大数据学习(17)—— HBase表设计
为啥要把表设计拿出来独立成章?因为我觉得像我这样搞了很多年Java后端开发的技术人员,在学习HBase的时候,会受到关系型数据库3NF、BCNF的影响。事实上,数据库范式在HBase里完全没用,必须转变思想。因此把这一点单独写出来,供类似情况的技术人员参考。
HBase逻辑视图
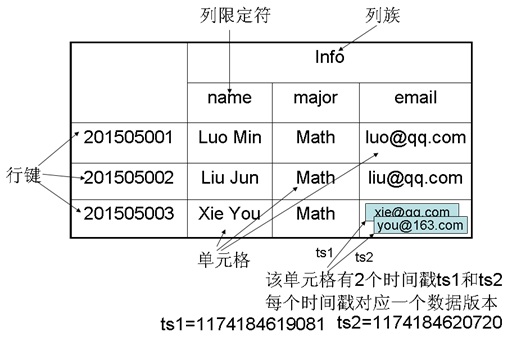
这个图看起来像是Excel表格,不同的是,它的一个单元格可以有多个版本的数据,这是HBase的多版本特性,默认版本数是1。实际存储格式是每个单元格一行记录,如下图。
hbase(main):003:0> scan 'test'
ROW COLUMN+CELL
rowkey1 column=cf:level, timestamp=1608108298860, value=P9
rowkey1 column=cf:name, timestamp=1607677762394, value=guanyu
rowkey2 column=cf:salary, timestamp=1607328820620, value=200w
rowkey3 column=cf:corp, timestamp=1607330730061, value=Alibaba
rowkey4 column=cf:name, timestamp=1607331563986, value=XiaoYaoZi
4 row(s)
Took 1.7952 seconds
我们再来看看存放在HDFS里的hfile文件内容。
[hadoop@server01 hadoop]$ hbase hfile -p -f /hbase/data/default/test/bc89689612a0269a2216349bd23133ec/cf/c66c7553a5d6488a9e1e57ca2b0a5577
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hbase-2.2.6/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2020-12-16 18:30:46,116 INFO [main] metrics.MetricRegistries: Loaded MetricRegistries class org.apache.hadoop.hbase.metrics.impl.MetricRegistriesImpl
K: rowkey1/cf:level/1608108298860/Put/vlen=2/seqid=27 V: P9
K: rowkey1/cf:name/1607677762394/Put/vlen=6/seqid=14 V: guanyu
K: rowkey2/cf:salary/1607328820620/Put/vlen=4/seqid=0 V: 200w
K: rowkey3/cf:corp/1607330730061/Put/vlen=7/seqid=0 V: Alibaba
K: rowkey4/cf:name/1607331563986/Put/vlen=9/seqid=0 V: XiaoYaoZi
Scanned kv count -> 5
这个文件可以很明显地看出,它是一个键值存储系统,键包含rowkey、列族、列名(列标识符)、时间戳、数据类型(Put、Delete)、字符数组长度、seqid。值就是单元格存储的值。
这个键占用了大量的空间,而且不同数据它们的列族列名完全是一样的,太浪费空间了,这就需要用到HBase的压缩,压缩方式请自行查看官网。
seqid是个什么东西?百度了一下,可能是一个时间序列的标识,提示老的HLog是否可以删除。
HBase表设计原则
- 行键根据需求来设计,尽量短,尽量只调用一次API就可以完成需求。
- HBase原生语法不支持表join操作,适当使用冗余来简化查询操作。
- 列名(列标识符)可以存储数据,每一条记录的列名可以完全不同,但是尽量短。
表设计实战
以微博关注为例来做一个小小的表设计,可能与微博实际不符,仅用于说明设计方法。
关注关系如下:
景天关注重楼、龙葵、雪见
飞蓬关注景天、重楼
重楼关注飞蓬、紫萱
龙葵关注景天
雪见关注景天
紫萱关注雪见
这是一个多对多的关系,如果是关系型数据库,至少要两张表来存放。一张表存放人物信息,一张表存放人物关注关系。
时刻要想到,HBase没有join操作,只能用一张表来存放关注和被关注的信息,这肯定会存在数据冗余。不要怕,HBase可以支持十亿级别的列和百万级别的行,冗余不是问题。
我们可以这么设计
| 行键 | 列族cf1(关注谁) | 列族cf2(被谁关注) |
| 001_景天 | cf1:003=重楼,cf1:004=龙葵,cf1:005=雪见 | cf2:002=飞蓬,cf2:004=龙葵,cf2:005=雪见 |
| 002_飞蓬 | cf1:001=景天,cf1:003=重楼 | cf2:003=重楼 |
| 003_重楼 | cf1:002=飞蓬,cf1:006=紫萱 | cf2:001=景天,cf2:002=飞蓬 |
| 004_龙葵 | cf1:001=景天 | cf2:001=景天 |
| 005_雪见 | cf1:001=景天 | cf2:001=景天,cf2:006=紫萱 |
| 006_紫萱 | cf1:005=雪见 | cf2:003=重楼 |
是不是惊呆了,这都什么玩意。这种设计可以只用一次API调用就查出每个人关注了谁,每个人被谁关注了,按照需求来合理设计。
大数据学习(17)—— HBase表设计的更多相关文章
- HBase学习——3.HBase表设计
1.建表高级属性 建表过程中常用的shell命令 1.1 BLOOMFILTER 默认是 NONE 是否使用布隆过虑及使用何种方式,布隆过滤可以每列族单独启用 使用HColumnDescriptor. ...
- 大数据学习笔记——HBase使用bulkload导入数据
HBase使用bulkload批量导入数据 HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导 ...
- 大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程 本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始! 1. 安装准备 部署Hba ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习(13)—— HBase入门
从这一篇起,开始介绍HBase相关知识.还是一样,大数据的学习,获取官网知识很重要.官网看这里Apache HBase HBase简介 Apache HBase is the Hadoop datab ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
随机推荐
- Jenkins 流水线远程部署 .NET Core/Framework 到 IIS
目录 Windows 安装 Git WebDeploy Windows 从节点 .NET Core 处理 IIS 处理项目 Jenkinsfile .NET Framework 安装环境 .NET F ...
- 铂金07:整齐划一-CountDownLatch如何协调多线程的开始和结束
欢迎来到<并发王者课>,本文是该系列文章中的第20篇. 在上一篇文章中,我们介绍了Condition的用法.在本文中,将为你介绍CountDownLatch的用法.CountDownLat ...
- ceph-csi源码分析(2)-组件启动参数分析
更多ceph-csi其他源码分析,请查看下面这篇博文:kubernetes ceph-csi分析目录导航 ceph-csi源码分析(2)-组件启动参数分析 ceph-csi组件的源码分析分为五部分: ...
- 温故知新,.Net Core利用UserAgent+rDNS双解析方案,正确识别并反爬虫/反垃圾邮件
背景 一般有价值的并保有数据的网站或接口很容易被爬虫,爬虫会占用大量的流量资源,接下来我们参考历史经验,探索如何在.Net Core中利用UserAgent+rDNS双解析方案来正确识别并且反爬虫. ...
- UI自动化学习笔记- Selenium元素等待(强制等待、显示等待、隐式等待)
一.元素等待 1. 元素等待 1.1 什么是元素等待 概念:在定位页面元素时如果未找到,会在指定时间内一直等待的过程 意思就是:等待指定元素已被加载出来之后,我们才去定位该元素,就不会出现定位失败的现 ...
- Jsp自定义标签,配置tld文件
Program:Jsp自定义标签,.tld文件的配置 1 <?xml version="1.0" encoding="UTF-8" ?> 2 3 & ...
- error more than one devices and emulator
问题秒速 莫名的多了一个设备,然后再输入adb shell 解决方法: 1.如果确实有多种设备,要指定设备号 adb -s 设备号 shell(设备号在这里是 emulator-5554,其他同理) ...
- Leetcode No.26 Remove Duplicates from Sorted Array(c++实现)
1. 题目 1.1 英文题目 Given an integer array nums sorted in non-decreasing order, remove the duplicates in- ...
- 26. Remove Duplicates from Sorted Array*(快慢指针)
description: Given a sorted array nums, remove the duplicates in-place such that each element appear ...
- 从零开始给女朋友讲计算机 1 - 从比特、字节、补码到 ASCII、GB2312、Unicode
起因 在代码 review 的过程中,总是发现有人在数据类型转换(reinterpret_cast).大小端的问题(什么情况下需要考虑大小端,什么情况下不需要考虑)上犯错误,究其原因是没有彻彻底底地搞 ...