Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 王翔 清风Python
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
爬虫面临的问题
不再是单纯的数据一把抓
多数的网站还是请求来了,一把将所有数据塞进去返回,但现在更多的网站使用数据的异步加载,爬虫不再像之前那么方便
很多人说js异步加载与数据解析,爬虫可以做到啊,恩是的,无非增加些工作量,那是你没遇到牛逼的前端,多数的解决办法只能靠渲染浏览器抓取,效率低下,接着往下走
千姿百态的登陆验证
从12306的说说下面哪个糖是奶糖,到现在各大网站的滑动拼图、汉子点击解锁,这些操作都是在为了阻止爬虫的自动化运行。
你说可以先登录了复制cookie,但cookie也有失效期吧?
反爬虫机制
何为反爬虫?犀利的解释网上到处搜,简单的逻辑我讲给你听。你几秒钟访问了我的网站一千次,不好意思,我把你的ip禁掉,一段时间你别来了。
很多人又说了,你也太菜了吧,不知道有爬虫ip代理池的开源项目IPProxys吗?那我就呵呵了,几个人真的现在用过免费的ip代理池,你去看看现在的免费代理池,有几个是可用的!
再说了,你通过IPProxys代理池,获取到可用的代理访问人家网站,人家网站不会用同样的办法查到可用的代理先一步封掉吗?然后你只能花钱去买付费的代理
数据源头封锁
平时大家看的什么爬爬豆瓣电影网站啊,收集下某宝评论啊....这些都是公开数据。但现在更多的数据逐步走向闭源化。数据的价值越来越大,没有数据获取的源头,爬虫面临什么问题?
上面说了一堆的爬虫这不好那不好,结果我今天发的文章确是爬虫的,自己打自己的脸? 其实我只是想说说网站数据展示与分析的技巧...恰巧Boss直聘就做的很不错。怎么不错?一点点分析...
数据共享
先来看一张图
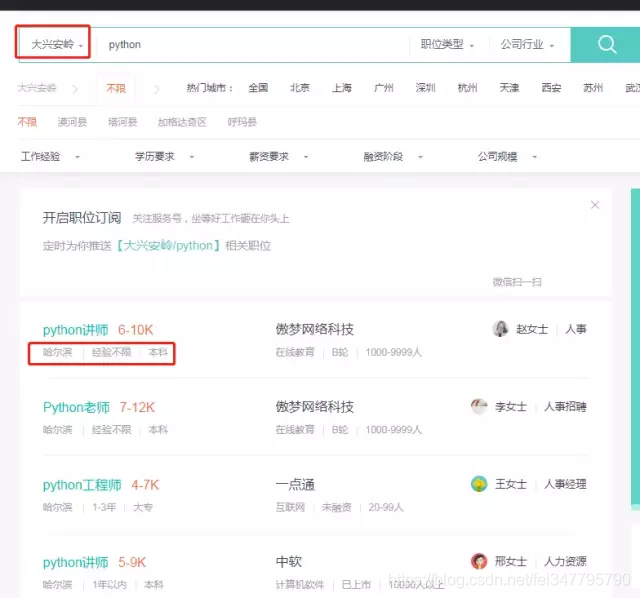
我选择黑龙江省的大兴安岭,去看看那里有招聘python的没,多数系统查询不到数据就会给你提示未获取到相关数据,但Boss直聘会悄悄地吧黑龙江省的python招聘信息给你显示处理,够鸡~贼。
数据限制
大兴安岭没有搞python的,那我们去全国看看吧:
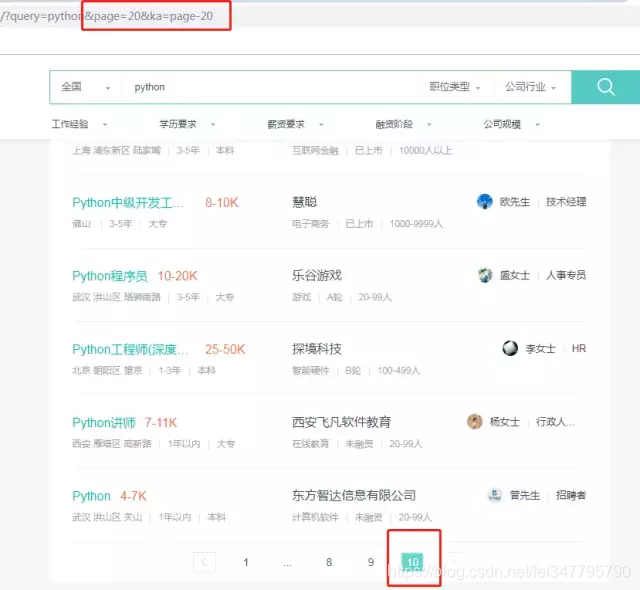
这里差一点就把我坑了,我开始天真的以为,全国只有300条(一页30条,共10也)python招聘信息。 然后我回过头去看西安的,也只有10页,然后想着修改下他的get请求parameters,没卵用。
这有啥用?仔细想...一方面可以做到放置咱们爬虫一下获取所有的数据,但这只是你自作多情,这东西是商机!
每天那么多的商家发布招聘信息,进入不了top100,别人想看都看不到你的消息,除非搜索名字。那么如何排名靠前?答案就是最后俩字,靠钱。你是Boss直聘的会员,你发布的就会靠前....
偷换概念
依旧先看图:
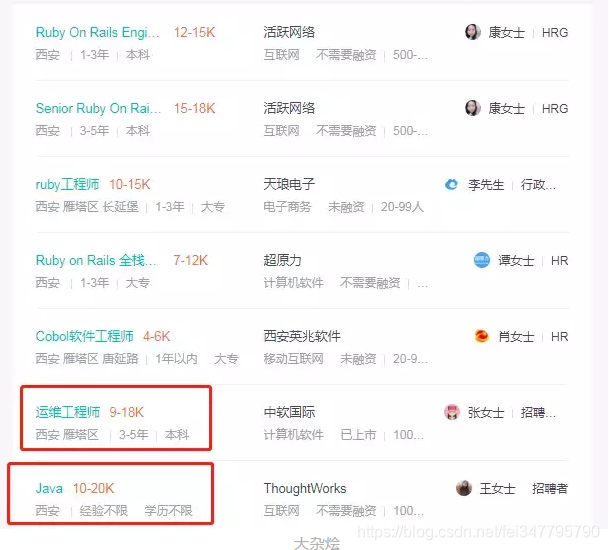
我搜索的是ruby,你资料不够,其他来凑....
ip解析
老套路,再来看一张图:
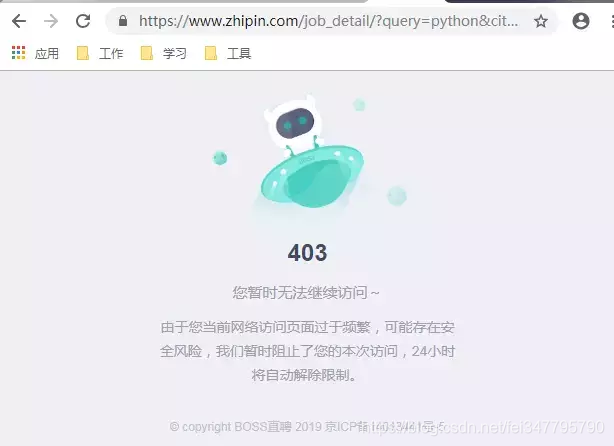
Boss直聘的服务器里,留着我的痕迹,多么骄傲的事情啊。你们想不想和我一样?只需要3秒钟.... 三秒钟内你的访问量能超过1000,妥妥被封!
那么我们该怎么办
设置不同的User-Agent
使用pip install fake-useragent安装后获取多种User-Agent,但其实本地保存上几十个,完全够了....
不要太夯(大力)
适当的减慢你的速度,别人不会觉得是你菜....别觉得一秒爬几千比一秒爬几百的人牛逼(快枪手子弹打完的早....不算开车吧?)。
购买付费的代理
为什么我跳过了说免费的代理?因为现在搞爬虫的人太多了,免费的基本早就列入各大网站的黑名单了。
所以解析到的原始数据如下:
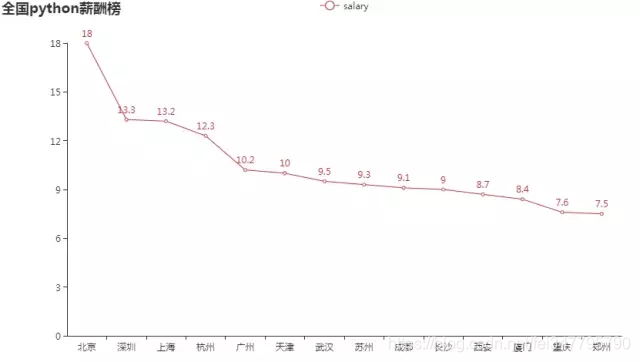
先来看看python的薪酬榜:
看一下西安的排位,薪资平均真的好低.....
代码
import requests
from bs4 import BeautifulSoup
import csv
import random
import time
import argparse
from pyecharts.charts import Line
import pandas as pd
class BossCrawler:
def __init__(self, query):
self.query = query
self.filename = 'boss_info_%s.csv' % self.query
self.city_code_list = self.get_city()
self.boss_info_list = []
self.csv_header = ["city", "profession", "salary", "company"]
@staticmethod
def getheaders():
user_list = [
"Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
"Opera/12.0(Windows NT 5.2;U;en)Presto/22.9.168 Version/12.00",
"Opera/12.0(Windows NT 5.1;U;en)Presto/22.9.168 Version/12.00",
"Mozilla/5.0 (Windows NT 5.1) Gecko/20100101 Firefox/14.0 Opera/12.0",
"Opera/9.80 (Windows NT 6.1; WOW64; U; pt) Presto/2.10.229 Version/11.62",
"Opera/9.80 (Windows NT 6.0; U; pl) Presto/2.10.229 Version/11.62",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; de) Presto/2.9.168 Version/11.52",
"Opera/9.80 (Windows NT 5.1; U; en) Presto/2.9.168 Version/11.51",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; de) Opera 11.51",
"Opera/9.80 (X11; Linux x86_64; U; fr) Presto/2.9.168 Version/11.50",
"Opera/9.80 (X11; Linux i686; U; hu) Presto/2.9.168 Version/11.50",
"Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11",
"Opera/9.80 (X11; Linux i686; U; es-ES) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/5.0 Opera 11.11",
"Opera/9.80 (X11; Linux x86_64; U; bg) Presto/2.8.131 Version/11.10",
"Opera/9.80 (Windows NT 6.0; U; en) Presto/2.8.99 Version/11.10",
"Opera/9.80 (Windows NT 5.1; U; zh-tw) Presto/2.8.131 Version/11.10",
"Opera/9.80 (Windows NT 6.1; Opera Tablet/15165; U; en) Presto/2.8.149 Version/11.1",
"Opera/9.80 (X11; Linux x86_64; U; Ubuntu/10.10 (maverick); pl) Presto/2.7.62 Version/11.01",
"Opera/9.80 (X11; Linux i686; U; ja) Presto/2.7.62 Version/11.01",
"Opera/9.80 (X11; Linux i686; U; fr) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; zh-tw) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; sv) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; en-US) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; cs) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.0; U; pl) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 5.2; U; ru) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 5.1; U;) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 5.1; U; cs) Presto/2.7.62 Version/11.01",
"Mozilla/5.0 (Windows NT 6.1; U; nl; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 Opera 11.01",
"Mozilla/5.0 (Windows NT 6.1; U; de; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 Opera 11.01",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; de) Opera 11.01",
"Opera/9.80 (X11; Linux x86_64; U; pl) Presto/2.7.62 Version/11.00",
"Opera/9.80 (X11; Linux i686; U; it) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.6.37 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; pl) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; ko) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; fi) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; en-GB) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1 x64; U; en) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.0; U; en) Presto/2.7.39 Version/11.00"
]
user_agent = random.choice(user_list)
headers = {'User-Agent': user_agent}
return headers
def get_city(self):
headers = self.getheaders()
r = requests.get("http://www.zhipin.com/wapi/zpCommon/data/city.json", headers=headers)
data = r.json()
return [city['code'] for city in data['zpData']['hotCityList'][1:]]
def get_response(self, url, params=None):
headers = self.getheaders()
r = requests.get(url, headers=headers, params=params)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, "lxml")
return soup
def get_url(self):
for city_code in self.city_code_list:
url = "https://www.zhipin.com/c%s/" % city_code
self.per_page_info(url)
time.sleep(10)
def per_page_info(self, url):
for page_num in range(1, 11):
params = {"query": self.query, "page": page_num}
soup = self.get_response(url, params)
lines = soup.find('div', class_='job-list').select('ul > li')
if not lines:
# 代表没有数据了,换下一个城市
return
for line in lines:
info_primary = line.find('div', class_="info-primary")
city = info_primary.find('p').text.split(' ')[0]
job = info_primary.find('div', class_="job-title").text
# 过滤答非所谓的招聘信息
if self.query.lower() not in job.lower():
continue
salary = info_primary.find('span', class_="red").text.split('-')[0].replace('K', '')
company = line.find('div', class_="info-company").find('a').text.lower()
result = dict(zip(self.csv_header, [city, job, salary, company]))
print(result)
self.boss_info_list.append(result)
def write_result(self):
with open(self.filename, "w+", encoding='utf-8', newline='') as f:
f_csv = csv.DictWriter(f, self.csv_header)
f_csv.writeheader()
f_csv.writerows(self.boss_info_list)
def read_csv(self):
data = pd.read_csv(self.filename, sep=",", header=0)
data.groupby('city').mean()['salary'].to_frame('salary').reset_index().sort_values('salary', ascending=False)
result = data.groupby('city').apply(lambda x: x.mean()).round(1)['salary'].to_frame(
'salary').reset_index().sort_values('salary', ascending=False)
print(result)
charts_bar = (
Line()
.set_global_opts(
title_opts={"text": "全国%s薪酬榜" % self.query})
.add_xaxis(result.city.values.tolist())
.add_yaxis("salary", result.salary.values.tolist())
)
charts_bar.render('%s.html' % self.query)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("-k", "--keyword", help="请填写所需查询的关键字")
args = parser.parse_args()
if not args.keyword:
print(parser.print_help())
else:
main = BossCrawler(args.keyword)
main.get_url()
main.write_result()
main.read_csv()
Python爬取Boss直聘,帮你获取全国各类职业薪酬榜的更多相关文章
- 打造IP代理池,Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
爬虫面临的问题 不再是单纯的数据一把抓 多数的网站还是请求来了,一把将所有数据塞进去返回,但现在更多的网站使用数据的异步加载,爬虫不再像之前那么方便 很多人说js异步加载与数据解析,爬虫可以做到啊,恩 ...
- Scrapy 爬取BOSS直聘关于Python招聘岗位
年前的时候想看下招聘Python的岗位有多少,当时考虑目前比较流行的招聘网站就属于boss直聘,所以使用Scrapy来爬取下boss直聘的Python岗位. 1.首先我们创建一个Scrapy 工程 s ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- 用BeautifulSoup简单爬取BOSS直聘网岗位
用BeautifulSoup简单爬取BOSS直聘网岗位 爬取python招聘 import requests from bs4 import BeautifulSoup def fun(path): ...
- python3 爬取boss直聘职业分类数据(未完成)
import reimport urllib.request # 爬取boss直聘职业分类数据def subRule(fileName): result = re.findall(r'<p cl ...
- scrapy爬取boss直聘实习生数据
这个..是我最近想找实习单位..结果发现boss上很多实习单位名字就叫‘实习生’.......太不讲究了 == 难怪一直搜不到..咳,其实是我自己水平有限,有些简历根本就投不出去 == 所以就想爬下b ...
- Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗
Pyhton爬虫实战 - 抓取BOSS直聘职位描述 和 数据清洗 零.致谢 感谢BOSS直聘相对权威的招聘信息,使本人有了这次比较有意思的研究之旅. 由于爬虫持续爬取 www.zhipin.com 网 ...
- python分析BOSS直聘的某个招聘岗位数据
前言 毕业找工作,在职人员换工作,离职人员找工作……不管什么人群,应聘求职,都需要先分析对应的招聘岗位,岗位需求是否和自己匹配,常见的招聘平台有:BOSS直聘.拉钩招聘.智联招聘等,我们通常的方法都是 ...
- scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置
scrapy——7 什么是scrapy-redis 怎么安装scrapy-redis scrapy-redis常用配置文件 scrapy-redis键名介绍 实战-利用scrapy-redis分布式爬 ...
随机推荐
- leetcode-二叉树
树以及常用的算法 树的概念 树(Tree)的基本概念树是由结点或顶点和边组成的(可能是非线性的)且不存在着任何环的一种数据结构.没有结点的树称为空(null或empty)树.一棵非空的树包括一个根结点 ...
- 一文了解 Consistent Hash
本文首发于 vivo互联网技术 微信公众号 链接:https://mp.weixin.qq.com/s/LGLqEOlGExKob8xEXXWckQ作者:钱幸川 在分布式环境下面,我们经常会通过一定的 ...
- java高并发系列 - 第26篇:学会使用JUC中常见的集合,常看看!
这是java高并发系列第26篇文章. 环境:jdk1.8. 本文内容 了解JUC常见集合,学会使用 ConcurrentHashMap ConcurrentSkipListMap Concurrent ...
- (五十七)c#Winform自定义控件-传送带(工业)-HZHControls
官网 http://www.hzhcontrols.com 前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kww ...
- Selenium(十四):自动化测试模型介绍、模块化驱动测试案例、数据驱动测试案例
1. 自动化测试模型介绍 随着自动化测试技术的发展,演化为了集中模型:线性测试.模块化驱动测试.数据驱动测试和关键字驱动测试. 下面分别介绍这几种自动化测试模型的特点. 1.1 线性测试 通过录制或编 ...
- VMware+node+nginx+vue
1.安装CentOS 这里不再复述,不会的请移步VMware虚拟机安装centos7 2.部署 1.安装 node.js cd /usr/local/ wget https://nodejs.or ...
- dedecmsV5.7 arclist标签同时取出主表和附表里的数据
{dede:arclist}{/dede:arclist}标签默认取出来的是主表x_archives中的数据,如果要取出附表中的数据,需要满足两个条件: 指定channelid属性(注意:channe ...
- 高通lk屏幕向kernel传参
LK把相关参数报存到cmdline上: 在Bootable\bootloader\lk\dev\gcdb\display\gcdb_display_param.c上gcdb_display_cmdli ...
- eNSP仿真模拟软件之理解Hybrid接口的应用
1. 实验原理 Hybrid接口既可以连接普通终端的接入链路又可以连接交换机间的干道链路,它允许多个VLAN的帧通过,并可以在出接口方向将某些VLAN帧的标签剥掉. Hybrid接口处理VLAN帧的过 ...
- echarts自定义颜色主题
1. 进入地址: https://echarts.baidu.com/theme-builder/ 2. 配置主题 2.1. 可以选择挑选默认方案 2.2 可以进行一些样式配置 2.3 配置背景颜色 ...