使用python批量爬取wallhaven.cc壁纸站壁纸
偶然发现https://wallhaven.cc/这个壁纸站的壁纸还不错,尤其是更新比较频繁,用python写个脚本爬取
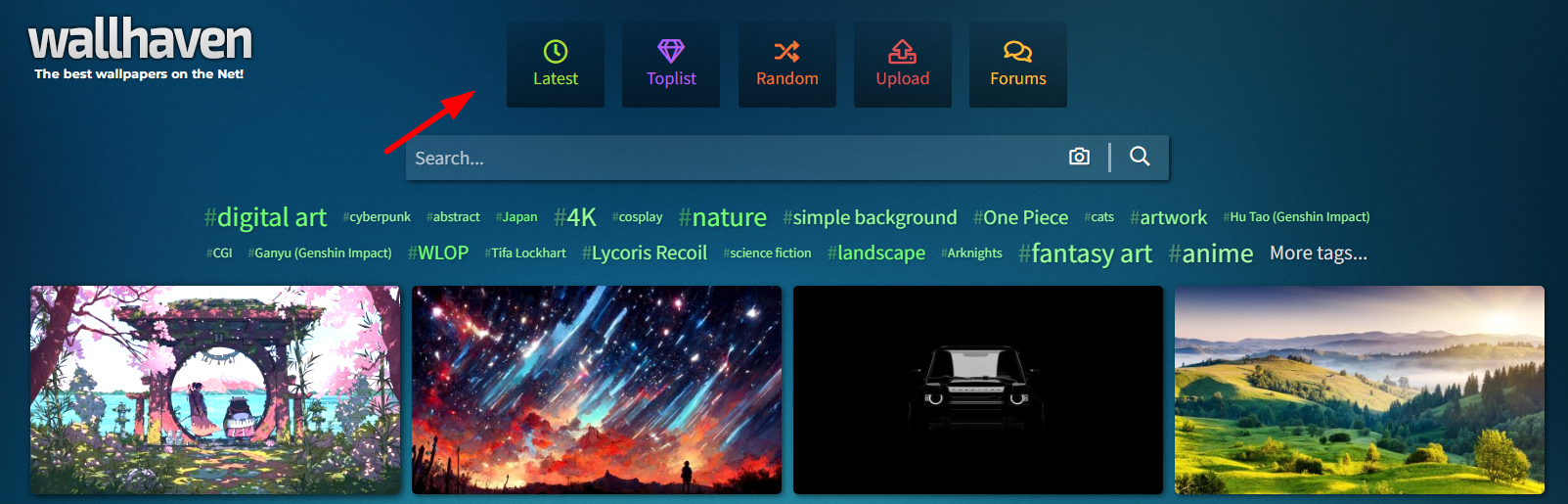
点latest,按照更新先后排序,获得新地址,发现地址是分页展示的,每一页24张
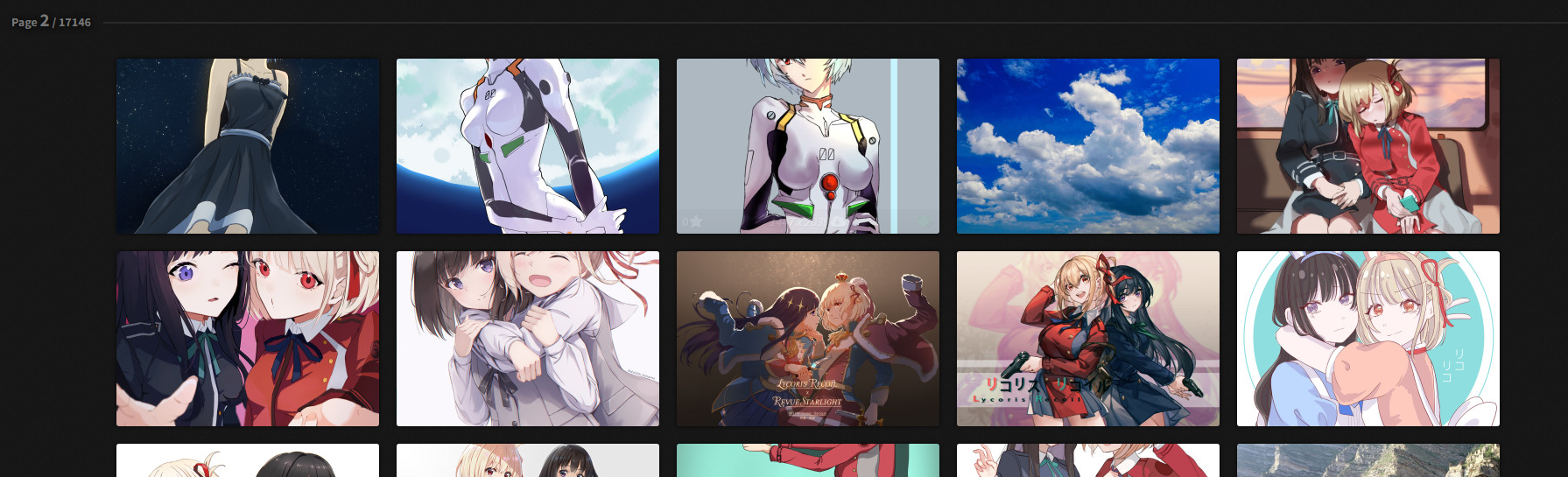
本案例使用xpath爬虫爬取数据,先分析网页,使用浏览器查看元素工具,快速定位到图片元素所在位置,且存在规律性
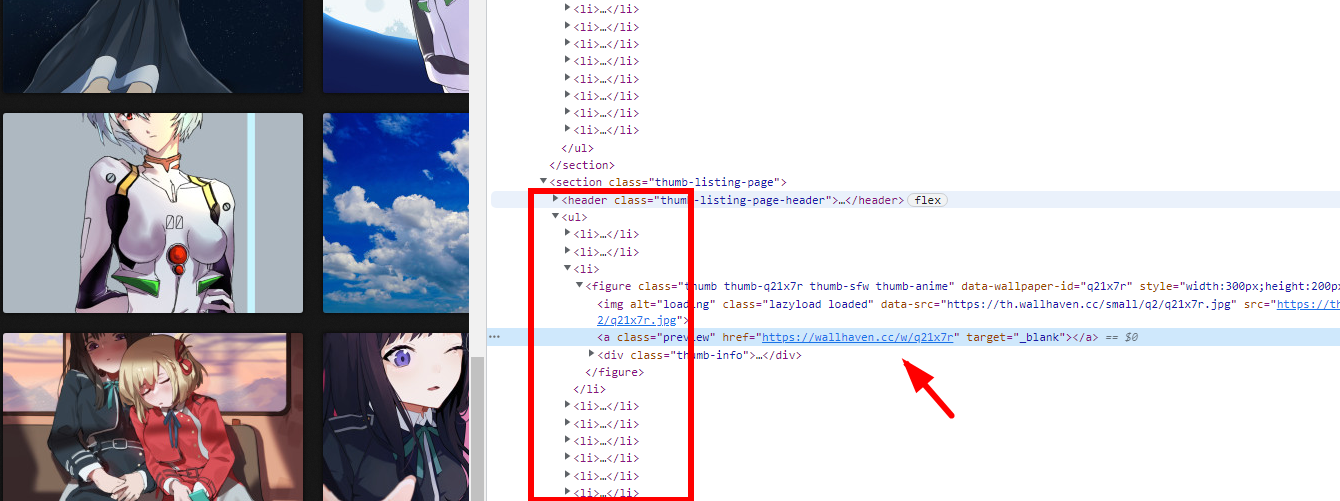
首先爬取一级页面获取图片页面地址(点了上图箭头的地址会打开图片详细页,并非图片真实地址),xpath提取数据的代码如下
html = requests.get(url=url1, headers=headers, timeout=5.0).text
data = etree.HTML(html)
li_list = data.xpath('.//div[@id="thumbs"]//@href')
执行后爬取出一连串的地址信息

对里面包含“latest”的地址进行剔除,这个地址非图片地址,然后再循环请求图片地址,获取真实图片地址
for li in li_list:
if 'latest' in li:
continue
else:
html_li = requests.get(url=li, headers=headers, timeout=5.0).text
data = etree.HTML(html_li)
li_add = data.xpath('//*[@id="wallpaper"]//@src')
li_add = li_add[0]
print(li_add)
执行后输出真实图片地址
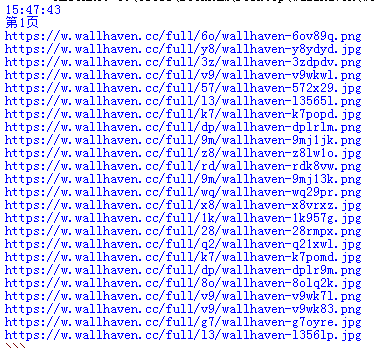
把这些地址写到一个txt文本内,然后通过迅雷去下载,效率会高一些,当然也可以爬取后执行使用python下载,单线程下蛮久的。先上保存到txt内的全部代码
# -*- codeing = utf-8 -*- import requests
from lxml import etree
import time
import random
import time def getBZ(): url='https://wallhaven.cc/latest?page={}' # 翻页10页
for page in range(1, 10): headers = {
# 'referer': 'https://wallhaven.cc/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
print(time.strftime("%H:%M:%S")) print("第{}页".format(page)) url1 = url.format(page)
print(url1)
# 一级页面请求
html = requests.get(url=url1, headers=headers).text
data = etree.HTML(html)
li_list = data.xpath('.//div[@id="thumbs"]//@href')
for li in li_list:
if 'latest' in li or 'top'in li:
continue
else:
print(li)
html_li = requests.get(url=li, headers=headers)
print(html_li.status_code)
if html_li.status_code == 404 or html_li.status_code == 429:#判断,如果响应失败跳过这次数据抓取
continue
else:
data = etree.HTML(html_li.text)
li_add = data.xpath('//*[@id="wallpaper"]//@src')
li_add = li_add[0]
with open('1538.txt', 'a',encoding='utf-8') as w:
w.write(li_add+'\n')
w.close()
b = random.randint(1,2)#随机从1到2内取一个整数值
print("等待"+str(b)+"秒")
time.sleep(b)#把随机取出的整数值传到等待函数中
getBZ()
使用python批量爬取wallhaven.cc壁纸站壁纸的更多相关文章
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
- python 批量爬取四级成绩单
使用本文爬取成绩大致有几个步骤:1.提取表格(或其他格式文件——含有姓名,身份证等信息)中的数据,为进行准考证爬取做准备.2.下载准考证文件并提取出准考证和姓名信息.3.根据得到信息进行数据分析和存储 ...
- python批量爬取动漫免费看!!
实现效果 运行环境 IDE VS2019 Python3.7 Chrome.ChromeDriver Chrome和ChromeDriver的版本需要相互对应 先上代码,代码非常简短,包含空行也才50 ...
- 用Python批量爬取优质ip代理
前言 有时候爬的次数太多时ip容易被禁,所以需要ip代理的帮助.今天爬的思路是:到云代理获取大量ip代理,逐个检测,将超时不可用的代理排除,留下优质的ip代理. 一.爬虫分析 首先看看今天要爬取的网址 ...
- python 批量爬取代理ip
import urllib.request import re import time import random def getResponse(url): req = urllib.request ...
- Python批量爬取谷歌原图,2021年最新可用版
文章目录 前言 一.环境配置 1.安装selenium 2.使用正确的谷歌浏览器驱动 二.使用步骤 1.加载chromedriver.exe 2.设置是否开启可视化界面 3.输入关键词.下载图片数.图 ...
- python批量爬取文档
最近项目需要将批量链接中的pdf文档爬下来处理,根据以下步骤完成了任务: 将批量下载链接copy到text中,每行1个链接: 再读txt文档构造url_list列表,利用readlines返回以行为单 ...
- python批量爬取猫咪图片
不多说直接上代码 首先需要安装需要的库,安装命令如下 pip install BeautifulSoup pip install requests pip install urllib pip ins ...
- 使用Python批量爬取美女图片
运行截图 实列代码: from bs4 import BeautifulSoup import requests,re,os headers = { 'User-Agent': 'Mozilla/5. ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
随机推荐
- 聊一聊 操作系统蓝屏 c0000102 的故障分析
一:背景 1. 讲故事 今年以来不知道为啥总有些朋友加我微信,让我帮忙分析下操作系统蓝屏问题,我也觉得挺好奇的,就问了其中一位朋友,说是B站来的,我就在拼命回忆,为啥会找我分析蓝屏?突然想到了去年好像 ...
- DataV Note:让数据自己讲故事
您是否常常因为面对那些充满各类指标的汇报报告而感到困扰?我们或许能帮到您! 「我们是一家国内的服装公司,财年结束了,公司的销售团队需要对公司的销售数据进行分析,以指导下个财年的作战方向」 「我是浙 ...
- cxGrid列的OnValidate事件处理程序
procedure TForm1.cxGrid1DBTableView1AColumnPropertiesValidate(Sender: TObject; var DisplayValue: Var ...
- Oracle用户的创建和授权
1 --创建用户.密码 2 create user infouser identified by "User@2022!"; 3 --授权连接数据库权限 4 grant conne ...
- Docker部署 .Net程序
项目准备 首先创建一个项目,这里准备的是api项目,当然也可以是其他项目,按照自己需要的项目创建即可: 添加Dockerfile 接下来添加Dockfile文件,Dockerfile文件是Do ...
- [BZOJ4671] 异或图 题解
我能说什么!抽象了这! 看到 \(n\le 10\) 的黑题顿感大事不妙. 我们考虑设 \(f(i)\) 表示将 \(n\) 个点划分为至少 \(i\) 个连通块时的方案数.我们可以暴力枚举每个点在哪 ...
- Deepseek学习随笔(1)--- 初识 DeepSeek
什么是 DeepSeek? DeepSeek 是一款基于人工智能的对话工具,旨在帮助用户高效完成各种任务,包括文本生成.代码编写.数据分析等.通过自然语言处理技术,DeepSeek 能够理解用户的输入 ...
- Docker 容器的数据卷 以及 数据卷容器
Docker 容器删除后,在容器中产生的数据还在吗? 答案是 不在 Docker 容器和外部机器可以直接交换文件吗? 在没有数据卷的情况下,答案是 不可以 如下图:外部机器:Windows系统(自己的 ...
- ubuntu更换国内镜像源备忘
源的路径: /etc/apt/sources.list 更换前备份一下: sudo cp /etc/apt/sources.list /etc/apt/sources_init.list 打开文档,修 ...
- tinyint、int的区别
1.tinyint(1字节--4位[带符号]) 很小的整数.带符号的范围是-128到127.无符号的范围是0到255. 2.smallint(2字节--6位[带符号]) 小的整数.带符号的范围是-32 ...