录大纲,每个 URL 对应到右边的一篇文章,右侧上方是文章的标题,中间是文章的正文部分,正文内容是我们关心的重点,我们要爬的数据就是所有网页的正文部分,下方是用户的评论区,评论区对我们没什么用,所以可以忽略它。
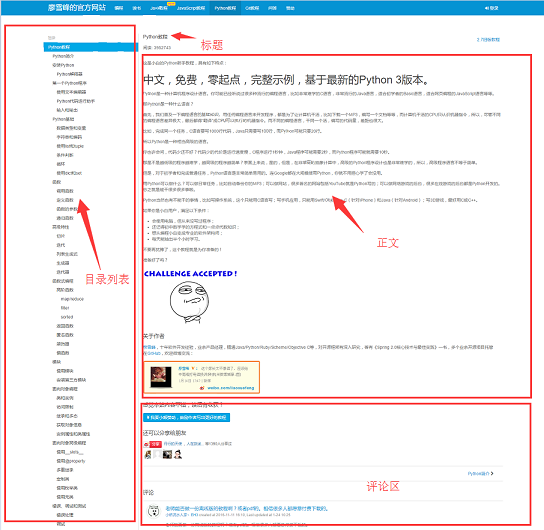
工具准备
弄清楚了网站的基本结构后就可以开始准备爬虫所依赖的工具包了。requests、beautifulsoup 是爬虫两大神器,reuqests 用于网络请求,beautifusoup 用于操作 html 数据。有了这两把梭子,干起活来利索,scrapy 这样的爬虫框架我们就不用了,小程序派上它有点杀鸡用牛刀的意思。此外,既然是把 html 文件转为 pdf,那么也要有相应的库支持, wkhtmltopdf 就是一个非常好的工具,它可以用适用于多平台的 html 到 pdf 的转换,pdfkit 是 wkhtmltopdf 的Python封装包。首先安装好下面的依赖包,接着安装 wkhtmltopdf
pip install requests pip install beautifulsoup pip install pdfkit
安装 wkhtmltopdf
Windows平台直接在 wkhtmltopdf 官网2下载稳定版的进行安装,安装完成之后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”。Ubuntu 和 CentOS 可以直接用命令行进行安装
$ sudo apt-get install wkhtmltopdf # ubuntu $ sudo yum intsall wkhtmltopdf # centos
爬虫实现
一切准备就绪后就可以上代码了,不过写代码之前还是先整理一下思绪。程序的目的是要把所有 URL 对应的 html 正文部分保存到本地,然后利用 pdfkit 把这些文件转换成一个 pdf 文件。我们把任务拆分一下,首先是把某一个 URL 对应的 html 正文保存到本地,然后找到所有的 URL 执行相同的操作。
用 Chrome 浏览器找到页面正文部分的标签,按 F12 找到正文对应的 div 标签: <div class="x-wiki-content">,该 div 是网页的正文内容。用 requests 把整个页面加载到本地后,就可以使用 beautifulsoup 操作 HTML 的 dom 元素 来提取正文内容了。
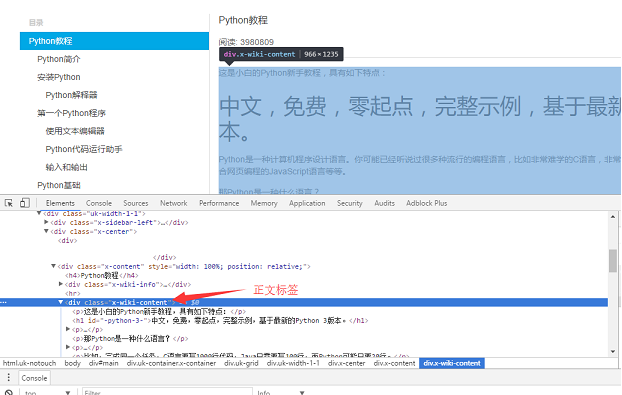
具体的实现代码如下:用 soup.find_all 函数找到正文标签,然后把正文部分的内容保存到 a.html 文件中。
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)
第二步就是把页面左侧所有 URL 解析出来。采用同样的方式,找到 左侧菜单标签 <ul class="uk-nav uk-nav-side">
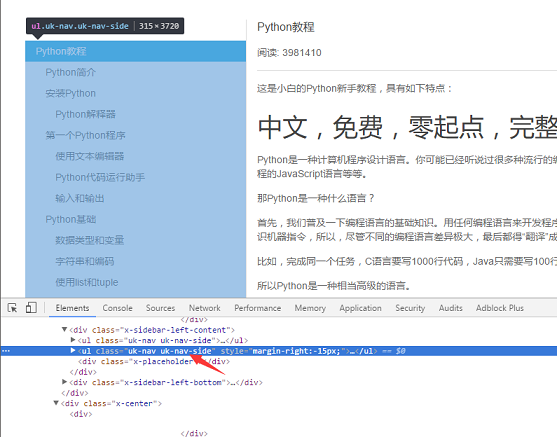
具体代码实现逻辑:因为页面上有两个uk-nav uk-nav-side的 class 属性,而真正的目录列表是第二个。所有的 url 获取了,url 转 html 的函数在第一步也写好了。
Python3-廖雪峰带标签完整版pdf下载:http://www.gooln.com/document/161286.html
def get_url_list():
"""
获取所有URL目录列表
"""
response = requests.get("http://www.gooln.com/document/161286.html")
soup = BeautifulSoup(response.content, "html5lib")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.gooln.com/" + li.a.get('href')
urls.append(url)
return urls
最后一步就是把 html 转换成pdf文件了。转换成 pdf 文件非常简单,因为 pdfkit 把所有的逻辑都封装好了,你只需要调用函数 pdfkit.from_file
def save_pdf(htmls):
"""
把所有html文件转换成pdf文件
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(htmls, file_name, options=options)
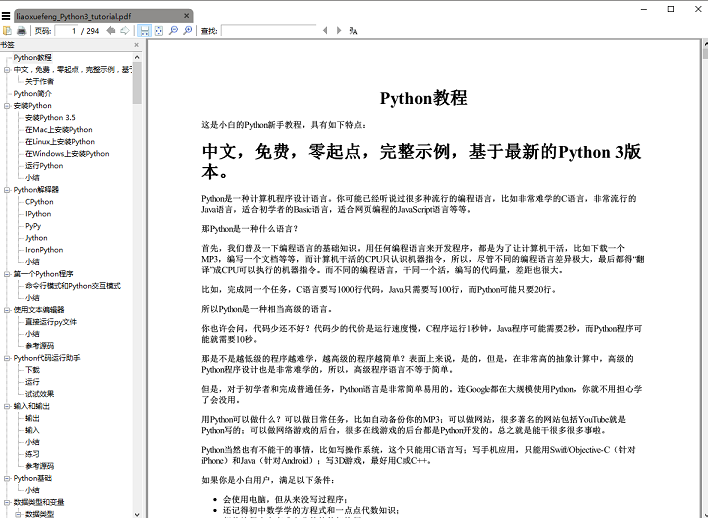
执行 save_pdf 函数,电子书 pdf 文件就生成了,效果图:
总结
总共代码量加起来不到50行,不过,且慢,其实上面给出的代码省略了一些细节,比如,如何获取文章的标题,正文内容的 img 标签使用的是相对路径,如果要想在 pdf 中正常显示图片就需要将相对路径改为绝对路径,还有保存下来的 html 临时文件都要删除,这些细节末叶都放在github上。
完整代码可以上github下载 ,代码在 Windows 平台亲测有效,欢迎 fork 下载自己改进。github 地址3,GitHub访问不了的同学可以用码云4, 《廖雪峰的 Python 教程》电子书 PDF 文件可以通过关注本公众号『一个程序员的微站』回复 “pdf” 免费下载阅读。
Python爬虫实战:将网页转换为pdf电子书的更多相关文章
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- 《Python3网络爬虫开发实战》PDF+源代码+《精通Python爬虫框架Scrapy》中英文PDF源代码
下载:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw <Python 3网络爬虫开发实战>中文PDF+源代码 下载:https://pan. ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
综述 最近山大软件园校区QLSC_STU无线网掉线掉的厉害,连上之后平均十分钟左右掉线一次,很是让人心烦,还能不能愉快地上自习了?能忍吗?反正我是不能忍了,嗯,自己动手,丰衣足食!写个程序解决掉它! ...
随机推荐
- opencv学习笔记(六)---图像梯度
图像梯度的算法有很多方法:sabel算子,scharr算子,laplacian算子,sanny边缘检测(下个随笔)... 这些算子的原理可参考:https://blog.csdn.net/poem_q ...
- C++中define与const的区别
C++中不但可以用define定义常量还可以用const定义常量,它们的区别如下: 用#define MAX 255定义的常量是没有类型的,所给出的是一个立即数,编译器只是把所定义的常量值与所定义的常 ...
- 数据结构5.4_m元多项式的表示
三元多项式表示如下: P(x,y,z) = x10y3z2 + 2x6y3z2 + 3x5y2z2 + x4y4z + 6x3y4z + 2yz + 15 然后对式子进行变形: P(x,y,z)=(( ...
- 【算法笔记】B1028 人口普查
1028 人口普查 (20 分) 某城镇进行人口普查,得到了全体居民的生日.现请你写个程序,找出镇上最年长和最年轻的人. 这里确保每个输入的日期都是合法的,但不一定是合理的——假设已知镇上没有超过 2 ...
- LOJ6502. 「雅礼集训 2018 Day4」Divide(构造+dp)
题目链接 https://loj.ac/problem/6502 题解 中间一档部分分提示我们将所有的 \(w_i\) 排序. 考虑如果我们能构造出这样一个 \(w_i\) 的序列,使得该序列满足:对 ...
- 离散化test
#include<bits/stdc++.h> using namespace std; const int maxn = 1e6+11; int ll[maxn],rr[maxn],ma ...
- PIE SDK热力图
1.算法功能简介 热力图,也就热图或者热点图,它能以特殊高亮的的形式显示某一区域的等级的优越性.重要性或者某一区域类别的密度和变换趋势:例如百度地图热力图 是用不同颜色的区块叠加在地图上实时描述人 ...
- 如何在vue && webpack 项目中的单文件组件中引入css
引入方式很简单,就是在script下使用require()即可. 因为import 是import...from 的形式,所以是不需要的. <script> import {mapStat ...
- Eclipse/Myeclipse/Scala IDEA for Eclipse里两种添加插件的方法(在线和离线)
不多说,直接上干货! 方法1:在线安装 第一步,在eclipse菜单栏下,选中help ---->Install New Software 第二步,点击图中 add 添加软件下载地址 第三步 , ...
- 虚拟机xp系统中Oracle 10g的安装
1 安装过程(11步) 2.如果是xp系统可以直接并双击解压目录下的setup.ext,出现安装界面,如下: 3.输入口令和确认口令,如:oracle,点击下一步,出现如下进度条. 注:此口令即是管理 ...