论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search
2019-03-19 10:04:26
accepted by ICLR 2019
Paper:https://arxiv.org/pdf/1806.09055.pdf
Code:https://github.com/quark0/darts
1. Motivation and Background:
前人的网络搜索方法,要么是基于 RL 的,要么是基于进化算法的,都是非常耗时的,最近的几个算法表示他们的计算时间可能需要:1800 GPU days 以及 3150 GPU days。虽然现在也有人对其进行加速处理(Speed Up),例如:
imposing a particular structure of the search space (Liu et al., 2017b,a),
weights or performance prediction for each individual architecture (Brock et al., 2017; Baker et al., 2018)
weight sharing across multiple architectures (Pham et al., 2018b; Cai et al., 2018),
但是 scalability 根本性的挑战并没有得到很好的解决。而导致这种低效率的原因在于:他们将结构搜索这个任务当做是一个 离散领域的黑盒优化问题(Block-box optimization problem over a discrete domain),从而导致需要评价大量的结构。
在本文中,作者从不同的角度来解决这个问题,并且提出一种称为 DARTS(Differentiable ARchiTecture Search) 的方法来进行有效的结构搜索。并非在候选结构的离散集合中进行搜索,而是将搜索空间松弛到连续的领域,从而可以通过梯度下降的方式,用验证集效果的高低,来进行优化。基于梯度优化的数据效率,与低效率的 block-box 搜索方式相比较,可以得到更加相当的精度,并且可以少用相当多的计算资源。同时,也比现有的改进方法要好,ENAS。可以同时进行卷积和循环结构的搜索。
在连续领域中利用结构搜索并不是很新,但是仍然有几个重大的区别:
首先,前人的工作尝试微调特定方面的结构,如 filter shapes 或者 分支模式,而 DARTS 可以发现复杂的图拓扑,实现高性能的结构;
其次,并不受限于特定结构,可以同时发掘 卷积 和 循环网络。
2. Differentiable Architecture Search:
2.1 Search Space:
跟随前人的工作,我们搜索一个计算单元(computation cell)作为最终结构的构建模块(building block)。该学习的单元可以堆叠成 convolutional network 或者 循环链接得到一个 recurrent network。
一个 cell 是一个 directed acyclic graph,是一个由 N 个 nodes 组成的有序的序列。每一个节点 $x^{(i)}$ 是一个隐藏表达(即,feature map),有向边 (i, j) 是用一些操作 $o^{(i, j)}$ 用于转换 $x^{(i)}$。我们假设该 cell 是由两个输入节点,以及单个输出节点。对于 convolutional cells,输入节点是由前两层的 cell 输出定义得到的。对于 recurrent layer,这些被定义为当前时刻的输入,以及从前一个时刻的状态(states)。cell 的输出是通过对所有的即刻节点(intermediate nodes) concatenation 得到的。
每一个即刻节点都是通过如下的方式进行计算的:

一个特殊的 zero operation 也被引入,来表示两个节点之间不存在链接。所以,cell 的学习被简化为:learning the operations on its edges。
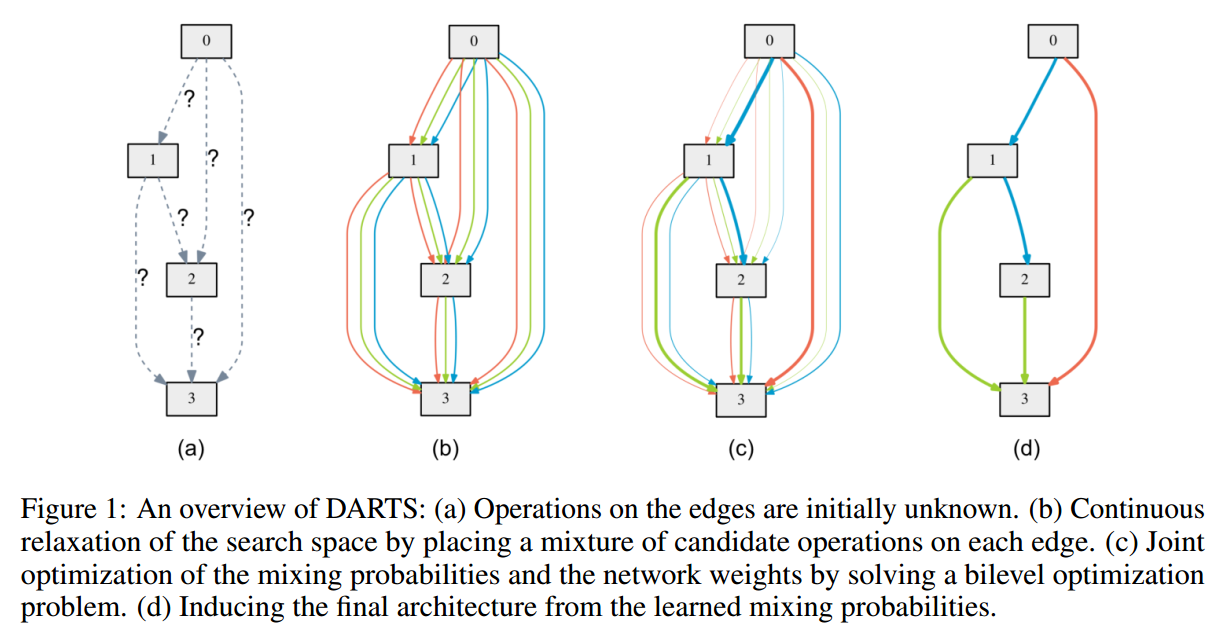
2.2 Continuous Relaxation and Optimization:
假设 O 表示候选操作的集合(即,convolution, max pooling, zero),其中,每一个操作符代表一些函数 o(*) 作用于 $x^{(i)}$。为了使得搜索空间变的连续,我们将特定操作的种类选择松弛为:所有可能操作的 softmax 函数:
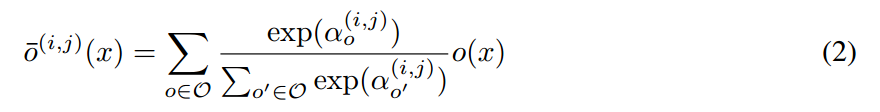
其中,一对节点(i, j)的操作混合权重,是由向量 $\alpha^{(i, j)}$ 进行参数化表示的。在松弛之后,该结构搜索任务就变成了:学习一组连续变量 $\alpha = {\alpha^{(i, j)}}$,如图 1 所示。在搜索结束之后,我们通过将最像的操作来替换掉每个混合操作符,就获得了一个离散的结构,即:
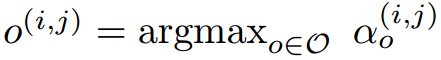
在接下来,我们将 $\alpha$ 表示为结构的编码。
在松弛之后,我们的目标是:联合的学习结构化参数 $\alpha$ 和 权重 $w$ 。与强化学习 或者 进化算法类似,我们将验证集的性能看做是最终的奖励或者拟合程度,DARTS 的目标就是优化该验证集损失,但是用的是 gradient descent。
我们用 $L_{train}$ and $L_{val}$ 表示 训练和验证集的损失。这两个损失不但由结构 $\alpha$ ,也与网络的权重 $w$ 相关。结构化搜索的目标是:找到一个最优的参数 $\alpha*$ 使其可以最小化验证集的损失函数 $L_{val} (w*, \alpha*)$,并且与结构相关的模型权重 $w*$ 也紧跟着通过最小化 训练集损失而得到,即:$w* = arg min_w L_{train} (w, \alpha^*)$。
这是一个 bilevel optimization problem,其中 $\alpha$ 是 upper-level variable,$w$ 是 lower-level variable:
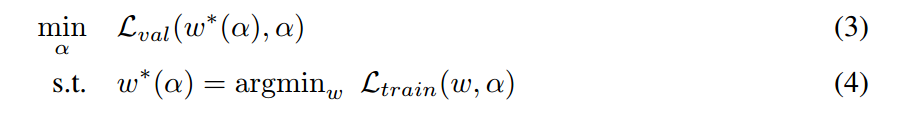
这个嵌套的表达也在 gradient-based hyperparameter optimization 中被提出,虽然其维度较高,且更难被优化。
2.3 Approximation:
求解上述双向优化问题,计算量是非常大的,因为一旦上层的 $\alpha$ 变掉了,那么,里面模型的权重 $w*(\alpha)$ 就必须重新计算。我们所以提出一种近似的迭代优化策略:将 w 和 $\alpha$ 用梯度下降步骤来相互优化,如算法 1 所示。

在 step k,给定当前的结构 $\alpha_{k-1}$,我们通过朝向降低训练损失的方向去移动 $w_{k-1}$ 来得到 $w_k$。然后,保持权重 $w_k$ 不变,去更新网络结构,使其可以最小化验证集损失(在执行一次梯度下降之后):
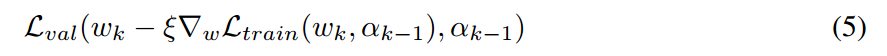
其中,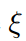 是该虚拟梯度步骤的学习率。公式 5 的动机是:we would like to find an architecture which has a low validation loss when its weights are optimized by (a single step of) gradient descent, where the one-step unrolled weights serve as the surrogate for w∗(α).
是该虚拟梯度步骤的学习率。公式 5 的动机是:we would like to find an architecture which has a low validation loss when its weights are optimized by (a single step of) gradient descent, where the one-step unrolled weights serve as the surrogate for w∗(α).
一个相关的方法也被用于 meta-learning 来进行模型迁移。需要注意的是,作者所提出的这种动态迭代算法,定义了一种 $\alpha$'s optimizer (leader) 和 $w$'s optimizer (follower) 之间的 Stackelberg game ,为了达到平衡,这通常要求 the leader 参与到 follower 的下一步移动。我们当前没有注意到收敛性保证,实际上,适当的调整学习率,是可以确保收敛的。我们也注意到:对于权重优化,当动量可以确保时,one-step forward learning objective(5)也被随之而改变,所以我们的分析,都是适用的。
通过微分公式 5,我们可以得到结构梯度,即 $\alpha$:
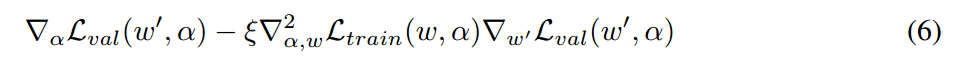
其中, 代表一个 one-step forward model 的权重。公式 6 的第二项包含了一个 matrix-vector product,其计算代价昂贵。幸好,finite difference approximation 可以用于降低其复杂性。用
代表一个 one-step forward model 的权重。公式 6 的第二项包含了一个 matrix-vector product,其计算代价昂贵。幸好,finite difference approximation 可以用于降低其复杂性。用 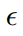 表示一个小的 scalar,那么我们有:
表示一个小的 scalar,那么我们有:
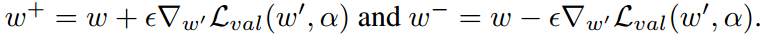
然后,我们可以得到:
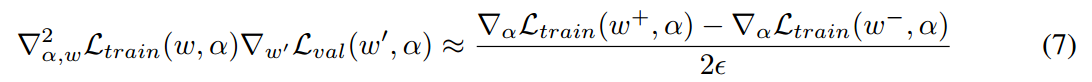
评估该 finite difference 仅需要两次前向传播即可得到 weights,两次反向传播,就可以得到 $\alpha$,运算复杂度大大的降低了:
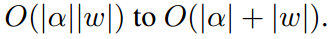
First-order Approximation:
当学习率 为 0,公式 6 中的二阶衍生物就消失了。在这种情况下,结构梯度就是: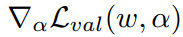 。
。

2.4 Deriving Discrete Architectures:
在得到连续结构编码 $\alpha$ 之后,离散的结构可以通过如下的结构得到:
1). Retaining k strongest predecessors for each intermediate node, where the strength of an edge is defined as:
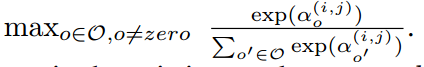
2). Replacing every mixed operation as the most likely operation by taking the argmax.
3. Experiments and Results:
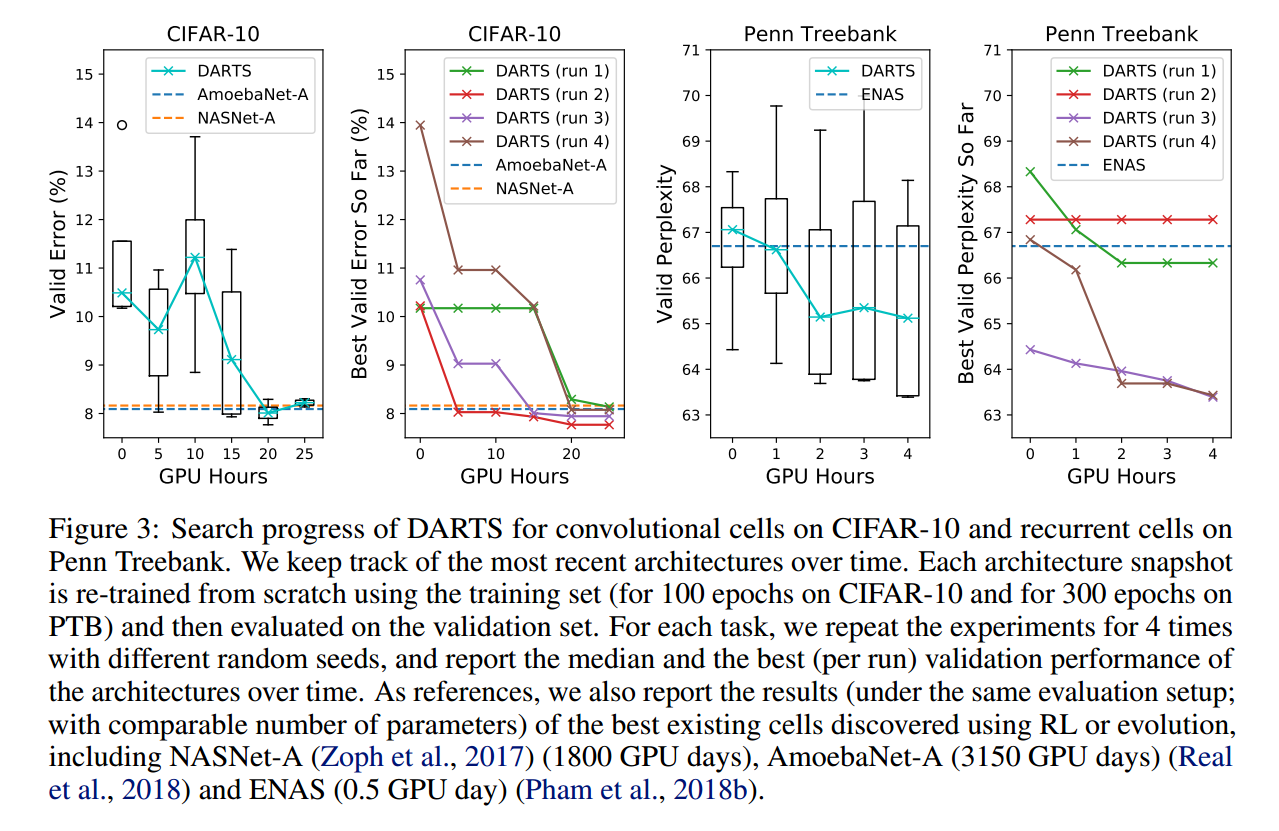
作者在 CIFAR-10 和 PTB 上面做了实验,分为两个阶段:architecture search 和 architecture evaluation。
在第一个阶段,作者搜索 the cell architectures,然后根据其 验证集的性能,确定最优的 cell。
在第二个阶段,我们利用这些 cell 来构建大型的结构,然后 train from scratch,并且在测试集上查看最终性能。
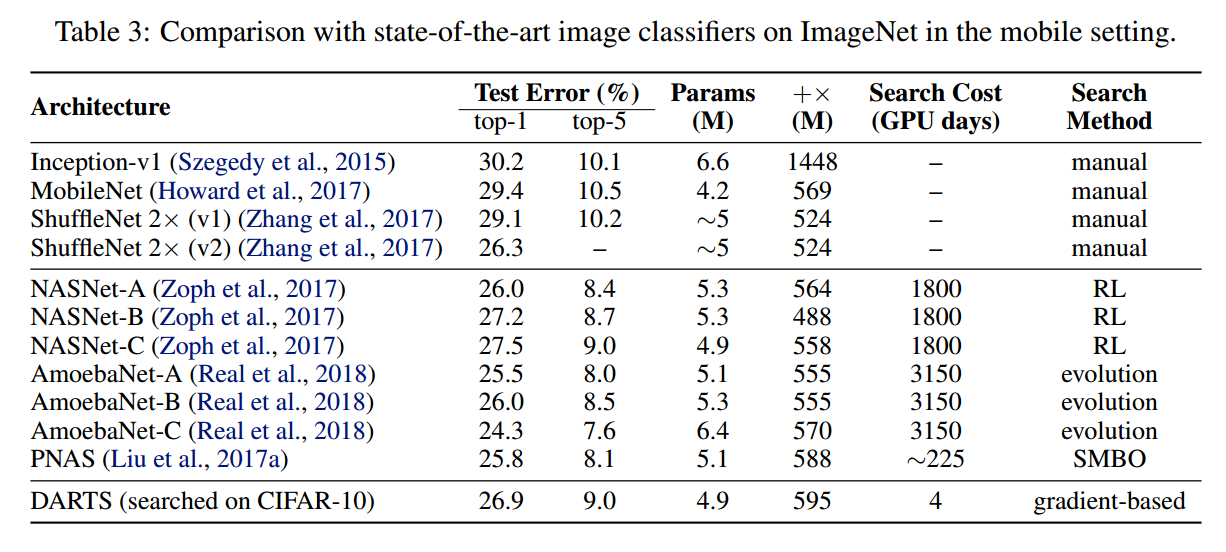
最终,作者探索了 the best cells 的迁移能力,并且在 ImageNet 和 WikiText-2 (WT2)数据集上进行了性能测试。
划重点:

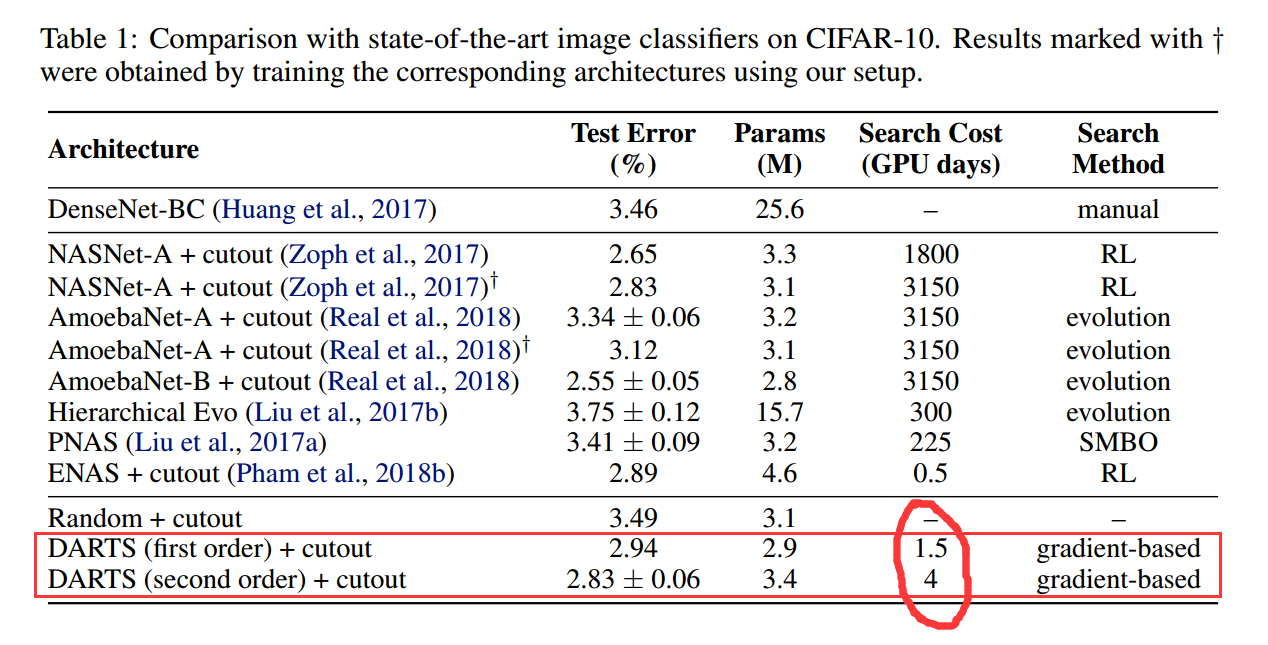
效果对比:

==
论文笔记:DARTS: Differentiable Architecture Search的更多相关文章
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
摘要 神经网络在多个领域都取得了不错的成绩,但是神经网络的合理设计却是比较困难的.在本篇论文中,作者使用 递归网络去省城神经网络的模型描述,并且使用 增强学习训练RNN,以使得生成得到的模型在验证集上 ...
- 论文笔记:Progressive Differentiable Architecture Search:Bridging the Depth Gap between Search and Evaluation
Progressive Differentiable Architecture Search:Bridging the Depth Gap between Search and Evaluation ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 2019-ICCV-PDARTS-Progressive Differentiable Architecture Search Bridging the Depth Gap Between Search and Evaluation-论文阅读
P-DARTS 2019-ICCV-Progressive Differentiable Architecture Search Bridging the Depth Gap Between Sear ...
- [论文笔记] A Practical Architecture of Cloudification of Legacy Applications (2011, SERVICES)
Dunhui Yu, Jian Wang, Bo Hu, Jianxiao Liu, Xiuwei Zhang, Keqing He, and Liang-Jie Zhang. 2011. A Pra ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 【论文笔记系列】AutoML:A Survey of State-of-the-art (下)
[论文笔记系列]AutoML:A Survey of State-of-the-art (上) 上一篇文章介绍了Data preparation,Feature Engineering,Model S ...
- Research Guide for Neural Architecture Search
Research Guide for Neural Architecture Search 2019-09-19 09:29:04 This blog is from: https://heartbe ...
随机推荐
- 2PC/3PC/Paxos
在分布式系统中,一个事务可能涉及到集群中的多个节点.单个节点很容易知道自己执行的事务成功还是失败,但因为网络不可靠难以了解其它节点的执行状态(可能事务执行成功但网络访问超时). 若部分节点事务执行失败 ...
- iconfont在线链接使用方法(转)
原文:https://blog.csdn.net/jinkingliao/article/details/51353937 基础流程就不多赘述,直接到http://www.iconfont.cn/官网 ...
- opencart3调用三级菜单level 3 sub categories
Opencart 3的menu菜单默认只调用一级和二级菜单,但很多电商网站类目复杂,三级菜单一般都是需要的,甚至更深,那么如何调用三级菜单level 3 sub categories呢?ytkah有一 ...
- 2018-2019-2 20175211 实验二《Java面向对象程序设计》实验报告
目录 代码托管 一.单元测试 (1)三种代码 二.TDD(Test Driven Development,测试驱动开发) 三.面对对象三要素 四.练习 五.问题及解决 六.PSP 代码托管 一.单元测 ...
- string函数详解(配案例)
多说无益上码~ #include<iostream> #include<algorithm> #include<cmath> #include<cstring ...
- mysql中utf8和utf8mb4区别
一.什么是utf8mb4 MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode.好在utf8mb4是utf8的超集,除 ...
- 排序之选择排序(SelectSort)
package com.sort; /* * 选择排序 * 把第一位与其他数进行比较,这样每轮比较都会出现一个最大值或最小值 * 根据需要让升序或降序排列 */ public class Select ...
- .net连接数据库递归
private void Form1_Load(object sender, EventArgs e) { List<Regions> regions = GetRegions().Whe ...
- Vuex 2.0 深入简出
最近面试充斥了流行框架Vue的各种问题,其中Vuex的使用就相当有吸引力.下面我就将自己深入简出的心得记录如下: 1.在vue-init webpack project (创建vue项目) 2.src ...
- 【论文速读】Shangbang Long_ECCV2018_TextSnake_A Flexible Representation for Detecting Text of Arbitrary Shapes
Shangbang Long_ECCV2018_TextSnake_A Flexible Representation for Detecting Text of Arbitrary Shapes 作 ...