快速用梯度下降法实现一个Logistic Regression 分类器
前阵子听说一个面试题:你实现一个logistic Regression需要多少分钟?搞数据挖掘的人都会觉得实现这个简单的分类器分分钟就搞定了吧?
因为我做数据挖掘的时候,从来都是顺手用用工具的,尤其是微软内部的TLC相当强大,各种机器学习的算法都有,于是自从离开学校后就没有自己实现过这些基础的算法。当有一天心血来潮自己实现一个logistic regression的时候,我会说用了3个小时么?。。。羞羞
---------------------------------------------------前言结束----------------------------------------------
当然logistic regression的渊源还是有点深的,想复习理论知识的话可以去http://en.wikipedia.org/wiki/Logistic_regression , 我这里就直接讲实现啦。
首先要了解一个logistic function
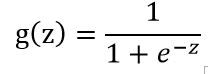
这个函数的图像是这个样子的:
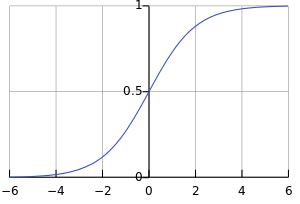
而我们要实现的logistic regression model,就是要去学习出一组权值w:
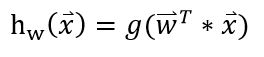
x 指feature构成的向量。 这个向量w就可以将每个instance映射到一个实数了。
假如我们要出里的是2分类问题,那么问题就被描述为学习出一组w,使得h(正样本)趋近于1, h(负样本)趋近于0.
现在就变成了一个最优化问题,我们要让误差最小化。 现在问题来了,怎么定义误差函数呢?
首先想到的是L2型损失函数啦,于是啪啪啪写上了
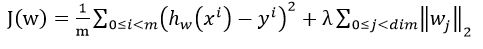 。
。
很久没有复习logistic regression的人最容易犯错的就是在这了。正确的写法是:
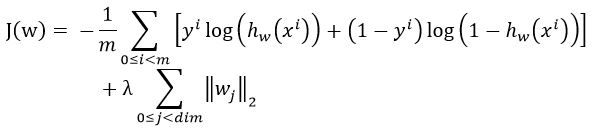 ,
,
然后对它求偏导数得到梯度下降法的迭代更新方程:
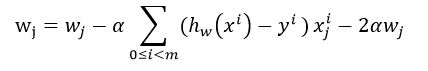 。
。
于是你会发现这个迭代方程是和线性回归的是一样的!
理清了过程时候,代码就变得异常简单了:
public class LogisticRegression
{
private int _maxIteration = ;
private double _stepSize = 0.000005;
//private double _stepSize = 0.1;
private double _lambda = 0.1;
private double decay = 0.95; public int dim;
public double[] theta; public LogisticRegression(int dim)
{
this.dim = dim;
} public LogisticRegression(int dim, double stepSize)
: this(dim)
{
this._stepSize = stepSize;
} public void Train(Instance[] instances)
{
Initialize(); int instCnt = instances.Length;
double[] dev =new double[this.dim];
for (int t = ; t < this._maxIteration; t++)
{
double cost = ;
for (int i = ; i < instCnt; i++)
{
double h_x = MathLib.Logistic(MathLib.VectorInnerProd(instances[i].featureValues, this.theta));
// calculate cost function
cost += instances[i].label * Math.Log(h_x) + ( - instances[i].label) * Math.Log( - h_x);
}
cost *= -1.0 / instCnt;
Console.WriteLine("{0},{1}", t, cost); for (int i = ; i < instCnt; i++)
{
ResetArray(dev);
double h_x = MathLib.Logistic(MathLib.VectorInnerProd(instances[i].featureValues, this.theta));
double error = h_x- instances[i].label ;
for (int j = ; j < this.dim; j++)
{
dev[j] += error*instances[i].featureValues[j] + *dev[j]*this._lambda;
this.theta[j] -= this._stepSize * dev[j] ;
//BoundaryLimiting(ref this.theta[j], 0, 1);
}
}
//this._stepSize *= decay;
//if (this._stepSize > 0.000001)
//{
// this._stepSize = 0.000001;
//}
}
} private void BoundaryLimiting(ref double alpha, double lowerbound, double upperbound)
{
if (alpha < lowerbound)
{
alpha = lowerbound;
}
else if (alpha > upperbound)
{
alpha = upperbound;
}
} public double[] Predict(Instance[] instances)
{
double[] results = new double[instances.Length];
for (int i = ; i < results.Length; i++)
{
results[i] = MathLib.Logistic(MathLib.VectorInnerProd(instances[i].featureValues, this.theta));
}
return results;
} private void ResetArray(double[] dev)
{
for (int i = ; i < dev.Length; i++)
{
dev[i] = ;
}
} private void Initialize()
{
Random ran = new Random(DateTime.Now.Second); this.theta = new double[this.dim];
for (int i = ; i < this.dim; i++)
{
this.theta[i] = ran.NextDouble() * ; // initialize theta with a small value
}
} public static void Test()
{
LogisticRegression lr = new LogisticRegression(); List<Instance> instances = new List<Instance>();
using (StreamReader rd = new StreamReader(@"D:\\local exp\\data.csv"))
{
string content = rd.ReadLine();
while ((content = rd.ReadLine()) != null)
{
instances.Add(Instance.ParseInstance(content,','));
}
} // MinMaxNormalize(instances); lr.Train(instances.ToArray()); } private static void MinMaxNormalize(List<Instance> instances)
{
int dim = instances[].dim;
double[] min = new double[dim];
double[] max = new double[dim]; int instCnt = instances.Count;
for (int i = ; i < instCnt; i++)
{
for (int j = ; j < dim; j++)
{
if (i == || instances[i].featureValues[j] < min[j])
{
min[j] = instances[i].featureValues[j];
}
if (i == || instances[i].featureValues[j] > max[j])
{
max[j] = instances[i].featureValues[j];
}
}
} for (int j = ; j < dim; j++)
{
double gap = max[j] - min[j];
if (gap <= )
{
continue;
}
for (int i = ; i < instCnt; i++)
{
instances[i].featureValues[j] = (instances[i].featureValues[j] - min[j]) / gap;
}
} }
}
前面提到说我花了3个小时,其中很大一部分原因是在debug算法为啥没有收敛。这里有个很重要的步骤是把feature规范化到[0,1] 。 如果不normalize的话,参数调起来比较麻烦,loss function也经常蹦到NaN去了。
以下是对比normalize和不加normalization的收敛曲线图:
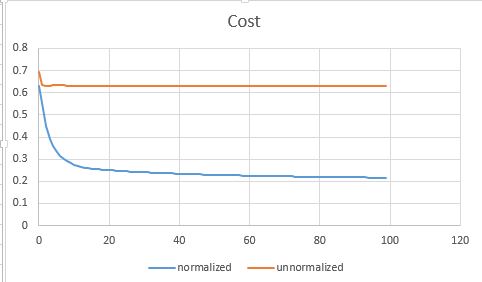
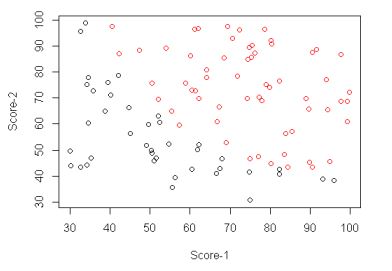
我用的实现数据可以在 http://pingax.com/wp-content/uploads/2013/12/data.csv 下载到。 它是一个2维的数据, 分布如下:
快速用梯度下降法实现一个Logistic Regression 分类器的更多相关文章
- Logistic Regression分类器
1. 两类Logistic回归 Logistic回归是一种非常高效的分类器.它不仅可以预测样本的类别,还可以计算出分类的概率信息. 不妨设有$n$个训练样本$\{x_1, ..., x_n\}$,$x ...
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
原文:http://blog.csdn.net/abcjennifer/article/details/7716281 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 李宏毅机器学习笔记3:Classification、Logistic Regression
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- Python机器学习笔记 Logistic Regression
Logistic回归公式推导和代码实现 1,引言 logistic回归是机器学习中最常用最经典的分类方法之一,有人称之为逻辑回归或者逻辑斯蒂回归.虽然他称为回归模型,但是却处理的是分类问题,这主要是因 ...
- 梯度下降法原理与python实现
梯度下降法(Gradient descent)是一个一阶最优化算法,通常也称为最速下降法. 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离 ...
- 梯度下降法(BGD、SGD)、牛顿法、拟牛顿法(DFP、BFGS)、共轭梯度法
一.梯度下降法 梯度:如果函数是一维的变量,则梯度就是导数的方向: 如果是大于一维的,梯度就是在这个点的法向量,并指向数值更高的等值线,这就是为什么求最小值的时候要用负梯度 梯度下降法(Gr ...
- 使用Logistic Regression Algorithm进行多分类数字识别的Octave仿真
所需解决的问题是,训练一个Logistic Regression系统,使之能够识别手写体数字1-10,每张图片为20px*20px的灰度图.训练样例的输入X是5000行400列的一个矩阵,每一行存储一 ...
- pytorch梯度下降法讲解(非常详细)
pytorch随机梯度下降法1.梯度.偏微分以及梯度的区别和联系(1)导数是指一元函数对于自变量求导得到的数值,它是一个标量,反映了函数的变化趋势:(2)偏微分是多元函数对各个自变量求导得到的,它反映 ...
- Logistic Regression - Formula Deduction
Sigmoid Function \[ \sigma(z)=\frac{1}{1+e^{(-z)}} \] feature: axial symmetry: \[ \sigma(z)+ \sigma( ...
随机推荐
- python并发编程之守护进程、互斥锁以及生产者和消费者模型
一.守护进程 主进程创建守护进程 守护进程其实就是'子进程' 一.守护进程内无法在开启子进程,否则会报错二.进程之间代码是相互独立的,主进程代码运行完毕,守护进程也会随机结束 守护进程简单实例: fr ...
- 菜鸟vimer成长记——第3章、文件
上一章一直在讲的是vim的文本的操作,本章主要讲的是vim的文件操作. 本章的有些概念和传统的文本编辑器也不尽相同.所以需要注意概念或者切切说是思维习惯的区别. vim 允许在一个编辑会话中编辑多个文 ...
- NO--19 微信小程序之scroll-view选项卡与跳转(二)
本篇为大家介绍为何我们在最后做交互的时候,并没有使用上一篇讲的选项卡的效果. scroll-view与跳转.gif (如无法查看图片,还请翻看上一篇!) 大家注意看,在我点击跳转后,首先能看到的是 ...
- 我是如何自学 Python 的?
最近一直有读者私信问我,Ahab你是如何学习Python的?能推荐几本适合新手学习的书吗?有没有好的实践项目分享一下呢? Python未来发展前景怎么样呀?今天我就认真的告诉大家我是如何学习Pytho ...
- dstat 性能测试工具常用选项
dstat常用的选项有: -c 显示cpu使用情况 -d 显示磁盘使用情况 -g, 显示页面数据 -i 启用中断数据 -l 平均负载统计(1分钟,5分钟,1 ...
- Linux shell中&,&&,|,||的用法
前言 在玩dvwa的命令注入漏洞的时候,遇到了没有预料到的错误,执行 ping 127.0.0.1 & echo "<?php phpinfo(); ?>" & ...
- ffplay.exe操作方式
大牛博客: 博文名称:[总结]FFMPEG视音频编解码零基础学习方法 博文链接:http://blog.csdn.net/leixiaohua1020/article/details/15811977 ...
- nginx 在ubuntu上使用笔记(绑定域名)
1. 重启nginx的两个语句: sudo service nginx restart sudo nginx -s reload 2. nginx配置文件路径: etc/nginx/ 尤其是 site ...
- django_models后台管理myarya
arya重点代码 # urls.py from django.urls import path,re_path,include from arya.service import v1 urlpatte ...
- 使用Spring boot 嵌入的tomcat不能启动: Unregistering JMX-exposed beans on shutdown
新建一个spring boot的web项目,运行之后控制台输出“Unregistering JMX-exposed beans on shutdown”,tomcat也没有运行.寻找原因,看了下pom ...