Java:ConcurrentHashMap类小记-3(JDK8)
Java:ConcurrentHashMap类小记-3(JDK8)
结构说明
// 所有数据都存在table中, 只有当第一次插入时才会被加载,扩容时总是以2的倍数进行
transient volatile Node<K,V>[] table;
// 在扩容时存放变量,结束后置为null
private transient volatile Node<K,V>[] nextTable;
// 以volatile修饰的sizeCtl用于数组初始化与扩容控制,☆后续说明☆
private transient volatile int sizeCtl;
构造函数
在 JDK8 的 ConcurrentHashMap 中一共有5个构造方法,这四个构造方法中都没有对内部的数组做初始化, 只是对一些变量的初始值做了处理
JDK8 的 ConcurrentHashMap 的数组初始化是在第一次添加元素时完成
// 构造函数1:默认构造函数,没有维护任何变量的操作,如果调用该方法,数组长度默认是16
public ConcurrentHashMap() {
}
// 传递进来一个初始容量,ConcurrentHashMap会基于这个值计算一个比这个值大的2的幂次方数作为初始容量
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
// 计算初始容量,下面对其做了进一步分析
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
// 注意:上述代码中的
initialCapacity + (initialCapacity >>> 1) + 1
// 初始容量 + 初始容量/2 + 1
注意,调用这个方法,得到的初始容量和我们之前讲的 HashMap 以及 JDK7 的ConcurrentHashMap 不同,即使你传递的是一个2的幂次方数,该方法计算出来的初始容量依然是比这个值大的2的幂次方数
如:当传入的值为16时,此时初始化的大小为32
// 调用了下一个构造函数
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
// 构造函数4
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
// 判断参数合法性
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
// 计算尺寸,由于 /loadFactor + 1 因此必然会大于等于传入的initialCapacity
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
// 基于一个Map集合,构建一个ConcurrentHashMap
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
sizeCtl
注意:以上这些构造方法中,都涉及到一个变量sizeCtl,这个变量是一个非常重要的变量,而且具有非常丰富的含义,它的值不同,对应的含义也不一样,这里先对这个变量不同的值的含义做一下说明,后续源码分析过程中,进一步解释
- 当数组未初始化时:
0:未指定初始化容量,此时数组的初始容量为 16>0:由指定的初始容量计算而来,再找最近的2的幂次方
- 当数组初始化中/在扩容:
=-1:正在初始化=-N:并且不是 -1,表示数组正在扩容, -(1+n) 表示此时有n个线程正在共同完成数组的扩容操作
- 初始化完成:
=table.length * 0.75:那么其记录的是数组的扩容阈值,数组的初始容量*扩容因子
table
对 table 进一步说明:
table[i]存放的数据类型有以下3种:
Node普通结点类型,表示链表头结点;static class Node<K,V> implements Map.Entry<K,V>TreeBin用于包装红黑树结构的结点类型static final class TreeBin<K,V> extends Node<K,V>ForwardingNode扩容时存放的结点类型,并发扩容的实现关键之一static final class ForwardingNode<K,V> extends Node<K,V>
put 过程
源码分析
put() 方法
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 如果有空值或者空键,直接抛异常
if (key == null || value == null) throw new NullPointerException();
// 1. 根据key的hash值,再通过spread得出一个hash值,用于定位
// 由于通过了☆spread☆,使得这个值一定是正数,方便后面添加元素判断该节点的类型
int hash = spread(key.hashCode());
// 2. 记录某个桶上元素的个数,如果超过8个,会转成红黑树
int binCount = 0;
// 3. CAS经典写法,不成功无限重试,即是一个死循环
for (Node<K,V>[] tab = table;;) {
// f:hash表中对应桶位置的头结点 fh:f的hash值
Node<K,V> f; int n, i, fh;
// 4. 除非构造时指定初始化集合,否则默认构造不初始化table
// 即:在第一次添加元素时才初始化,☆initTable☆
if (tab == null || (n = tab.length) == 0)
// ☆initTable☆初始化方法,后续分析
tab = initTable();
// 5. 如果hash计算得到的桶位置没有元素,说明没有发生冲突,利用cas添加元素
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// cas+自旋(和外侧的for构成自旋循环),保证元素添加安全
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
// 成功添加跳出循环
break; // no lock when adding to empty bin
}
// 6.如果hash计算得到的桶位置元素的hash值为MOVED=-1,,
// 说明现在正在扩容, 那么协助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 7. hash计算的桶位置元素不为空,且当前没有处于扩容操作,则进行元素添加
else {
V oldVal = null;
// ☆☆☆对当前桶进行加锁,保证线程安全,执行元素添加操作,这里用了DCL机制
synchronized (f) {
// 双重检查i处结点未变化,即节点未被树化/发生扩容
if (tabAt(tab, i) == f) {
// 普通链表节点
if (fh >= 0) {
binCount = 1;
// 循环遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
// onlyIfAbsent表示是新元素才加入,旧值不替换,默认为fase。
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
// jdk1.8 版本是把新结点加入链表尾部,next由volatile修饰
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 树节点,将元素添加到红黑树中
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 链表长度大于/等于8,将链表转成红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
// 当旧的值不为null,返回
return oldVal;
break;
}
}
}
// 添加的是新元素,维护集合长度,并判断是否要进行扩容操作,☆后续分析☆
addCount(1L, binCount);
return null;
}
// ☆spread方法☆
static final int spread(int h) {
// static final int HASH_BITS = 0x7fffffff // 符号位为0 & 后必为0
return (h ^ (h >>> 16)) & HASH_BITS;
}
// 上述的tabAt/casTabAt方法,包括后续使用的setTabAt方法
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
// U为Unsafe类,((long)i << ASHIFT) + ABASE获取数组对应索引位置的元素
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
// cas添加值
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
// 将对应的node放入对应的位置
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
通过以上源码,我们可以看到,当需要添加元素时,会针对当前元素所对应的桶位进行加锁操作,这样一方面保证元素添加时,多线程的安全,同时对某个桶位加锁不会影响其他桶位的操作,进一步提升多线程的并发效率
initTable() 方法
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
// cas+自旋,保证线程安全,对数组进行初始化操作
while ((tab = table) == null || tab.length == 0) {
// 如果sizeCtl的值(-1)小于0,说明此时正在初始化, 让出cpu
if ((sc = sizeCtl) < 0)
// 有线程在执行初始化操作,我让出CPU的执行权
Thread.yield(); // lost initialization race; just spin
// cas修改sizeCtl的值为-1,修改成功,进行数组初始化,失败,继续自旋
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 双重检测的意思,DCL,进一步保证线程的安全
if ((tab = table) == null || tab.length == 0) {
// sizeCtl为0,取默认长度16,否则去sizeCtl的值
// 大于0说明给了初始值
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 基于初始长度,构建数组对象
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 计算扩容阈值,并赋值给sc n>>>2 n向右移两位
sc = n - (n >>> 2); // 等价 0.75 * n
}
} finally {
// 将扩容阈值,赋值给sizeCtl
sizeCtl = sc;
}
break;
}
}
return tab;
}
图解
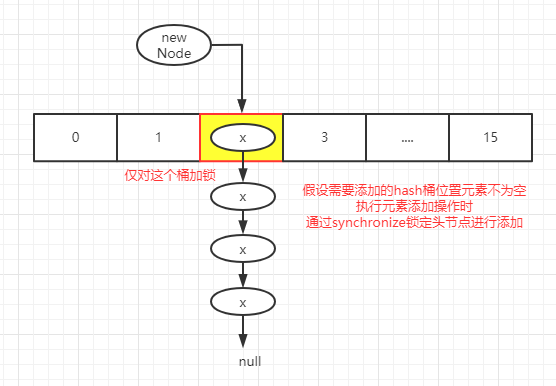
说明
后续还有扩容维护数组长度等内容,待完善...
Java:ConcurrentHashMap类小记-3(JDK8)的更多相关文章
- Java:ConcurrentHashMap类小记-2(JDK7)
Java:ConcurrentHashMap类小记-2(JDK7) 对 Java 中的 ConcurrentHashMap类,做一个微不足道的小小小小记,分三篇博客: Java:ConcurrentH ...
- Java:ConcurrentHashMap类小记-1(概述)
Java:ConcurrentHashMap类小记-1(概述) 对 Java 中的 ConcurrentHashMap类,做一个微不足道的小小小小记,分三篇博客: Java:ConcurrentHas ...
- Java:HashMap类小记
Java:HashMap类小记 对 Java 中的 HashMap类,做一个微不足道的小小小小记 概述 HashMap:存储数据采用的哈希表结构,元素的存取顺序不能保证一致.由于要保证键的唯一.不重复 ...
- Java:TreeMap类小记
Java:TreeMap类小记 对 Java 中的 TreeMap类,做一个微不足道的小小小小记 概述 前言:之前已经小小分析了一波 HashMap类.HashTable类.ConcurrentHas ...
- Java:HashTable类小记
Java:HashTable类小记 对 Java 中的 HashTable类,做一个微不足道的小小小小记 概述 public class Hashtable<K,V> extends Di ...
- Java:LinkedHashMap类小记
Java:LinkedHashMap类小记 对 Java 中的 LinkedHashMap类,做一个微不足道的小小小小记 概述 public class LinkedHashMap<K,V> ...
- Java:LinkedList类小记
Java:LinkedList类小记 对 Java 中的 LinkedList类,做一个微不足道的小小小小记 概述 java.util.LinkedList 集合数据存储的结构是循环双向链表结构.方便 ...
- Java:ArrayList类小记
Java:ArrayList类小记 对 Java 中的 ArrayList类,做一个微不足道的小小小小记 概述 java.util.ArrayList 是大小可变的数组的实现,存储在内的数据称为元素. ...
- Java:ThreadLocal小记
Java:ThreadLocal小记 说明:这是看了 bilibili 上 黑马程序员 的课程 java基础教程由浅入深全面解析threadlocal 后做的笔记 内容 ThreadLocal 介绍 ...
随机推荐
- Vuex的同步异步存值取值
1. vue中各个组件之间传值 1.父子组件 父组件-->子组件,通过子组件的自定义属性:props 子组件-->父组件,通过自定义事件:this.$emit('事件名',参数1,参数2, ...
- 这款打怪升级的小游戏,7 年前出生于 GitHub 社区,如今在谷歌商店有 8 万人打了满分
今天我在 GitHub 摸鱼寻找新的"目标"时,发现了一个开源项目是 RougeLike 类的角色扮演游戏「破碎版像素地牢」(Shattered Pixel Dungeon)类似魔 ...
- DSP开发笔记一
前言 本笔记首先对DSP的特点及其选型进行了描述,然后重点记录DSP开发环境的搭建及基础工程示例,对为DSP开发新手有一定的指导作用. 1. DSP简介 1.1 主要特点 在一个指令周期内可完成一 ...
- aes加解密前后端-后台
一.web.xml: <filter> <filter-name>fastLoginFilter</filter-name> <filter-class> ...
- 从零开始学习SQL SERVER(2)--- 基本操作及语句
声明:仅为本人随笔及经验之谈,有错误敬请指出. # 后的文字为注释 Microsoft SQL Server Management Studio 中的SQL命令 添加数据库 1 CREATE DATA ...
- PHP中的MySQLi扩展学习(一)MySQLi介绍
关于 PDO 的学习我们告一段落,从这篇文章开始,我们继续学习另外一个 MySQL 扩展,也就是除了 PDO 之外的最核心的 MySQLi 扩展.可以说它的祖先,也就是 MySQL(原始) 扩展是我们 ...
- django对layui中csrf_token处理方式及其它一些处理
第一:由于layui官方是没有csrf_token处理机制,所以,在使用layui中post请求,请不要按layui官方提供的两种方法进行设置 官方设置如下: table.render({ elem: ...
- LR集合点策略
给大家分享一个LR集合点策略,跑并发脚本时,一定要设置策略,要不然得出的响应时间无意义.默认选择第一个(当所有虚拟用户中的x % 到达集合点进释放,即仅当指定百分比的虚拟用户到达集合点时,才释放虚拟用 ...
- 关于Python中的深浅拷贝
之前一直认为浅拷贝是拷贝内容的第一层,但是不开辟内存,只是增加新的指向原来的内容:深拷贝是拷贝是拷贝每一层并开辟内存. 其实这个是不严谨的不正确的. 从以上可以看出,浅拷贝中当时可变类型的时候,内存是 ...
- P4199-万径人踪灭【FFT】
正题 题目链接:https://www.luogu.com.cn/problem/P4199 题目大意 给出一个只包含\(a,b\)的字符串 求有多少个不连续的回文子序列(字母回文,位置对称) \(1 ...