scrapy分布式原理
scrapy分布式原理
关于Scrapy工作流程回顾
Scrapy单机架构
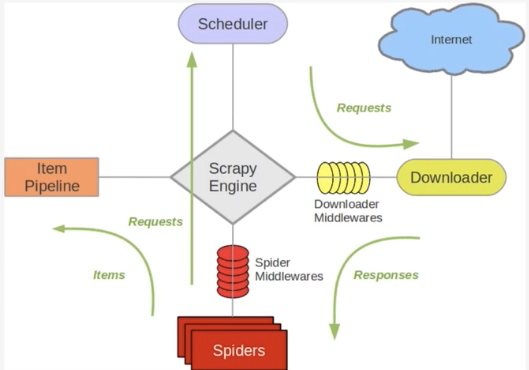
上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列。
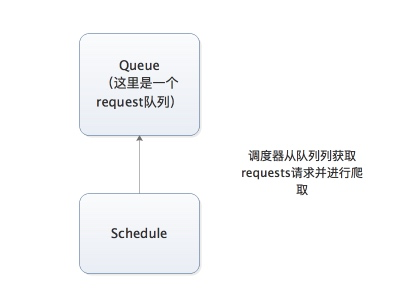
分布式架构
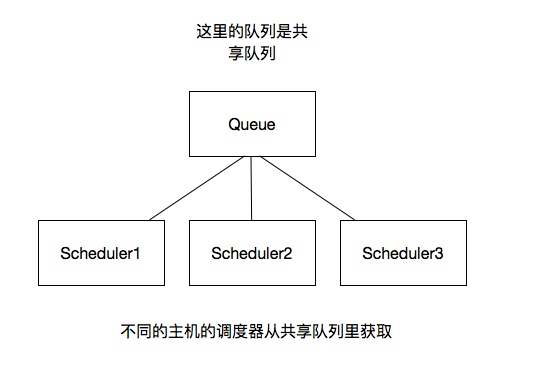
我将上图进行再次更改
这里重要的就是我的队列通过什么维护?
这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Value形式存储,结构灵活。
并且redis是内存中的数据结构存储系统,处理速度快,提供队列集合等多种存储结构,方便队列维护
如何去重?
这里借助redis的集合,redis提供集合数据结构,在redis集合中存储每个request的指纹
在向request队列中加入Request前先验证这个Request的指纹是否已经加入集合中。如果已经存在则不添加到request队列中,如果不存在,则将request加入到队列并将指纹加入集合
如何防止中断?如果某个slave因为特殊原因宕机,如何解决?
这里是做了启动判断,在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空
如果不为空,则从队列中获取下一个request执行爬取。如果为空则重新开始爬取,第一台丛集执行爬取向队列中添加request
如何实现上述这种架构?
这里有一个scrapy-redis的库,为我们提供了上述的这些功能
scrapy-redis改写了Scrapy的调度器,队列等组件,利用他可以方便的实现Scrapy分布式架构
关于scrapy-redis的地址:https://github.com/rmax/scrapy-redis
搭建分布式爬虫
参考官网地址:https://scrapy-redis.readthedocs.io/en/stable/
前提是要安装scrapy_redis模块:pip install scrapy_redis
这里的爬虫代码是用的之前写过的爬取知乎用户信息的爬虫
修改该settings中的配置信息:
替换scrapy调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加这行配置,每次爬取的数据也都会入到redis数据库中,所以一般这里不做这个配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
共享的爬取队列,这里用需要redis的连接信息
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
设置为为True则不会清空redis里的dupefilter和requests队列
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_PERSIST = True
设置重启爬虫时是否清空爬取队列
这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
SCHEDULER_FLUSH_ON_START=True
分布式
将上述更改后的代码拷贝的各个服务器,当然关于数据库这里可以在每个服务器上都安装数据,也可以共用一个数据,我这里方面是连接的同一个mongodb数据库,当然各个服务器上也不能忘记:
所有的服务器都要安装scrapy,scrapy_redis,pymongo
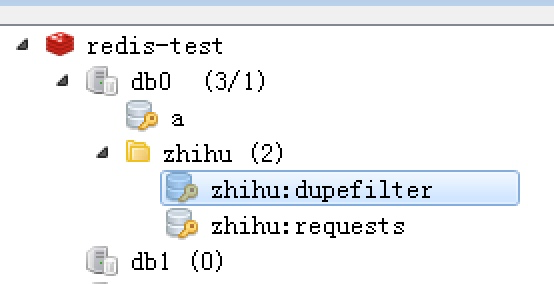
这样运行各个爬虫程序启动后,在redis数据库就可以看到如下内容,dupefilter是指纹队列,requests是请求队列
scrapy分布式原理的更多相关文章
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫【五】Scrapy分布式原理笔记
Scrapy单机架构 在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求 但是这些 ...
- 爬虫(十七):scrapy分布式原理
一:scrapy工作流程 scrapy单机架构: 单主机爬虫架构: 分布式爬虫架构: 这里重要的就是我的队列通过什么维护?这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Valu ...
- Python之爬虫(二十二) Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 学习笔记TF061:分布式TensorFlow,分布式原理、最佳实践
分布式TensorFlow由高性能gRPC库底层技术支持.Martin Abadi.Ashish Agarwal.Paul Barham论文<TensorFlow:Large-Scale Mac ...
- scrapy分布式的几个重点问题
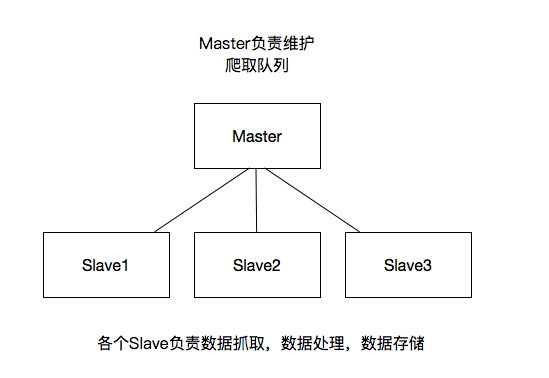
我们之前的爬虫都是在同一台机器运行的,叫做单机爬虫.scrapy的经典架构图也是描述的单机架构.那么分布式爬虫架构实际上就是:由一台主机维护所有的爬取队列,每台从机的sheduler共享该队列,协同存 ...
- scrapy分布式浅谈+京东示例
scrapy分布式浅谈+京东示例: 学习目标: 分布式概念与使用场景 浅谈去重 浅谈断点续爬 分布式爬虫编写流程 基于scrapy_redis的分布式爬虫(阳关院务与京东图书案例) 环境准备: 下载r ...
随机推荐
- 操作系统:Bochs 2.6.8的配置文件bochsrc.bxrc修改
由于现在Bochs 2.6.8相比之前有些改动,之前的配置文件不能直接运行,针对配置文件需要有些修改. 1. 配置文件 ######################################## ...
- 基于BASYS2的VHDL程序——数字钟
在编电子表时发现FPGA求余,取模只能针对2的次方.毕竟是数字的嘛! 时钟用到了动态刷新数码管.以一个大于50Hz的速度刷新每一个数码管. 因为数码管只有四个,只写了分针和秒针. 代码如下: libr ...
- 旋转屏幕导致Activity重建
简单来说,Activity是负责与用户交互的最主要机制,任何“设置”(Configuration)的改变都可能对Activity的界面造成影响,这时系统会销毁并重建Activity以便反映新的Conf ...
- 用margin还是用padding?(3)—— 负margin实战
看过一篇文章是关于我知道你不知道的负Margin,里面对margin做了总结: 当margin四个值都为正数值的话,那么margin按照正常逻辑同周围元素产生边距.当元素margin的top和left ...
- WPF-悬浮在底部的导航
先用Rectangle代替导航按钮,这个导航会悬浮在界面的底部,当鼠标移进导航按钮上的时候,按钮会放大,移出后恢复正常. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 ...
- tensorflow 线性回归解决 iris 2分类
# Combining Everything Together #---------------------------------- # This file will perform binary ...
- nvidia-smi 查看GPU信息字段解读
第一栏的Fan:N/A是风扇转速,从0到100%之间变动,这个速度是计算机期望的风扇转速,实际情况下如果风扇堵转,可能打不到显示的转速.有的设备不会返回转速,因为它不依赖风扇冷却而是通过其他外设保持低 ...
- iOS 中这些是否熟练掌握——(1)
声明:本篇博文是作者原创作品.参考1 参考2 参考3 参考4 参考5 参考6 关于网上一些关于iOS资料,自己通过学习做了一些整理,这里仅仅作为笔记,方便自己学习使用,加深理解. 1.什么是 ...
- Asset Catalog Help (七)---Customizing Image Sets for Size Classes
Customizing Image Sets for Size Classes Add images to a set that are customized for display in diffe ...
- Eigen中的noalias(): 解决矩阵运算的混淆问题
作者:@houkai本文为作者原创,转载请注明出处:http://www.cnblogs.com/houkai/p/6349990.html 目录 混淆例子解决混淆问题混淆和component级的操作 ...