Scrapy 爬取BOSS直聘关于Python招聘岗位
年前的时候想看下招聘Python的岗位有多少,当时考虑目前比较流行的招聘网站就属于boss直聘,所以使用Scrapy来爬取下boss直聘的Python岗位。 1.首先我们创建一个Scrapy 工程
scrapy startproject boss

2.此时创建项目成功,进入boss目录查看整体的项目目录结构
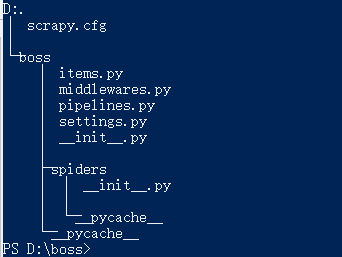
文件说明:
scrapy.cfg 项目配置文件
items.py 数据存储模板,用于结构化数据
pipelines.py 数据处理
settings.py 配置文件
middlewares.py 定义项目中间件
spiders 爬虫目录
3.创建爬虫(spiders)
scrapy genspider boss_zhipin zhipin.com
语法:
scrapy genspider [爬虫名称][爬取范围]
此时我们已经创建完成boss项目的第一个spider任务,其实创建spider不是很难,关键是我们怎么来编写我们的spider,下面我们看下我们要爬去的页面的对象; 4.明确爬虫需求,设计爬虫代码 题目我们已经明确了我们要做什么事情,我们主要来爬取boss直聘上关于python的职位,那么我们先把需求再次缩小一些我们来搜索北京区域关于python的职位,如果我们可以解决了北京区域,那么剩下的其他区域我们完全可以照着北京的来处理。
Ⅰ.定义入口url地址
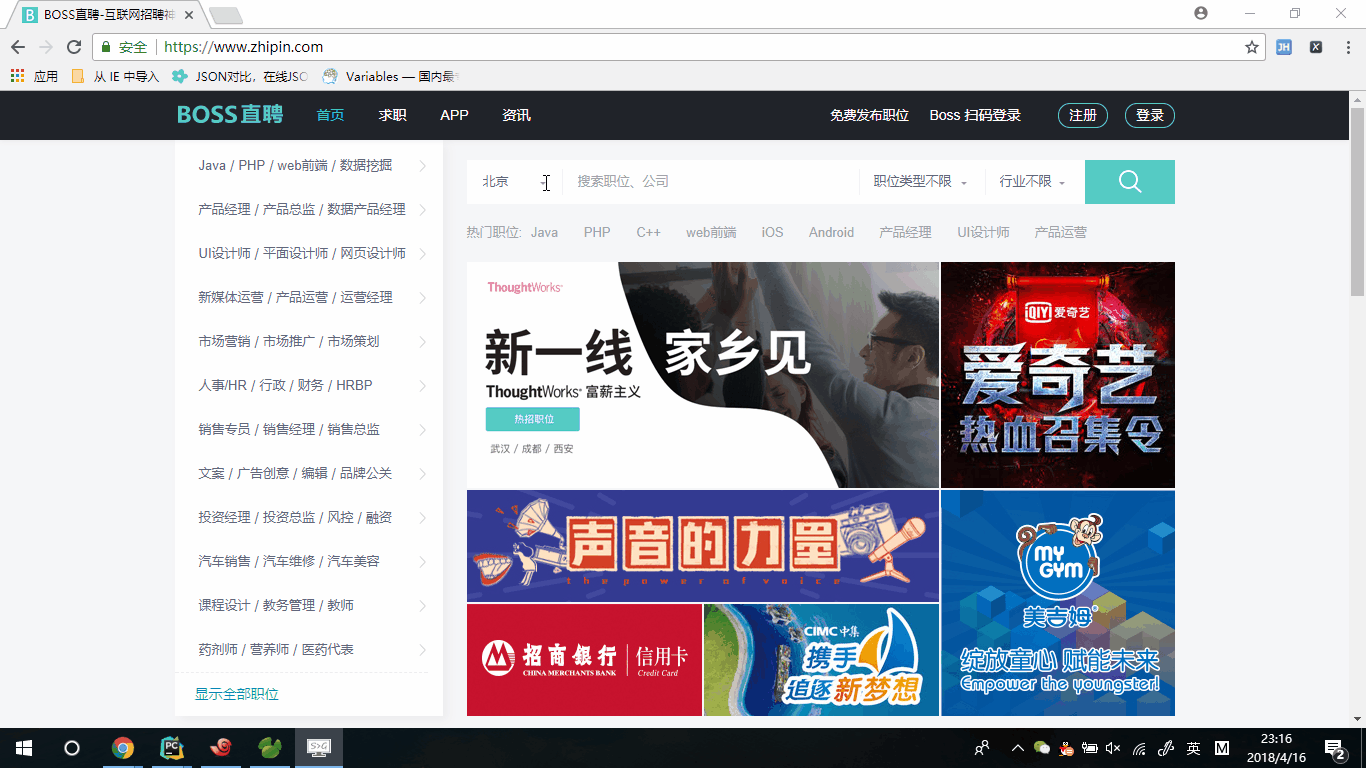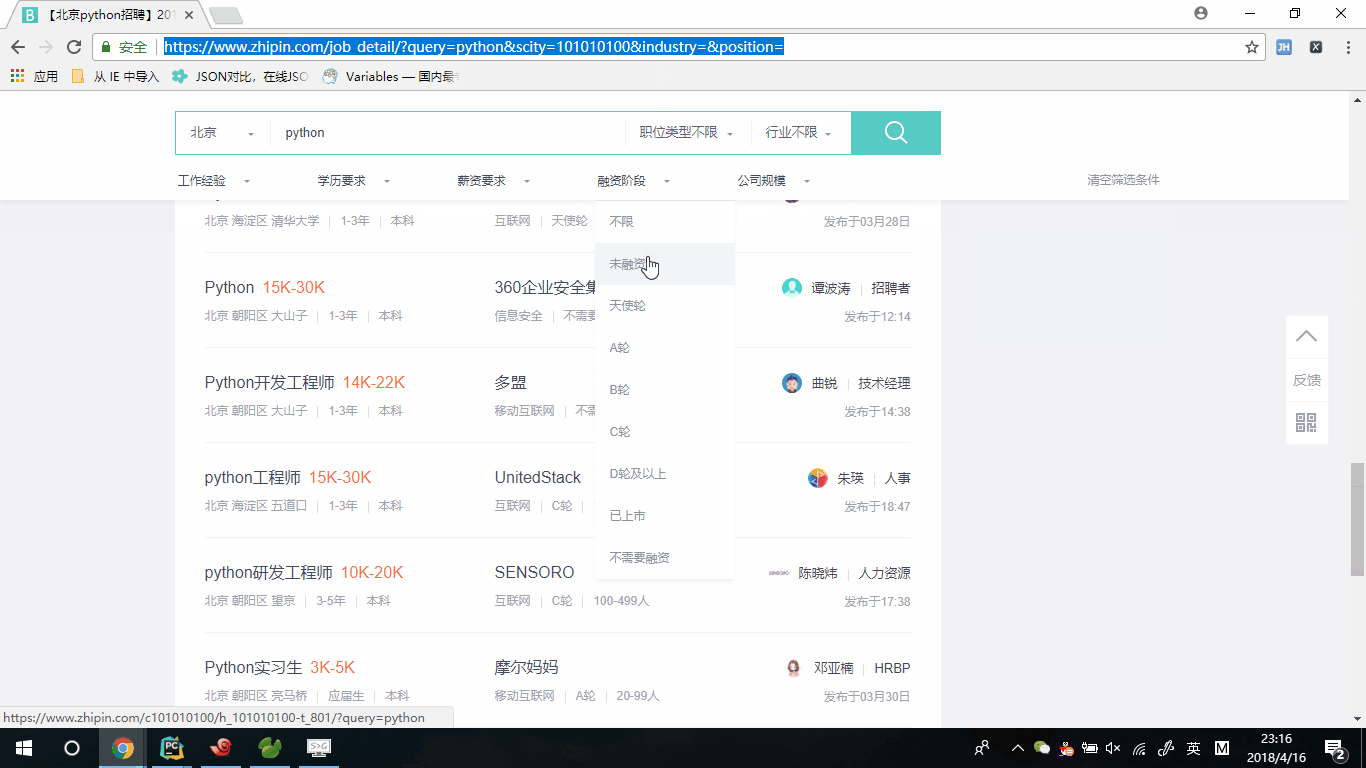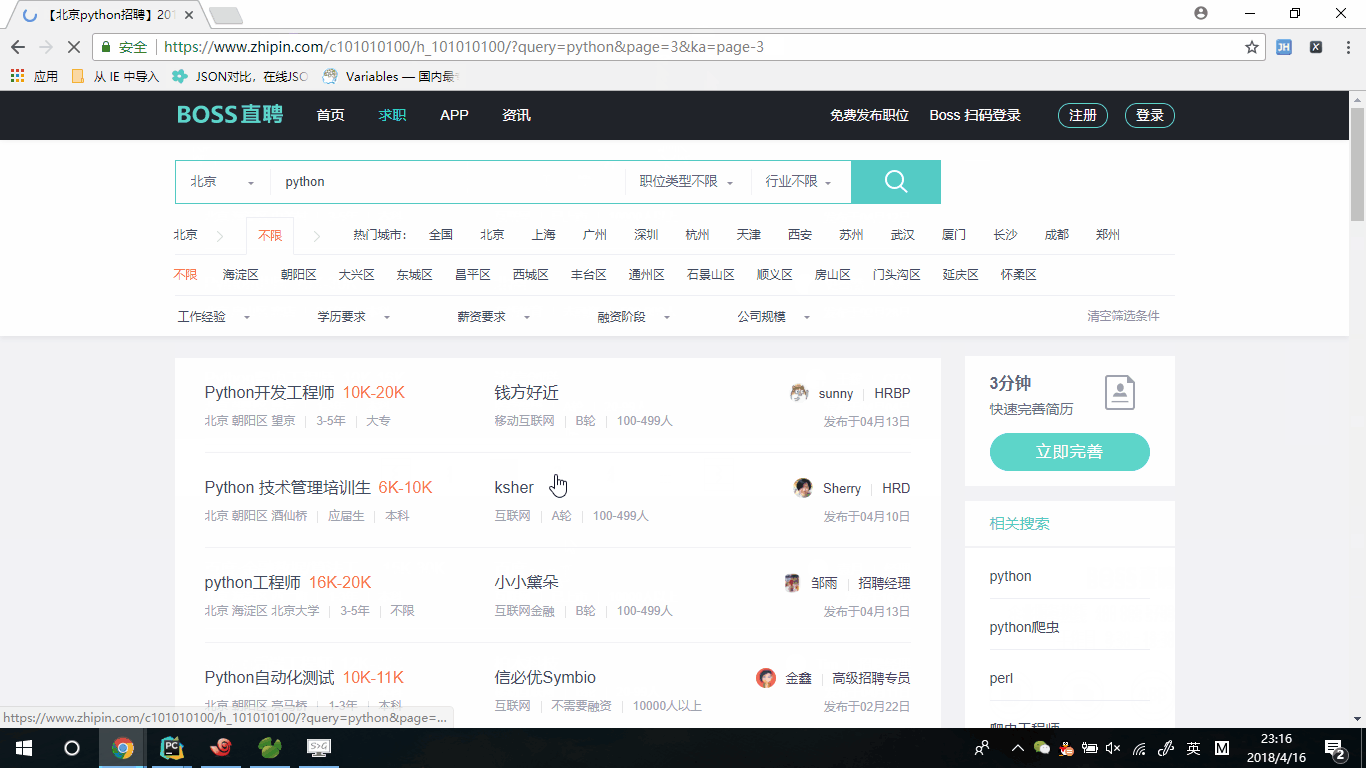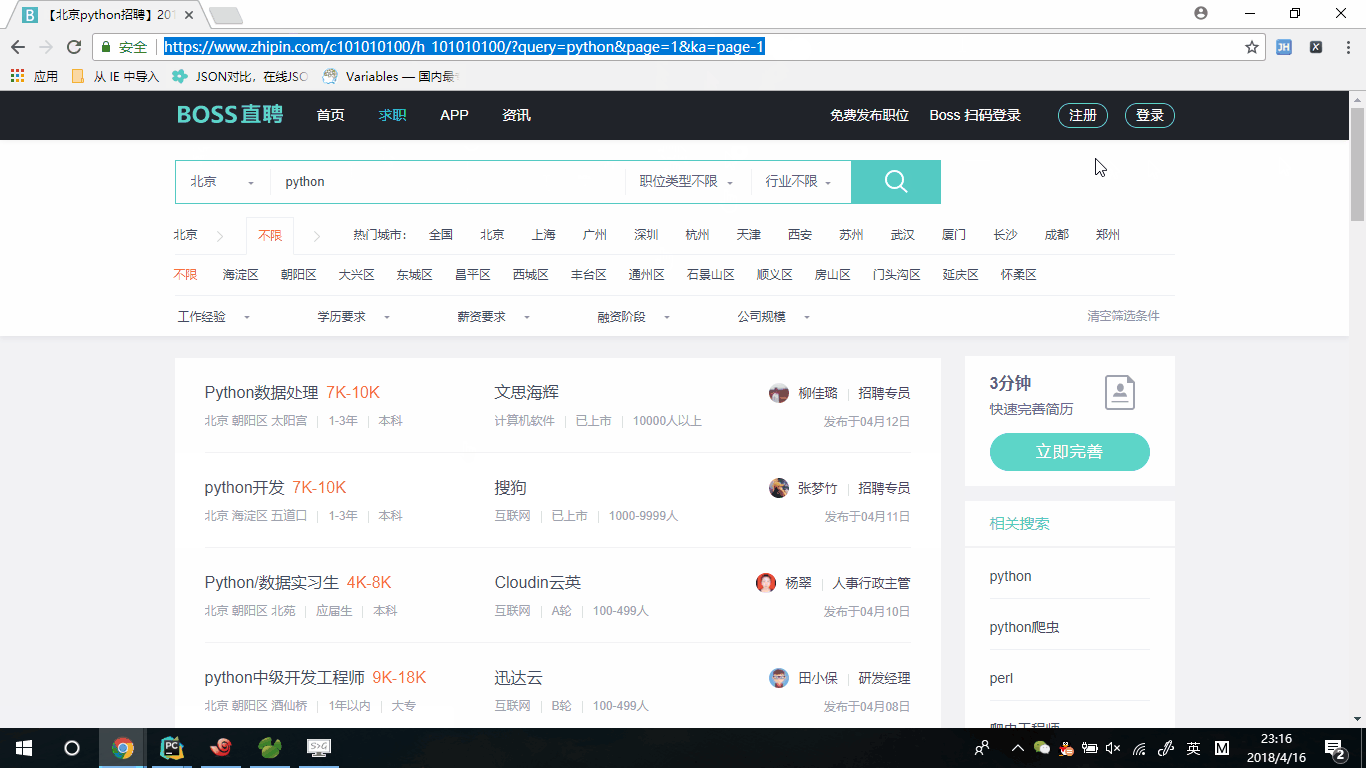
通过上面的演示,我们首先登陆zhipin.com,通过搜索方式找到北京与python相关的职位,此时我们拿到入口url地址"https://www.zhipin.com/job_detail/?query=python&scity=101010100&industry=&position=".因为我们爬去的数据肯定不仅是首页,
所有我们会考虑到翻页的问题,我们进行翻页,看到第二和第二页的地址"https://www.zhipin.com/c101010100/h_101010100/?query=python&page=2&ka=page-2"和"https://www.zhipin.com/c101010100/h_101010100/?query=python&page=3&ka=page-3",
此时我们可以清楚的看到url变化规律,那么我们是否可以入口url定义为"https://www.zhipin.com/c101010100/h_101010100/?query=python&page=1&ka=page-1",我们试着通过返回第一页的方式来验证了下,确实这样的规律可以访问到第一页的数据,那么我们可以把
start_url定义为"https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1"。
start_urls = ['https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1']
Ⅱ.items定义我们要爬取的字段;
class BossItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job_title = scrapy.Field() # 岗位
compensation = scrapy.Field() # 薪资
company = scrapy.Field() # 公司
address = scrapy.Field() # 地址
seniority = scrapy.Field() # 工作年薪
education = scrapy.Field() # 教育程度
company_type = scrapy.Field() # 公司类型
company_finance = scrapy.Field() # 融资
company_quorum = scrapy.Field() # 公司人数
说明:
scrapy.Field()有点类似我们在数据库中定义的数据类型;
Ⅲ.通过定义的字段来定义我们的spider;
class ZhipinSpider(scrapy.Spider):
# 定义spider的名字
name = 'zhipin'
# 定义爬取的域
allowed_domains = ['zhipin.com']
# 定义入口URL
start_urls = ['https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1'] # 定义解析规则,这个方法必须叫做parse
def parse(self, response):
item = BossItem()
# 获取页面数据的条数
node_list = response.xpath("//*[@id=\"main\"]/div/div[2]/ul/li")
# 循环解析页面的数据
for node in node_list:
item["job_title"] = node.xpath(".//div[@class=\"job-title\"]/text()").extract()[0]
item["compensation"] = node.xpath(".//span[@class=\"red\"]/text()").extract()[0]
item["company"] = node.xpath("./div/div[2]/div/h3/a/text()").extract()[0]
company_info = node.xpath("./div/div[2]/div/p/text()").extract()
temp = node.xpath("./div/div[1]/p/text()").extract()
item["address"] = temp[0]
item["seniority"] = temp[1]
item["education"] = temp[2]
if len(company_info) < 3:
item["company_type"] = company_info[0]
item["company_finance"] = ""
item["company_quorum"] = company_info[-1]
else:
item["company_type"] = company_info[0]
item["company_finance"] = company_info[1]
item["company_quorum"] = company_info[2]
yield item
这样我们就可以顺利的解析完成第一页数据,因为我们不仅仅需要第一页数据,我们这里需要的是所有,我们这里还需要添加一个分页;
Ⅳ.获取下一页数据;
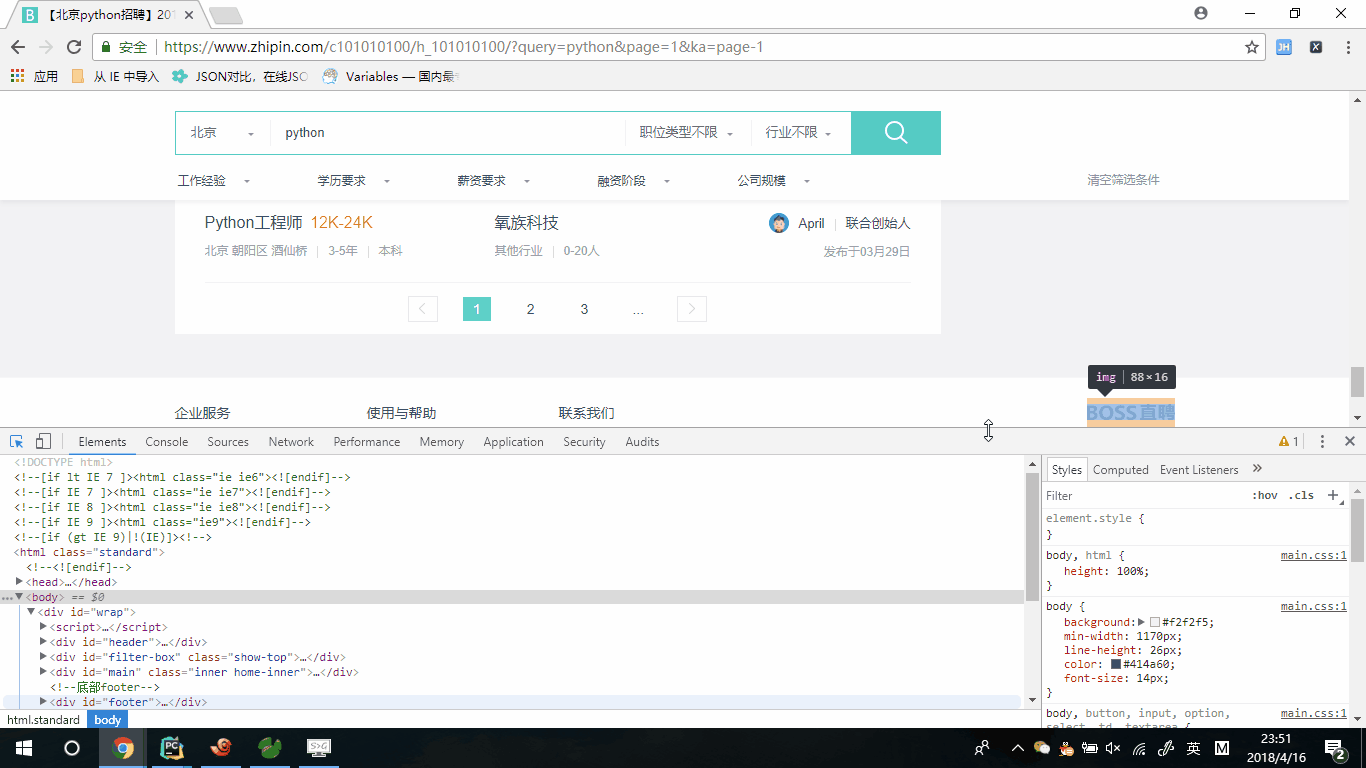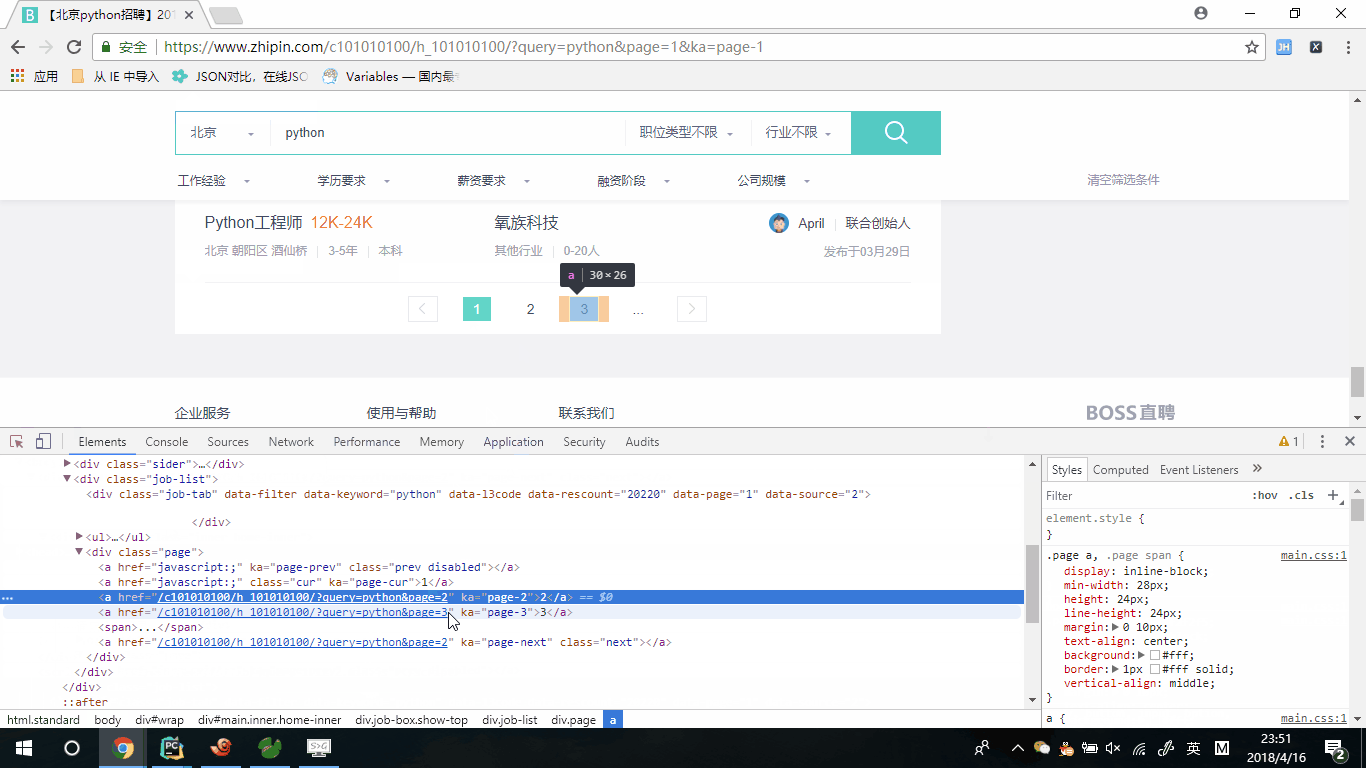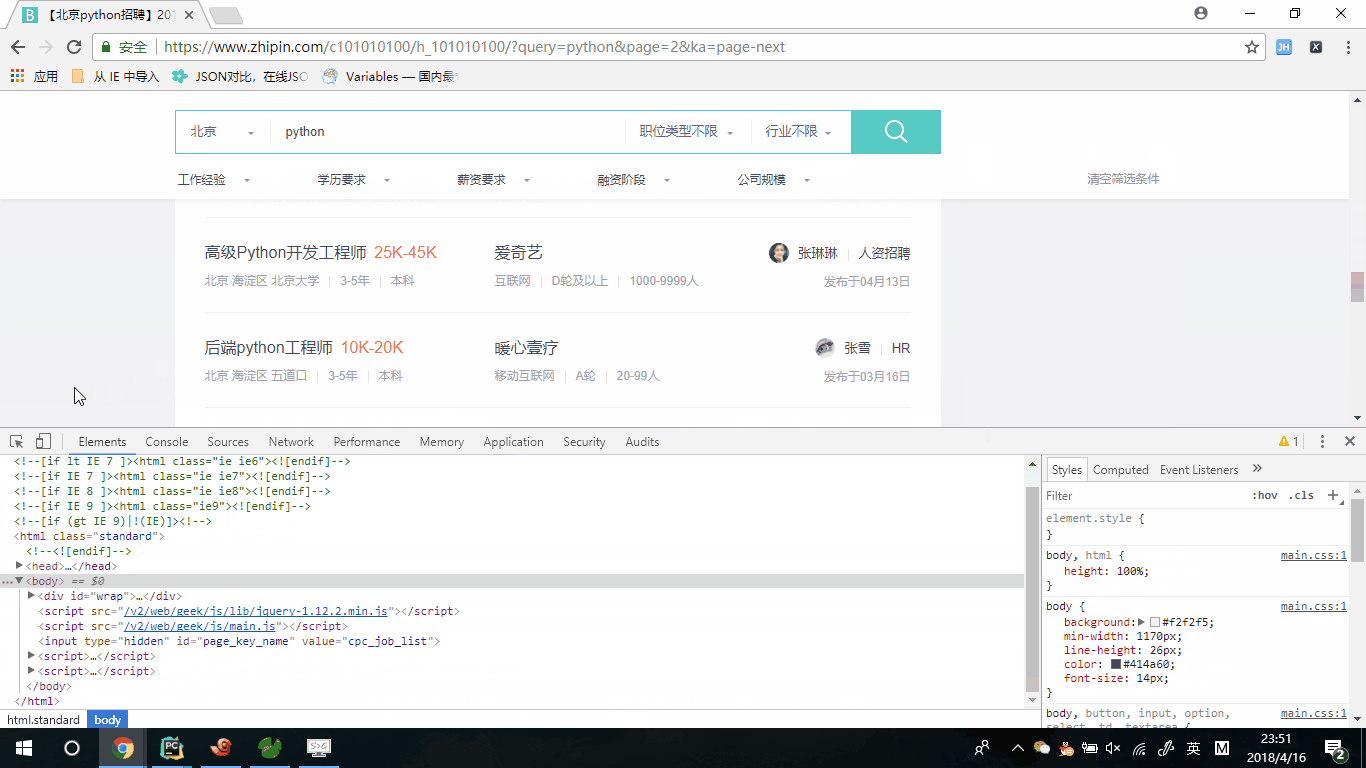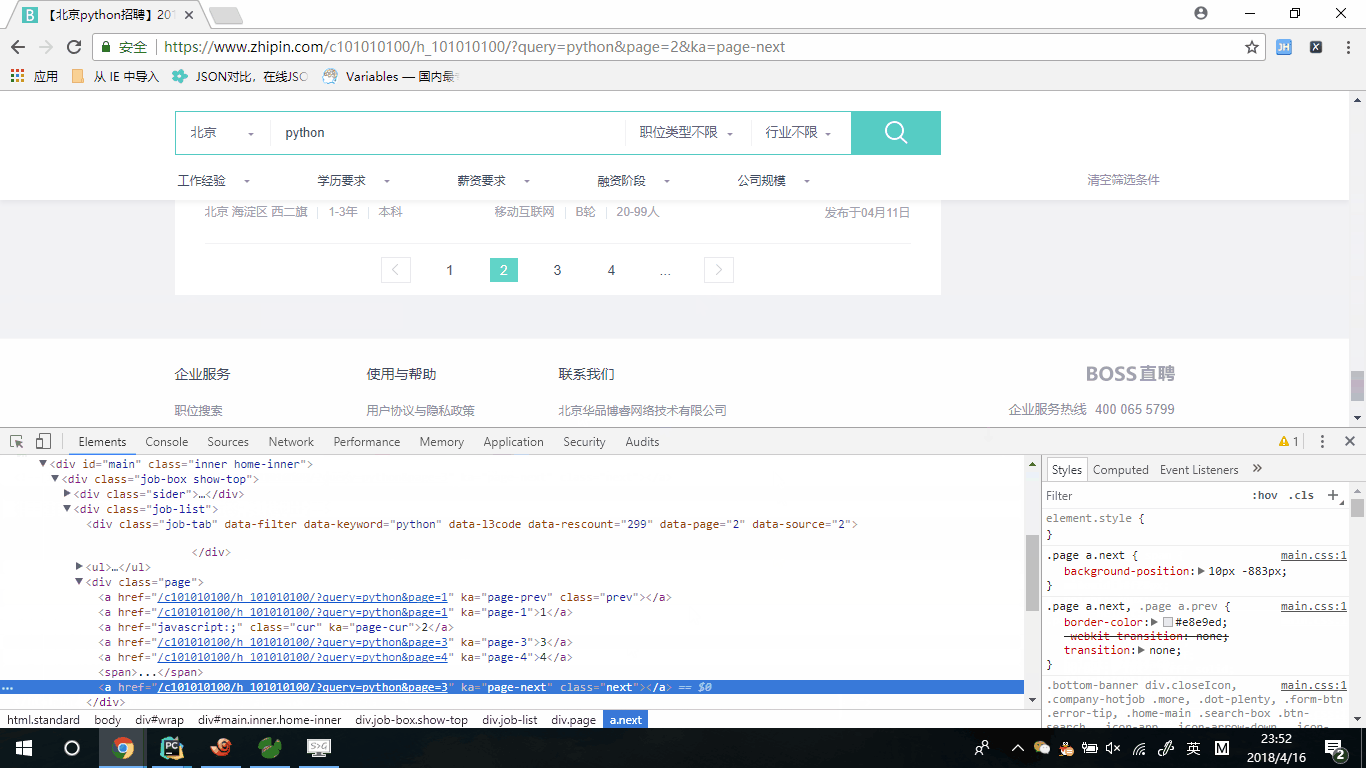
我们分析了下分页标签,发现我们可以一直通过下页标签的方式来获取下页请求的地址,为什么不直接通过分页标签来获取,经过翻页我们没有办法确定元素位置,只有下页元素位置固定且,可以完全的获取下页的请求地址,根据下页的herf地址来拼接请求地址。
# 定义下页标签的元素位置
next_page = response.xpath("//div[@class=\"page\"]/a/@href").extract()[-1]
# 判断什么时候下页没有任何数据
if next_page != 'javascript:;':
base_url = "https://www.zhipin.com"
url = base_url + next_page
yield Request(url=url, callback=self.parse)
这样我们就可以完成的获取所有的岗位数据。
通过boss直聘来爬取python的岗位,我们来介绍了下如何来编写自己的定义爬虫,这里我们是通过页面的方式来爬取了数据,那么我们是否可以通过其他的方式来获取数据,下次介绍通过抓包获取接口地址来爬取数据。
Scrapy 爬取BOSS直聘关于Python招聘岗位的更多相关文章
- scrapy爬取boss直聘实习生数据
这个..是我最近想找实习单位..结果发现boss上很多实习单位名字就叫‘实习生’.......太不讲究了 == 难怪一直搜不到..咳,其实是我自己水平有限,有些简历根本就投不出去 == 所以就想爬下b ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- 用BeautifulSoup简单爬取BOSS直聘网岗位
用BeautifulSoup简单爬取BOSS直聘网岗位 爬取python招聘 import requests from bs4 import BeautifulSoup def fun(path): ...
- python3 爬取boss直聘职业分类数据(未完成)
import reimport urllib.request # 爬取boss直聘职业分类数据def subRule(fileName): result = re.findall(r'<p cl ...
- python分析BOSS直聘的某个招聘岗位数据
前言 毕业找工作,在职人员换工作,离职人员找工作……不管什么人群,应聘求职,都需要先分析对应的招聘岗位,岗位需求是否和自己匹配,常见的招聘平台有:BOSS直聘.拉钩招聘.智联招聘等,我们通常的方法都是 ...
- 打造IP代理池,Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
爬虫面临的问题 不再是单纯的数据一把抓 多数的网站还是请求来了,一把将所有数据塞进去返回,但现在更多的网站使用数据的异步加载,爬虫不再像之前那么方便 很多人说js异步加载与数据解析,爬虫可以做到啊,恩 ...
- Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 王翔 清风Python PS:如有需要Python学习资料的小伙伴 ...
- Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗 零.致谢 感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅. 由于爬虫持续爬取 www.zhipin.com 网 ...
- scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置
scrapy——7 什么是scrapy-redis 怎么安装scrapy-redis scrapy-redis常用配置文件 scrapy-redis键名介绍 实战-利用scrapy-redis分布式爬 ...
随机推荐
- 团队作业8——敏捷冲刺博客合集(Beta阶段)
第一篇(冲刺前安排):https://www.cnblogs.com/Aragaki-Yui/p/9057951.html 第二篇(冲刺第一天):https://www.cnblogs.com/Ara ...
- kbmMW 5.07.00试用笔记
在kbmMW 5.06.20试用笔记中遇到的问题,在这个版本中,基本都解决了.但还是发现修正后存在的小问题及新问题: 1.Resolve返回值错误 当提交的ClientQuery是执行一条sql语句, ...
- Wrapper
开放封闭原则: 开放对扩展 封闭修改源代码 改变了人家调用方式 装饰器结构 """ 默认结构为三层!!!每层返回下一层内存地址就可以进行执行函数, 传参:语法糖中的传参可 ...
- 2.14 加载Firefox配置
2.14 加载Firefox配置(略,已在2.1.8讲过,请查阅2.1.8节课) 回到顶部 2.14-1 加载Chrome配置 一.加载Chrome配置chrome加载配置方法,只需改下面一个地方,u ...
- Wget用法、参数解释的比较好的一个文章
wget是一个从网络上自动下载文件的自由工具.它支持HTTP,HTTPS和FTP协议,可以使用HTTP代理. 所谓的自动下载是指,wget可以在用户退出系统的之后在后台执行.这意味这你可以登录系统,启 ...
- SEGMENTATION FAULT IN LINUX 原因与避免
https://www.cnblogs.com/no7dw/archive/2013/02/20/2918372.html
- 【leetcode】7-ReverseInteger
problem: Reverse Integer 注意考虑是否越界: INT_MAX INT_MIN 32bits or 64bits 调整策略,先从简单的问题开始:
- Redis整理
1. Redis采用的是单进程多线程的模式.当redis.conf中选项daemonize设置成yes时,代表开启守护进程模式.在该模式下,redis会在后台运行,并将进程pid号写入至redis.c ...
- 2017.4.4 TCP/IP三次握手,四次挥手
之前在电话面试的时候,被问到,所以找到一个超级容易理解的图片,自己保存,也算分享.
- 求连续数字的和------------------------------用while的算法思想
前端代码: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.as ...