论文笔记: LSTD A Low-Shot Transfer Detector for Object Detection
背景知识:
Zeroshot Learning,零次学习。
模型 对于 训练集 中 没有出现过 的 类别,能自动创造出相应的映射: X→Y。
Low/Few-shot Learning、One-shot Learning,少/一次学习。
训练集中,每个类别 都有样本,但都只是 少量样本 (甚至只有一个)。
摘要:
提出了一个Low-Shot Transfer Detector (LSTD),利用丰富的源领域(Source Domain)知识来构建一个高效的目标域(Target Domain)检测器(几乎不需要训练样例)。
主要贡献:
- 设计了一个灵活的LSTD深层架构,以缓解Low-Shot检测中的tranfer困难。同时,该架构结合了SSD和Faster RCNN各自的优势。
- 其次,提出了一种新的 transfer learning framework,其中包括 Transfer Knowledge (转移指数 TK)和 Background Depression (背景抑制 BD)正则化方法,可以分别从源域和目标域利用目标知识,加强fine-tune 。
以前的解决方法:
- weakly/semi-supervised. 引入额外的易于注释的标签图像。缺点:由于训练集的缺乏监督,检测器的效果往往受限。 弱监督:有标签没有框;半监督:有标签,部分有框。
- 对深度模型进行迁移学习。缺点:(1)当目标检测数据集很小的时候,对目标检测使用一般的迁移策略是不适用的(例如,简单的使用预训练的深度分类模型来初始化深度检测模型)。在很小的数据集上进行微调时,通常很难分辨检测和分类之间的区别。(2)在迁移学习中,深度检测模型比深度分类模型更容易出现过拟合。(3)简单的微调通常会降低可转移度(经常会忽略源域和目标域都具有的重要的目标知识)。
TK和BD的主要作用:
TK:对每一个目标域的 proposal 迁移源域目标标签知识,使得能够在目标域中泛化Low-shot Learning。
BD:在目标域图片的特征图上加入bounding box knowledge来做额外监督,使得模型在transferring中能够抑制背景的干扰,专注于目标。
网络的基本结构:

图1
First, we design bounding box regression in the fashion of SSD.
利用SSD设计bounding box regression。每一卷积层都有默认的候选框,每一层都用smooth L1来对框的回归进行训练。
- 训练数据:large-scale source domain
- 训练目的:为了学习尺度的多样性(少样本缺少的信息),避免重新初始化bbox回归,减少target domain时的fine-tuning负担
Second, we design object classification in the fashion of Faster RCNN.
用Faster RCNN设计object classification。这里就是将原始Faster RCNN的框的回归换成了SSD的多尺度框的回归,原始的RoI层中的特征层用SSD的卷积的中层特征代替。
实现流程如下:
- 根据SSD部分的objects的分数排序,选出region proposals筛选作为RPN的结果
- 使用ROI pooling层的middle-level卷积层,为每个proposal产生固定大小的卷积特征cube
- 不使用原有的faster rcnn的全连接层,而是在ROI pooling layer使用两个卷积层,用于K+1分类。
优势:
- 当参数较少时,减少了过拟合。
- 与直接的K+1类分类相比,粗到细分类,减少了迁移学习的训练难度。
- 相较于背景来说,source 和 target中的物体共享一些相同的特性(例如清晰的边缘,均匀的质地)。
Regularized Transfer Learning for LSTD:
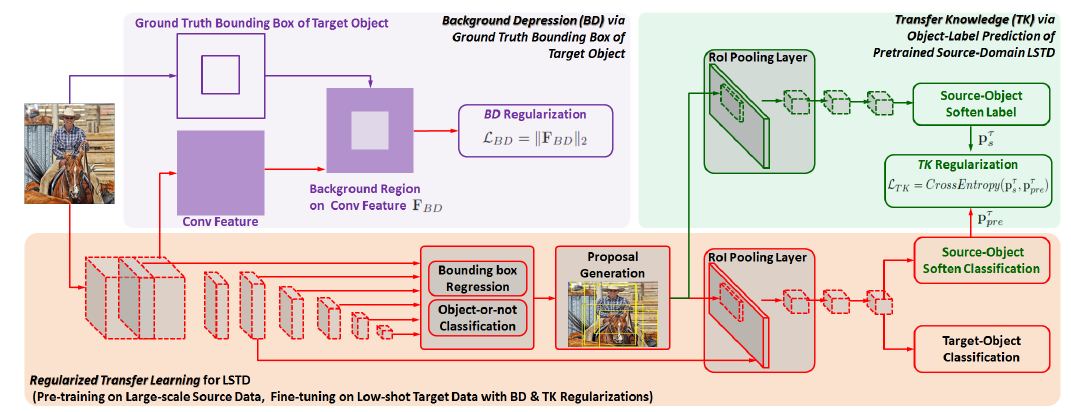
图2
- train the source-domain LSTD with a large-scale source data set.
- initialize the target-domain LSTD using the pretrained source-domain LSTD.
- use the small-scale target data to fine-tune the target-domain LSTD with the proposed low-shot detection regularization.
具体来说,首先用大量的source data 训练图1中的模型,得到pretained source-domain LSTD;然后用该模型初始化 target-domain LSTD;最后用文章提出的正则化方法在target-domain中fine-tune经过初始化的target-domain LSTD。
fine-tune过程中总的损失函数如下:

其中,L_main 指在LSTD中的多个尺度层的回归损失和微调目标分类的损失(即后面的两个卷积)。(源域与目标域相关但不同,因为low-shot旨在从少量目标数据中检测出之前没有出现过的类别)。因此在目标域中需要重新初始化,即源域训练好的用来当做目标域的初始化,然后来进行微调。
为了进一步在目标域中加强low-shot detection,加入了新的正则项:L_reg,形式如下:
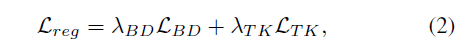
其中,L_BD,L_TK分别为背景抑制和知识迁移正则项。
Background-Depression (BD) Regularization:
由于复杂的背景信息会影响localization性能,所以在目标域中用object knowledge 设计了BD正则化。具体的,首先从卷积的中间层生成特征立方(candidate boxes) ,然后用groud truth bounding boxes取匹配框,去除掉这个匹配框,仅保留与背景对应的特征区域,即F_BD。最后使用L2正则化惩罚激活的F_BD。从而抑制背景信息,在仅有的target数据中更关注target的物体信息。
BD的作用:

Transfer-Knowledge (TK) Regularization:
由于源域与目标域的类别不同,所以在目标域中就要微调。但是如果只用目标域的数据进行微调,就不能充分利用源域的知识。所以提出了TK正则化,它将源域的目标标签预测作为源知识去正则化目标网络。此处假设的前提是target和source的物体之间有一定的相关性。具体的步骤如下:
- Source-Domain Knowledge:将training图片分别喂到source-domain LSTD 和target-domain LSTD里面,然后将target-domain的proposals应用于source-domain LSTD的ROI池层,最终从源域目标分类器中生成知识向量:
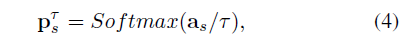
其中a_s是 pre-softmax activation vector for each object proposal,τ是参数,可以产生soften label和richer label-relation information。
Target-Domian Prediction of Source-Domain Categories:将1中的target-domain LSTD微调成多任务学习框架:通过添加a source-object soften classifier at end of target-domain lSTD,然后对于每一个target proposal,该分类器会产生一个 soften prediction of source object categories:
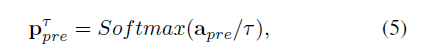
其中a_pre是 pre-softmax activation for each proposal.
TK Regularization:计算knowledge p_ts of source-domain LSTD and the soften prediction p_pre of target-domain LSTD的交叉熵损失:
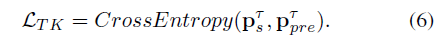
整个模型的训练过程:

参考:
1. http://blog.leanote.com/post/lilac_yue/%5BAAAI2018%5DLSTD
2. https://blog.csdn.net/u011630472/article/details/89216035
论文笔记: LSTD A Low-Shot Transfer Detector for Object Detection的更多相关文章
- 论文笔记《Spatial Memory for Context Reasoning in Object Detection》
好久不写论文笔记了,不是没看,而是很少看到好的或者说值得记的了,今天被xinlei这篇paper炸了出来,这篇被据老大说xinlei自称idea of the year,所以看的时候还是很认真的,然后 ...
- 【论文笔记】YOLOv4: Optimal Speed and Accuracy of Object Detection
论文地址:https://arxiv.org/abs/2004.10934v1 github地址:https://github.com/AlexeyAB/darknet 摘要: 有很多特征可以提高卷积 ...
- 论文阅读笔记五十一:CenterNet: Keypoint Triplets for Object Detection(CVPR2019)
论文链接:https://arxiv.org/abs/1904.08189 github:https://github.com/Duankaiwen/CenterNet 摘要 目标检测中,基于关键点的 ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- 论文阅读 | RefineDet:Single-Shot Refinement Neural Network for Object Detection
论文链接:https://arxiv.org/abs/1711.06897 代码链接:https://github.com/sfzhang15/RefineDet 摘要 RefineDet是CVPR ...
- 三维目标检测论文阅读:Deep Continuous Fusion for Multi-Sensor 3D Object Detection
题目:Deep Continuous Fusion for Multi-Sensor 3D Object Detection 来自:Uber: Ming Liang Note: 没有代码,主要看思想吧 ...
- 【论文笔记】Domain Adaptation via Transfer Component Analysis
论文题目:<Domain Adaptation via Transfer Component Analysis> 论文作者:Sinno Jialin Pan, Ivor W. Tsang, ...
- 论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
论文源址:https://arxiv.org/abs/1506.01497 tensorflow代码:https://github.com/endernewton/tf-faster-rcnn 室友对 ...
- 【计算机视觉】【神经网络与深度学习】论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection
尊重原创,转载请注明:http://blog.csdn.net/tangwei2014 这是继RCNN,fast-RCNN 和 faster-RCNN之后,rbg(Ross Girshick)大神挂名 ...
随机推荐
- 定时器 延时调用setTimeout
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Mybatis延迟加载, 一级缓存、二级缓存
延迟加载 概念:MyBatis中的延迟加载,也称为懒加载,是指在进行关联查询时,按照设置延迟规则推迟对关联对象的select查询.延迟加载可以有效的减少数据库压力. (注意:MyBatis的延迟加载只 ...
- spark读文件写入mysql(scala版本)
package com.zjlantone.hive import java.util.Properties import com.zjlantone.hive.SparkOperaterHive.s ...
- 一些VMware vCenter Appliance的默认用户名和密码
一些VMware vCenter Appliance的默认用户名和密码 2014-03-30 17:30:03 flowershade_21 阅读数 13367更多 分类专栏: vmware VM ...
- MongoDB 建立与删除索引
1.1 在独立服务器上面建立索引 在独立服务器上面创建索引,可以在空闲时间于后台建立索引. 在后台建立索引,可利用background:true参数运行 >db.foo.ensureIndex( ...
- elment-ui的validate
https://blog.csdn.net/qq469234155/article/details/84034816 validate()时elment-ui封装好的用于对整个表单进行验证valida ...
- 模拟I2C协议学习点滴之复习三极管、场效应管
晶体三极管分为NPN和PNP型两种结构形式,除了电源极性的不同工作原理是大致相同的.对于NPN管,它是由2块N型半导体夹着一块P型半导体所组成的,发射区与基区之间形成的PN结称为发射结,而集电区与基区 ...
- qt 读取xml文件中文问题
1.保存文件格式为UTF-8 2.文件流打开时设置 QFile file(fileName); if (!file.open(QIODevice::ReadOnly)) { qDebug() < ...
- (转)Redis Cluster(集群)
一.概述 在前面的文章中介绍过了redis的主从和哨兵两种集群方案,redis从3.0版本开始引入了redis-cluster(集群).从主从-哨兵-集群可以看到redis的不断完善:主从复制是最简单 ...
- js 将网络图片格式转为base64 canvas 跨域
function getBase64Image(img) { var canvas = document.createElement("canvas"); canvas.width ...