EM算法索引
把这n个{试验结果来自B的概率}求和得到期望,平均后,得到B出正面的似然估计,同理有p和q。
重复迭代,直到收敛为止
http://blog.csdn.net/junnan321/article/details/8483343/
http://blog.csdn.net/zouxy09/article/details/8537620
http://www.hankcs.com/ml/em-algorithm-and-its-generalization.html
http://www.cnblogs.com/mindpuzzle/archive/2013/04/05/2998746.html
CNN
http://lib.csdn.net/article/deeplearning/50827
http://www.jianshu.com/p/606a33ba04ff
http://blog.csdn.net/abcjennifer/article/details/25912675
GMM:
http://www.cnblogs.com/CBDoctor/archive/2011/11/06/2236286.html(GMM聚类)
https://www.52ml.net/7890.html(Gmm01)
http://blog.csdn.net/sinat_22594309/article/details/65629407(gmm02)
EM算法二次整理:
1、对于含有隐变量的概率问题,不能直接使用最大似然函数解决的原因:运算上面最大似然函数中过多的加号,不能求解!
在推导EM算法之前,先引用《统计学习方法》中EM算法的例子:
例1. (三硬币模型) 假设有3枚硬币,分别记作A,B,C。这些硬币正面出现的概率分别为π,p和q。投币实验如下,先投A,如果A是正面,即A=1,那么选择投B;A=0,投C。最后,如果B或者C是正面,那么y=1;是反面,那么y=0;独立重复n次试验(n=10),观测结果如下: 1,1,0,1,0,0,1,0,1,1假设只能观测到投掷硬币的结果,不能观测投掷硬币的过程。问如何估计三硬币正面出现的概率,即π,p和q的值。
解:设随机变量y是观测变量,则投掷一次的概率模型为

有n次观测数据Y,那么观测数据Y的似然函数为

那么利用最大似然估计求解模型解,即
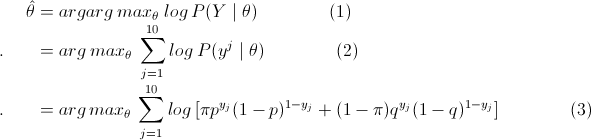
这里将概率模型公式和似然函数代入(1)式中,可以很轻松地推出 (1)=> (2) => (3),然后选取θ(π,p,q),使得(3)式值最大,即最大似然。然后,我们会发现因为(3)中右边多项式+符号的存在,使得(3)直接求偏导等于0或者用梯度下降法都很难求得θ值。
这部分的难点是因为(3)多项式中+符号的存在,而这是因为这个三硬币模型中,我们无法得知最后得结果是硬币B还是硬币C抛出的这个隐藏参数。
那么我们把这个latent 随机变量加入到 log-likelihood 函数中,得
( 对于每一个样例i,让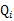 表示该样例隐含变量z的某种分布,
表示该样例隐含变量z的某种分布,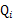 满足的条件是
满足的条件是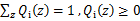 。)
。)

略看一下,好像很复杂,其实很简单,请容我慢慢道来。首先是公式(1),这里将zi做为隐藏变量,当z1为结果由硬币B抛出,z2为结果由硬币C抛出,不难发现
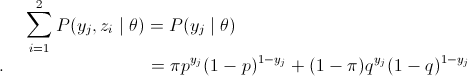
(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式
这个过程可以看作是对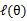 求了下界。对于
求了下界。对于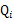 的选择,有多种可能,那种更好的?
的选择,有多种可能,那种更好的?
假设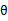 已经给定,那么
已经给定,那么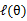 的值就决定于
的值就决定于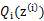 和
和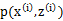 了。我们可以通过调整这两个概率使下界不断上升,以逼近
了。我们可以通过调整这两个概率使下界不断上升,以逼近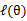 的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于
的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于 了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需jensen不等式,需要让:
了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需jensen不等式,需要让: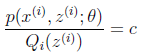 (那么对于每个样例的两个概率比值都是c)
(那么对于每个样例的两个概率比值都是c)
c为常数,不依赖于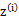 。
。
对此式子做进一步推导,
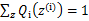 ,
,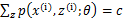
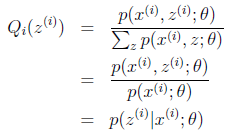
至此,我们推出了在固定其他参数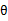 后,
后,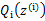 的计算公式就是后验概率,解决了
的计算公式就是后验概率,解决了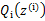 如何选择的问题。
如何选择的问题。

已经不含有“+”符号了,并且本文认为:后, 建立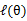 的下界时可以认为 log(),这样就不存“+”问题了。接下来的M步,就是在给定
的下界时可以认为 log(),这样就不存“+”问题了。接下来的M步,就是在给定 后,调整
后,调整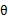 ,去极大化
,去极大化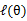 的下界(在固定
的下界(在固定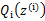 后,下界还可以调整的更大)。
后,下界还可以调整的更大)。
EM算法索引的更多相关文章
- opencv3中的机器学习算法之:EM算法
不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmea ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- K-Means聚类和EM算法复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合 内容: 1.算法概述 k-means算法是一种得到最广泛使用的聚类算法. 它是将各个聚类子集内 ...
- EM算法总结
EM算法总结 - The EM Algorithm EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法.在之后的MT中的词对齐中也用 ...
- GMM的EM算法实现
转自:http://blog.csdn.net/abcjennifer/article/details/8198352 在聚类算法K-Means, K-Medoids, GMM, Spectral c ...
- EM算法(4):EM算法证明
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(4):EM算法证明 1. 概述 上一篇博客我们已经讲过 ...
- EM算法(3):EM算法运用
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(3):EM算法运用 1. 内容 EM算法全称为 Exp ...
- EM算法(2):GMM训练算法
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(2):GMM训练算法 1. 简介 GMM模型全称为Ga ...
随机推荐
- AC日记——爱改名的小融3 codevs 3156
3156 爱改名的小融 3 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 题目描述 Description Wikioi上有个人叫小融,他喜 ...
- js-classList修改class属性
classList定义与用法 1)classList属性返回元素的类名,作为DOMTokenList对象 2)该属性用于在元素中添加,移除及切换css类 3)classList属性是只读的,但可以用a ...
- TensorFlow——tensorflow指定CPU与GPU运算
1.指定GPU运算 如果安装的是GPU版本,在运行的过程中TensorFlow能够自动检测.如果检测到GPU,TensorFlow会尽可能的利用找到的第一个GPU来执行操作. 如果机器上有超过一个可用 ...
- 洛谷——P3252 [JLOI2012]树
P3252 [JLOI2012]树 题目描述 在这个问题中,给定一个值S和一棵树.在树的每个节点有一个正整数,问有多少条路径的节点总和达到S.路径中节点的深度必须是升序的.假设节点1是根节点,根的深度 ...
- ELK之收集Java日志、通过TCP收集日志
1.Java日志收集 使用codec的multiline插件实现多行匹配,这是一个可以将多行进行合并的插件,而且可以使用what指定将匹配到的行与前面的行合并还是和后面的行合并. 语法示例: inpu ...
- PHP运行环境搭建
说明 我的百度百度云盘里面有apache24,PHP7.0,mysql5.6,如果需要的话可以直接下载: apache的环境我已经配置好了,将其解压到C盘根目录 相应绝对路径为C:\Apache24 ...
- DNA的分子结构
DNA是由两条链组成的, 这两条链按反相平行的方式盘旋成双螺旋结构 DNA分子中的脱氧核糖和磷酸交替连接, 排列在外侧, 构成基本骨架; 碱基排列在内侧. 两条链上的碱基通过氢键连接成碱基对, 并且其 ...
- windows上安装Ipython notebook
最近有一个培训机构找笔者来做一份Python的培训教材,顺带着研究了下python notebook,发现很好很强大,现把初步的安装步骤记录如下: 1.安装Python ...
- mac 安装scrapy
https://jingyan.baidu.com/article/14bd256e748346bb6d2612be.html 1.安装Python 安装完了记得配置环境,将python目录和pyth ...
- hdu5373
题先附上:水题,可是思路不正确,特easy超时(TLE) The shortest problem Time Limit: 3000/1500 MS (Java/Others) Memory L ...