Halodoc使用 Apache Hudi 构建 Lakehouse的关键经验
Halodoc 数据工程已经从传统的数据平台 1.0 发展到使用 LakeHouse 架构的现代数据平台 2.0 的改造。在我们之前的博客中,我们提到了我们如何在 Halodoc 实施 Lakehouse 架构来服务于大规模的分析工作负载。 我们提到了平台 2.0 构建过程中的设计注意事项、最佳实践和学习。
本博客中我们将详细介绍 Apache Hudi 以及它如何帮助我们构建事务数据湖。我们还将重点介绍在构建Lakehouse时面临的一些挑战,以及我们如何使用 Apache Hudi 克服这些挑战。
Apache Hudi
让我们从对 Apache Hudi 的基本了解开始。 Hudi 是一个丰富的平台,用于在自我管理的数据库层上构建具有增量数据管道的流式数据湖,同时针对湖引擎和常规批处理进行了优化。
Apache Hudi 将核心仓库和数据库功能直接引入数据湖。 Hudi 提供表、事务、高效的 upserts/deletes、高级索引、流式摄取服务、数据Clustering/压缩优化和并发性,同时将数据保持为开源文件格式。
Apache Hudi 可以轻松地在任何云存储平台上使用。 Apache Hudi 的高级性能优化,使得使用任何流行的查询引擎(包括 Apache Spark、Flink、Presto、Trino、Hive 等)的分析工作负载更快。
让我们看看在构建Lakehouse时遇到的一些关键挑战,以及我们如何使用 Hudi 和 AWS 云服务解决这些挑战。
在 LakeHouse 中执行增量 Upsert
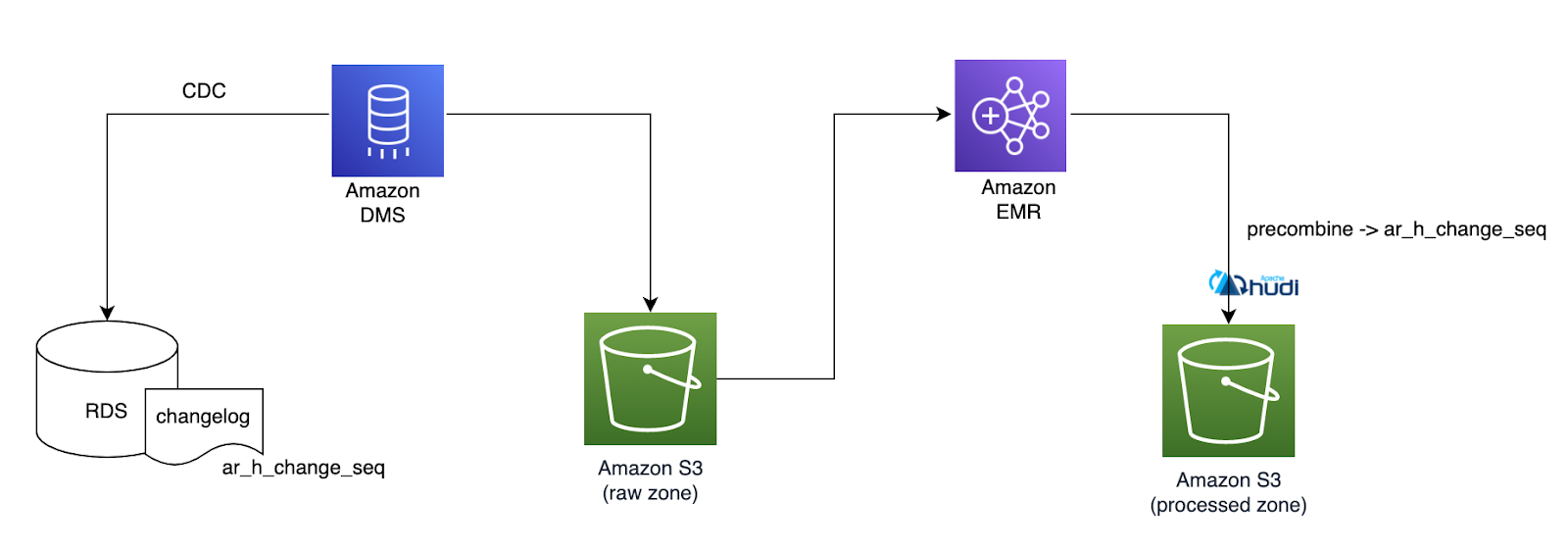
每个人在构建事务数据湖时面临的主要挑战之一是确定正确的主键来更新数据湖中的记录。在大多数情况下都使用主键作为唯一标识符和时间戳字段来过滤传入批次中的重复记录。
在 Halodoc,大多数微服务使用 RDS MySQL 作为数据存储。我们有 50 多个 MySQL 数据库需要迁移到数据湖,交易经历各种状态,并且在大多数情况下经常发生更新。
问题:
MySQL RDS 以秒格式存储时间戳字段,这使得跟踪发生在毫秒甚至微秒内的事务变得困难,使用业务修改的时间戳字段识别传入批次中的最新交易对我们来说是一项挑战。
我们尝试了多种方法来解决这个问题,通过使用 rank 函数或组合多个字段并选择正确的复合键。选择复合键在表中并不统一,并且可能需要不同的逻辑来识别最新的交易记录。
解决方案:
AWS Data Migration Service 可以配置为具有可以添加具有自定义或预定义属性的附加标头的转换规则。
ar_h_change_seq:来自源数据库的唯一递增数字,由时间戳和自动递增数字组成。该值取决于源数据库系统。
标头帮助我们轻松过滤掉重复记录,并且我们能够更新数据湖中的最新记录。标头将仅应用于正在进行的更改。对于全量加载,我们默认为记录分配了 0,在增量记录中,我们为每条记录附加了一个唯一标识符。我们在 precombine 字段中配置 ar_h_change_seq 以从传入批次中删除重复记录。
Hudi配置:
precombine = ar_h_change_seq
hoodie.datasource.write.precombine.field: precombine
hoodie.datasource.write.payload.class: 'org.apache.hudi.common.model.DefaultHoodieRecordPayload'
hoodie.payload.ordering.field: precombine
数据湖中的小文件问题
在构建数据湖时,会发生频繁的更新/插入,从而导致每个分区中都有很多小文件。
问题:
让我们看看小文件在查询时是如何导致问题的。当触发查询以提取或转换数据集时,Driver节点必须收集每个文件的元数据,从而导致转换过程中的性能开销。
解决方案:
定期压缩小文件有助于保持正确的文件大小,从而提高查询性能。而Apache Hudi 支持同步和异步压缩。
- 同步压缩:这可以在写入过程本身期间启用,这将增加 ETL 执行时间以更新 Hudi 中的记录。
- 异步压缩:压缩可以通过不同的进程来实现,并且需要单独的内存来实现。这不会影响写入过程,也是一个可扩展的解决方案。
在 Halodoc,我们首先采用了同步压缩。慢慢地,我们计划采用基于表大小、增长和用例的混合压缩。
Hudi配置:
hoodie.datasource.clustering.inline.enable
hoodie.datasource.compaction.async.enable
保持存储大小以降低成本
数据湖很便宜,并不意味着我们应该存储业务分析不需要的数据。否则我们很快就会看到存储成本越来越高。 Apache Hudi 会在每个 upsert 操作中维护文件的版本,以便为记录提供时间旅行查询。每次提交都会创建一个新版本的文件,从而创建大量版本化文件。
问题:
如果我们不启用清理策略,那么存储大小将呈指数增长,直接影响存储成本。如果没有业务价值,则必须清除较旧的提交。
解决方案:
Hudi 有两种清理策略,基于文件版本和基于计数(要保留的提交数量)。在 Halodoc,我们计算了写入发生的频率以及 ETL 过程完成所需的时间,基于此我们提出了一些要保留在 Hudi 数据集中的提交。
示例:如果每 5 分钟安排一次将数据摄取到 Hudi 的作业,并且运行时间最长的查询可能需要 1 小时才能完成,则平台应至少保留 60/5 = 12 次提交。
Hudi配置:
hoodie.cleaner.policy: KEEP_LATEST_COMMITS
hoodie.cleaner.commits.retained: 12
或者
hoodie.cleaner.policy: KEEP_LATEST_FILE_VERSIONS
hoodie.cleaner.fileversions.retained: 1
根据延迟和业务用例选择正确的存储类型
Apache Hudi 有两种存储类型,用于存储不同用例的数据集。一旦选择了一种存储类型,更改/更新到另外一种类型可能是一个繁琐的过程(CoW变更为MoR相对轻松,MoR变更为CoW较为麻烦)。因此在将数据迁移到 Hudi 数据集之前选择正确的存储类型非常重要。
问题:
选择不正确的存储类型可能会影响 ETL 执行时间和数据消费者的预期数据延迟。
解决方案:
在 Halodoc我们将这两种存储类型都用于我们的工作负载。
MoR:MoR 代表读取时合并。我们为写入完成后需要即时读取访问的表选择了 MoR。它还减少了 upsert 时间,因为 Hudi 为增量更改日志维护 AVRO 文件,并且不必重写现有的 parquet 文件。
MoR 提供数据集 _ro 和 _rt 的 2 个视图。
- _ro 用于读取优化表。
- _rt 用于实时表。
CoW:CoW 代表写时复制。存储类型 CoW 被选择用于数据延迟、更新成本和写入放大优先级较低但读取性能优先级较高的数据集。
type = COPY_ON_WRITE / MERGE_ON_READ
hoodie.datasource.write.table.type: type
文件列表很繁重,Hudi如何解决
一般来说分布式对象存储或文件系统上的 upsert 和更新是昂贵的,因为这些系统本质上是不可变的,它涉及跟踪和识别需要更新的文件子集,并用包含最新记录的新版本覆盖文件。 Apache Hudi 存储每个文件切片和文件组的元数据,以跟踪更新插入操作的记录。
问题:
如前所述,在不同分区中有大量文件是Driver节点收集信息的开销,因此会导致内存/计算问题。
解决方案:
为了解决这个问题,Hudi 引入了元数据概念,这意味着所有文件信息都存储在一个单独的表中,并在源发生变化时进行同步。这将有助于 Spark 从一个位置读取或执行文件列表,从而实现最佳资源利用。
这些可以通过以下配置轻松实现。
Hudi配置
hoodie.metadata.enabled: true
为 Hudi 数据集选择正确的索引
在传统数据库中使用索引来有效地从表中检索数据。 Apache Hudi 也有索引概念,但它的工作方式略有不同。 Hudi 中的索引主要用于强制跨表的所有分区的键的唯一性。
问题:
想要构建事务数据湖时,维护/限制每个分区或全局分区中的重复记录始终至关重要
解决方案:
Hudi 通过使用 Hudi 数据集中的索引解决了这个问题,它提供全局和非全局索引。默认情况下使用Bloom Index。目前Hudi支持:
- Bloom Index:使用由记录键构建的Bloom过滤器,还可以选择使用记录键范围修剪候选文件。
- Simple Index:对存储表中的记录和传入更新/删除记录进行连接操作。
- Hbase Index:管理外部 Apache HBase 表中的索引映射。
在 Halodoc,我们利用全局 Bloom 索引,以便记录在分区中是唯一的,使用索引时必须根据源行为或是否有人想要维护副本做出决定。
总结
在 Halodoc过去 6 个月我们一直在使用 Apache Hudi,它一直很好地服务于大规模数据工作负载。 一开始为 Apache Hudi 选择正确的配置涉及一些学习曲线。
在这篇博客中,我们分享了我们在构建 LakeHouse 时遇到的一些问题,以及在生产环境中使用 Apache Hudi 时正确配置参数/配置的最佳实践。
Halodoc使用 Apache Hudi 构建 Lakehouse的关键经验的更多相关文章
- 使用Apache Pulsar + Hudi构建Lakehouse方案了解下?
1. 动机 Lakehouse最早由Databricks公司提出,其可作为低成本.直接访问云存储并提供传统DBMS管系统性能和ACID事务.版本.审计.索引.缓存.查询优化的数据管理系统,Lakeho ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入 大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的.遵循的基本原则之一是文件的"一次写入多次读取"访问模型.这对于处理 ...
- 使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于 Apache Hudi 构建增量和无限回放事件流的 OLAP 平台
1. 摘要 在本博客中,我们将讨论在构建流数据平台时如何利用 Hudi 的两个最令人难以置信的能力. 增量消费--每 30 分钟处理一次数据,并在我们的组织内构建每小时级别的OLAP平台 事件流的无限 ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
随机推荐
- Android 接入腾讯IM即时通信(详细图文)
原文地址:Android 接入腾讯IM即时通信(详细图文) | Stars-One的杂货小窝 腾讯云IM官网文档上提供了带UI模块和不带UI模块的,本文是基于带UI模块进行了Module封装,可以方便 ...
- 【零碎小bug系列】安卓开发是遇到空指针异常java.lang.NullPointerException: Attempt to invoke...
安卓开发是遇到空指针异常 java.lang.NullPointerException: Attempt to invoke virtual method 'android.text.Editable ...
- python---替换空格
""" 请实现一个函数,将一个字符串中的每个空格替换成"%20". 例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are ...
- SpringMVC-组件分析之视图解析器(prefix,suffix)
SpringMVC的默认组件都是在DispatcherServlet.properties配置文件中配置的: spring-webmvc->org/springframewrok/web/ser ...
- Infrastructure 知识: DNS 命令: dig, host
dig 基本用法: dig @server name type 或者用-t type来指定(更常见) dig @server -t type name 例子详解 # 最简单的使用 $ dig www. ...
- Java中时间类中的Data类与Time类
小简博客 - 小简的技术栈,专注Java及其他计算机技术.互联网技术教程 (ideaopen.cn) Data类 Data类中常用方法 boolean after(Date date) 若当调用此方法 ...
- 【生产事故调查】优化出来的bug-合并集合重复项
本来是要修复前一个代码bug,修复的过程中发现原本的代码又丑又长,复用性差(但是能用),出于强迫症忍不住的去优化,测试还不充分,火急火燎的发到生产了,结果掉井了!导致多个订单线下物流发货发多了.... ...
- [题解][YZOJ50113] 枇杷树
简要题意 \(m\) 个操作,每次操作都会产生一个树的版本 \((\)从 \(0\) 开始\()\). 一次操作把 \(x_i\) 版本的树的点 \(u\) 和 \(y_i\) 版本的树的点 \(v\ ...
- redis数据结构附录
引言 本次对上一次的数据结构知识进行补充,主要有redis数据结构的相关应用场景和内存相关知识 引用计数-内存 redis中的对象回收机制是采用引用计数的方式,首先我们可以通过redis对象结构体代码 ...
- RESTFul是一种风格
只要符合RESTFul风格的,都可以叫做使用了RESTFul架构,一般的网站里传数据,都是用的?a=1&b=2...如果是RESTFul风格的话,就会是/a/1/b/2..类似于这样的方式来传 ...