python爬虫——词云分析最热门电影《后来的我们》
1 模块库使用说明
1.1 requests库
requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
1.2 urllib库
urllib的request模块可以非常方便地抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应.
1.3jieba库
结巴”中文分词:做最好的 Python 中文分词组件
1.4 BeautifulSoup库
Beautiful Soup是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航navigating,搜索以及修改剖析树的操作。
1.5pandas库
pandas是python的一个非常强大的数据分析库,常用于数据分析。
1.6 re库
正则表达式re(通项公式)是用来简洁表达一组字符串的表达式。优势是简洁。使用它来进行字符串处理。
1.7 wordcloud库
python中使用wordcloud包生成的词云图。我们最后要生成当前热映电影的分析词云。
2需求说明
介绍要做什么,将采用的方法、预期得到的结果是什么及其他需求说明。
爬取豆瓣网站https://movie.douban.com/cinema/nowplaying/ankang/ 城市为安康的豆瓣电影数据主要完成以下三个步骤
抓取网页数据
清理数据
用词云进行展示
使用的python版本是3.6.并使用中文分词,词云对豆瓣电影排行榜排行第一的电影进行数据分析,进行相应的词云展示。
3抓取和处理数据算法
1)安装request模块
1.1)安装需要用到的beautifulsoup模块
2)查看要爬取网站的结构
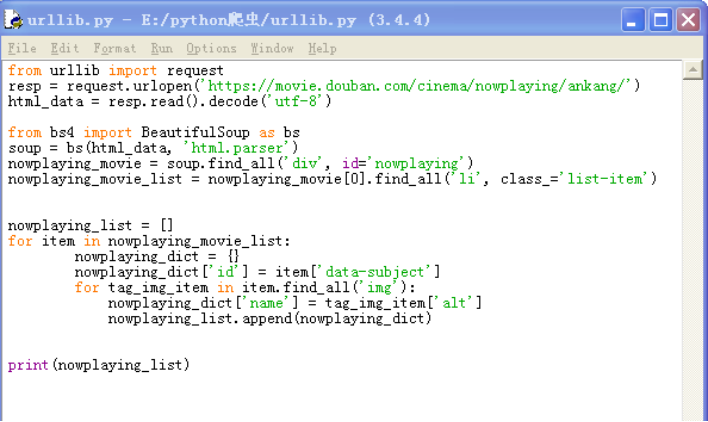
3)初步代码实现
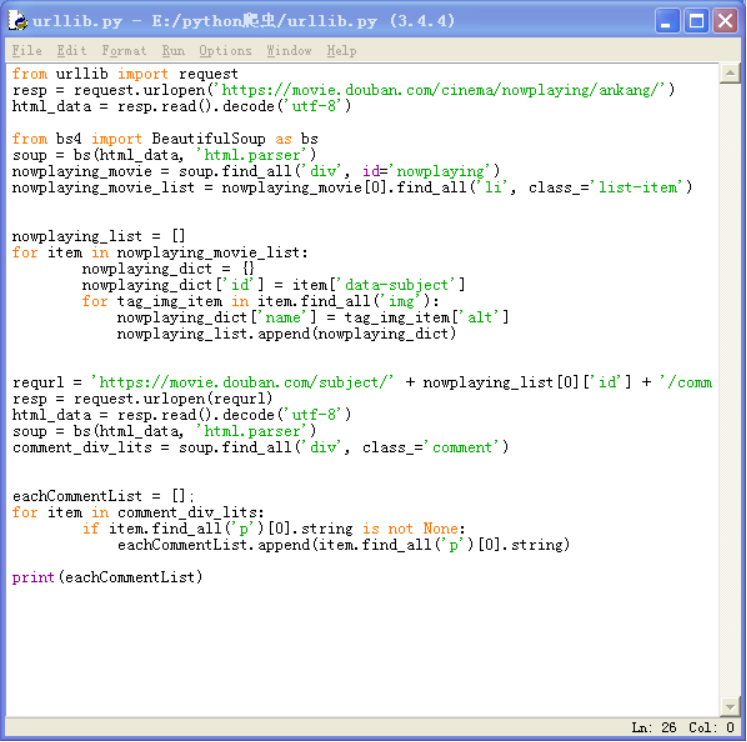
3.1)初步爬取到当前的院线上映信息
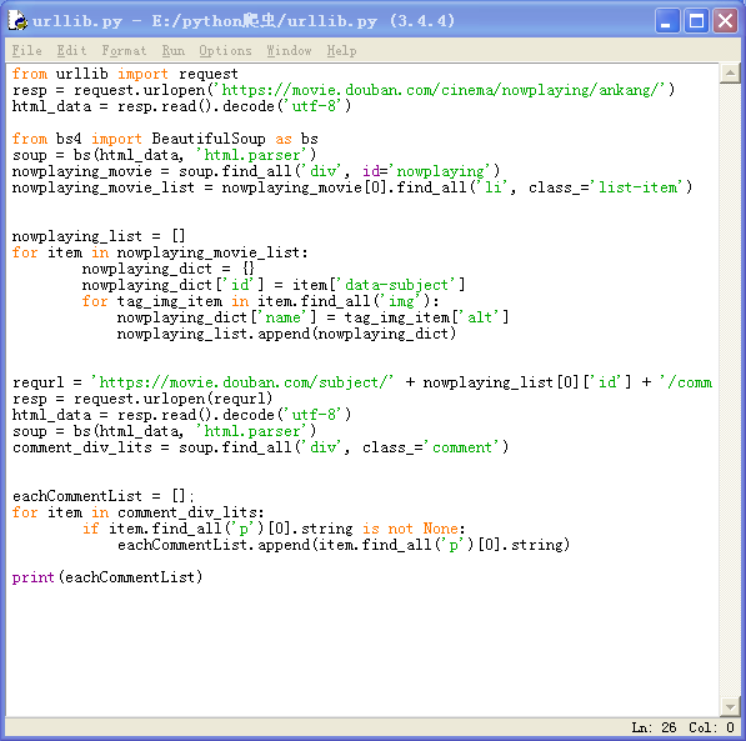
4.1)抓取到热映电影的第一个热评信息代码
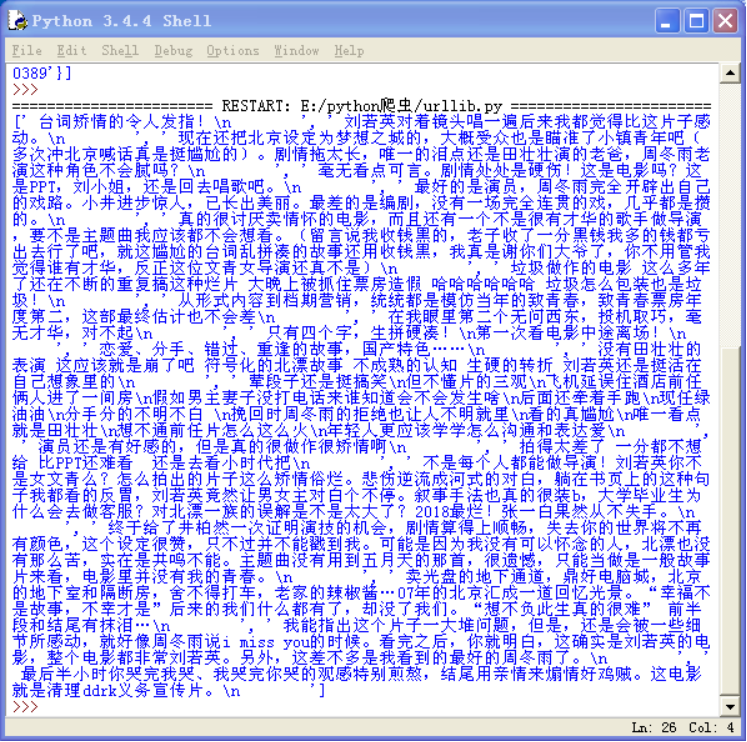
4.2)成功显示热评信息
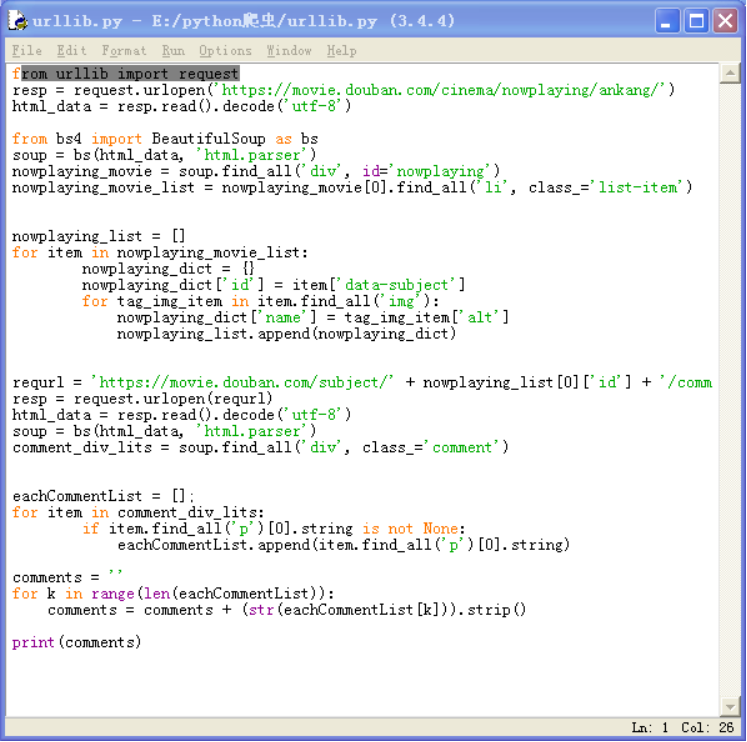
5.1)进行数据清洗上一步中格式错乱的代码
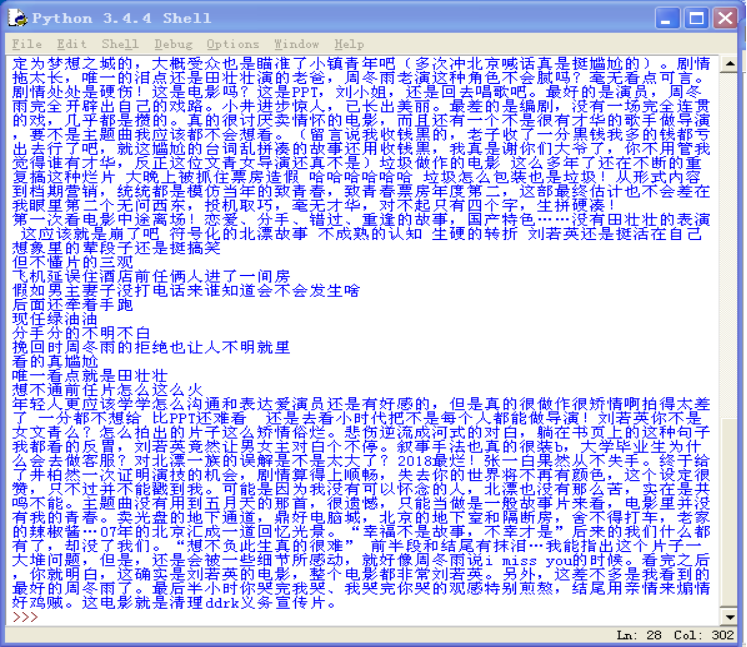
5.2)数据清洗后的《后来的我们》评论信息
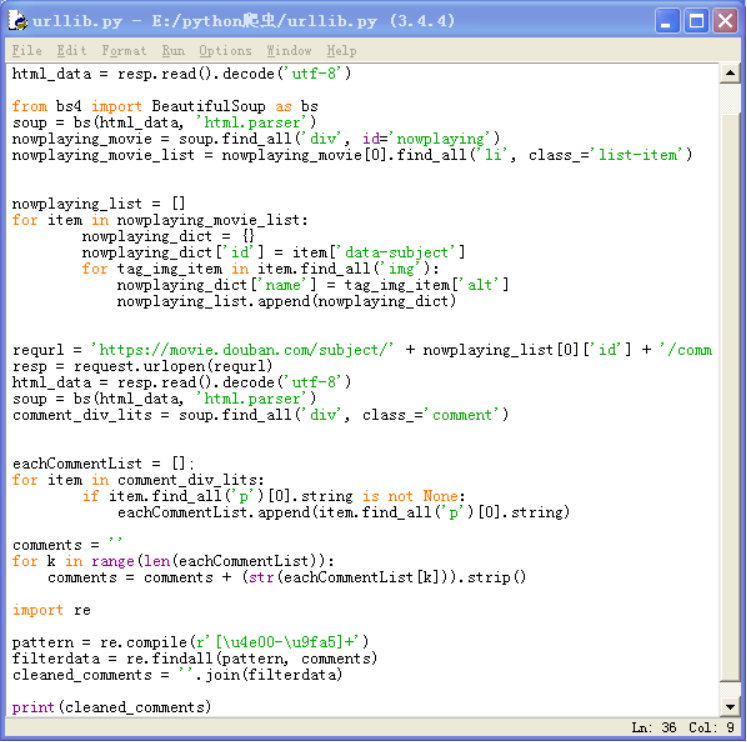
5.3)再次进行数据清洗去除掉标点符号代码
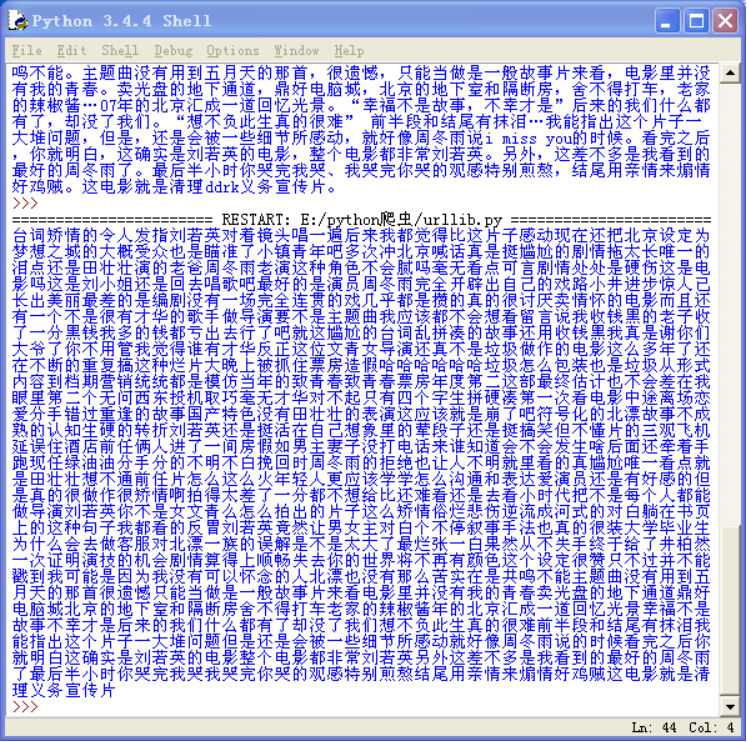
5.4)去除掉标点符号后的数据

6.1)安装pandas模块 ,用此方法依次安装wordcloud 库等。
def main():
# 循环获取第一个电影的前10页评论
commentList = []
NowPlayingMovie_list = getNowPlayingMovie_list()
for i in range(10):
num = i + 1
commentList_temp = getCommentsById(NowPlayingMovie_list[0]['id'], num)
commentList.append(commentList_temp)
使用for语句循环遍历获取排行榜第一的电影的前十页评论
完整代码:
# coding:utf-8
__author__ = 'LiuYang'
import warnings
warnings.filterwarnings("ignore")
import jieba # 分词包
import numpy # numpy计算包
import codecs # codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
import re
import pandas as pd
import matplotlib.pyplot as plt
from urllib import request
from bs4 import BeautifulSoup as bs
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
from wordcloud import WordCloud # 词云包
# 分析网页函数
def getNowPlayingMovie_list():
resp = request.urlopen('https://movie.douban.com/nowplaying/ankang/') # 爬取安康地区的豆瓣电影信息
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')
nowplaying_list = []
for item in nowplaying_movie_list:
nowplaying_dict = {}
nowplaying_dict['id'] = item['data-subject']
for tag_img_item in item.find_all('img'):
nowplaying_dict['name'] = tag_img_item['alt']
nowplaying_list.append(nowplaying_dict)
return nowplaying_list
# 爬取评论函数
def getCommentsById(movieId, pageNum):
eachCommentList = [];
if pageNum > 0:
start = (pageNum - 1) * 20
else:
return False
requrl = 'https://movie.douban.com/subject/' + movieId + '/comments' + '?' + 'start=' + str(start) + '&limit=20'
print(requrl)
resp = request.urlopen(requrl)
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
comment_div_lits = soup.find_all('div', class_='comment')
for item in comment_div_lits:
if item.find_all('p')[0].string is not None:
eachCommentList.append(item.find_all('p')[0].string)
return eachCommentList
def main():
# 循环获取第一个电影的前10页评论
commentList = []
NowPlayingMovie_list = getNowPlayingMovie_list()
for i in range(10):
num = i + 1
commentList_temp = getCommentsById(NowPlayingMovie_list[0]['id'], num)
commentList.append(commentList_temp)
# 将列表中的数据转换为字符串
comments = ''
for k in range(len(commentList)):
comments = comments + (str(commentList[k])).strip()
# 使用正则表达式去除标点符号
pattern = re.compile(r'[\u4e00-\u9fa5]+')
filterdata = re.findall(pattern, comments)
cleaned_comments = ''.join(filterdata)
# 使用结巴分词进行中文分词
segment = jieba.lcut(cleaned_comments)
words_df = pd.DataFrame({'segment': segment})
# 去掉停用词
stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep="\t", names=['stopword'],
encoding='utf-8') # quoting=3全不引用
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
# 统计词频
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
# 用词云进行显示
wordcloud = WordCloud(font_path="simhei.ttf", background_color="white", max_font_size=80)
word_frequence = {x[0]: x[1] for x in words_stat.head(1000).values}
word_frequence_list = []
for key in word_frequence:
temp = (key, word_frequence[key])
word_frequence_list.append(temp)
wordcloud = wordcloud.fit_words(dict (word_frequence_list))
plt.imshow(wordcloud)
plt.savefig("ciyun_jieguo .jpg")
# 主函数
main()
成功获取到结果
到代码路径获取词云结果图片如图:
词云结果图

4结果分析说明
选取安康地区院线电影排行信息,首先对正在上映的电影进行分析,获得最热门的电影信息,第二步对排行中最热门的电影《后来的我们》进行评论抓取,进行数据清洗,去除掉格式错误的错误信息,去除掉标点,中文的叠词,获取到出现频率最高的词汇,为了保证获取到的词云信息准确性,并且循环遍历十页评论信息,统计计数,再通过词云获取到此电影的词云信息。
由最终获得的词云分析图可知,我们顺利的爬取了安康地区的豆瓣电影信息,影院当前正在上映的电影信息,由此得到热门电影《后来的我们》此电影的特征标签,也基本上反映了这部电影的情况,观影者的感受,电影的主要角色,导演信息等一目了然。
python爬虫——词云分析最热门电影《后来的我们》的更多相关文章
- 如何用Python 制作词云-对1000首古诗做词云分析
公号:码农充电站pro 主页:https://codeshellme.github.io 今天来介绍一下如何使用 Python 制作词云. 词云又叫文字云,它可以统计文本中频率较高的词,并将这些词可视 ...
- 使用Python定制词云
一.实验介绍 1.1 实验内容 在互联网时代,人们获取信息的途径多种多样,大量的信息涌入到人们的视线中.如何从浩如烟海的信息中提炼出关键信息,滤除垃圾信息,一直是现代人关注的问题.在这个信息爆炸的时代 ...
- 如何用Python做词云(收藏)
看过之后你有什么感觉?想不想自己做一张出来? 如果你的答案是肯定的,我们就不要拖延了,今天就来一步步从零开始做个词云分析图.当然,做为基础的词云图,肯定比不上刚才那两张信息图酷炫.不过不要紧,好的开始 ...
- 一步一步教你如何用Python做词云
前言 在大数据时代,你竟然会在网上看到的词云,例如这样的. 看到之后你是什么感觉?想不想自己做一个? 如果你的答案是正确的,那就不要拖延了,现在我们就开始,做一个词云分析图,Python是一个当下很流 ...
- 使用python绘制词云
最近在忙考试的事情,没什么时间敲代码,一个月也没几天看代码,最近看到可视化的词云,看到网上也很多这样的工具, 但是都不怎么完美,有些不支持中文,有的中文词频统计得莫名其妙.有的不支持自定义形状.所有的 ...
- python爬取花木兰豆瓣影评,并进行词云分析
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 python免费学习资 ...
- 用Python做词云可视化带你分析海贼王、火影和死神三大经典动漫
对于动漫爱好者来说,海贼王.火影.死神三大动漫神作你肯定肯定不陌生了.小编身边很多的同事仍然深爱着这些经典神作,可见"中毒"至深.今天小编利用Python大法带大家分析一下这些神作 ...
- Python 词云分析周杰伦《晴天》
一.前言满天星辰的夜晚,他们相遇了...夏天的时候,她慢慢的接近他,关心他,为他付出一切:秋天的时候,两个人终於如愿的在一起,分享一切快乐的时光但终究是快乐时光短暂,因为杰伦必须出国深造,两人面临了要 ...
- [python] 基于词云的关键词提取:wordcloud的使用、源码分析、中文词云生成和代码重写
1. 词云简介 词云,又称文字云.标签云,是对文本数据中出现频率较高的“关键词”在视觉上的突出呈现,形成关键词的渲染形成类似云一样的彩色图片,从而一眼就可以领略文本数据的主要表达意思.常见于博客.微博 ...
随机推荐
- iOS中 FMDB第三方SQLite数据库 UI_20
1.什么是FMDB? FMDB是iOS平台下SQLite数据库,只不过它是OC方式封装了C语言的SQLite语句,使用起来更加面向对象 2.FMDB的优点:1.使用起来更加面向对象; 2.对比苹果自带 ...
- cocos2d-x初探
今天把cocos2d-x下载下来装了准备试试. 就不用windows本了,主要想做iOS游戏,所以这里用mac. 先在http://cocos2d-x.org/download下载右边的cocos,然 ...
- java常用集合类详解(有例子,集合类糊涂的来看!)
Framework集合框架是一个统一的架构,用来表示和操作集合.集合框架主要是由接口,抽象类和实现类构成.接口:蓝色:实现类:红色Collection|_____Set(HashSet)| ...
- 控件的基本使用-iOS—UI笔记
学习目标 1.[掌握]第一个UI项目 2.[掌握]控件连线 3.[掌握]按钮的基本操作 4.[掌握]控件的常用属性 一.第一个UI项目 UI (User Interface)也是就用户界面,是App的 ...
- Order Management Useful Scripts
Listed some useful queries scripts for Oracle Order Management Flow. (For Order Management Detailed ...
- ORACLE DB TRIGGER详解
本篇主要内容如下: 8.1 触发器类型 8.1.1 DML触发器 8.1.2 替代触发器 8.1.3 系统触发器 8.2 创建触发器 8.2.1 触发器触发次序 8.2.2 创建DML触发器 8.2. ...
- 在Windows下搭建Gitlab服务器
一.GitLab简介 GitLab 是一个用于仓库管理系统的开源项目.使用Git作为代码管理工具,并在此基础上搭建起来的web服务. 可通过Web界面进行访问公开的或者私人项目.它拥有与Github类 ...
- Linux下使用GDAL进行开发(automake使用)
首先写三个源代码文件,分别是GDALTest.cpp.Fun.cpp和Fun.h,将这三个存放在一个叫GDALTest的文件夹中,然后打开终端,切换到该目录,如下图所示(注:这个图是最后截图的,所以文 ...
- 某集团BI决策系统建设方案分享
企业核心竞争能力的提升,需要强壮的运营管理能力,需要及时.准确.全面的业务数据分析作为参考与支撑. 某集团是大型时尚集团,内部报表系统用的QlikView,但是管理分配不够灵活,不能满足数据安全的要求 ...
- hive:(group by, having;order by)的使用;group by+多个字段,以及wiki说的group by两种使用限制验证
hive> select * from app_data_stats_historical where os='1' group by dt limit 100; 出现结果如下: 2014-01 ...