sklearn pipeline
sklearn.pipeline
pipeline的目的将许多算法模型串联起来,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流。
优点:
1.直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测
2.可以结合grid search对参数进行选择。
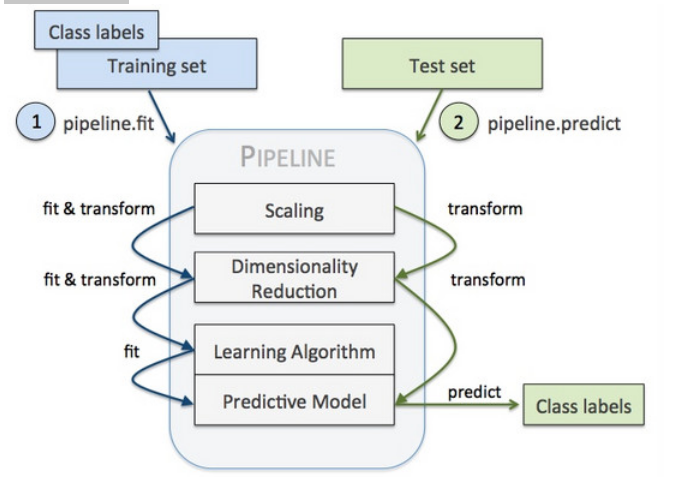
1.DictVectorizer、DecisionTreeClassifier——>pipeline模型
import pandas as pd
import numpy as np
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
titanic.head()
titanic.info()
X = titanic[['pclass','age','sex']]
y = titanic['survived']
X['age'].fillna(X['age'].mean(),inplace=True)
X.info()
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33)
X_train = X_train.to_dict(orient='record')
X_test = X_test.to_dict(orient='record')
#将非数值型数据转换为数值型数据
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.pipeline import Pipeline
'''
vec = DictVectorizer()
vec.fit_transform(data)
clf = DecisionTreeClassifier(random_state=0)
clf.fit(X_train,y_train)
clf.predict(X_test)
'''
clf = Pipeline([('vecd',DictVectorizer(sparse=False)),('dtc',DecisionTreeClassifier())])
vec = DictVectorizer(sparse=False)
clf.fit(X_train,y_train)
y_predict = clf.predict(X_test)
from sklearn.metrics import classification_report
print (clf.score(X_test,y_test))
print(classification_report(y_predict,y_test,target_names=['died','survivied']))
2.结合GridSearch进行参数调优
from sklearn.datasets import fetch_20newsgroups
import numpy as np
news = fetch_20newsgroups(subset='all')
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(news.data[:3000],news.target[:3000],test_size=0.25,random_state=33)
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer()
X_count_train = vec.fit_transform(X_train)
X_count_test = vec.transform(X_test)
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
#使用pipeline简化系统搭建流程,将文本抽取与分类器模型串联起来
clf = Pipeline([
('vect',TfidfVectorizer(stop_words='english')),('svc',SVC())
])
# 注意,这里经pipeline进行特征处理、SVC模型训练之后,得到的直接就是训练好的分类器clf
parameters = {
'svc__gamma':np.logspace(-2,1,4),
'svc__C':np.logspace(-1,1,3),
'vect__analyzer':['word']
}
#n_jobs=-1代表使用计算机的全部CPU
from sklearn.grid_search import GridSearchCV
gs = GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3,n_jobs=-1)
%time _=gs.fit(X_train,y_train)
print (gs.best_params_,gs.best_score_)
print (gs.score(X_test,y_test))
parameters变量里面的key都有一个前缀,不难发现,这个前缀其实就是在Pipeline中定义的操作名。二者相结合,是我们的代码变得十分简洁。
sklearn pipeline的更多相关文章
- sklearn Model-selection + Pipeline
1 GridSearch import numpy as np from sklearn.datasets import load_digits from sklearn.ensemble impor ...
- sklearn中的Pipeline
在将sklearn中的模型持久化时,使用sklearn.pipeline.Pipeline(steps, memory=None)将各个步骤串联起来可以很方便地保存模型. 例如,首先对数据进行了PCA ...
- sklearn 中的 Pipeline 机制 和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- sklearn 中的 Pipeline 机制
转载自:https://blog.csdn.net/lanchunhui/article/details/50521648 from sklearn.pipeline import Pipeline ...
- 利用sklearn的Pipeline简化建模过程
很多框架都会提供一种Pipeline的机制,通过封装一系列操作的流程,调用时按计划执行即可.比如netty中有ChannelPipeline,TensorFlow的计算图也是如此. 下面简要介绍skl ...
- sklearn中pipeline的用法和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- 机器学习- Sklearn (交叉验证和Pipeline)
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用.那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_valid ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- 使用sklearn优雅地进行数据挖掘【转】
目录 1 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术2 并行处理 2.1 整体并行处理 2.2 部分并行处理3 流水线处理4 自动化调参5 持久化6 回 ...
随机推荐
- Data assimilation
REF: https://en.wikipedia.org/wiki/Data_assimilation Data assimilation is the process by which obser ...
- shell进程中的特殊状态变量
$?:获取执行上一个指令的执行状态返回值(0为成功,非0为失败) $$:获取当前执行的shell脚本的进程号(PID) $!:获取上一个在后台工作的进程的进程号 $_:获取在此之前执行的命令或脚本的最 ...
- TCP 总结
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的.可靠的.基于字节流的传输层通信协议,由IETF的RFC 793定义. [TCP连接的特点] [ref ...
- Keil的断点调试问题解决
keil只有在程序能正常运行时才能添加断点后在点击调试任务时,断点标记不消失
- Spring Boot 异步运用
使用@Async标签 导入包 org.springframework.scheduling.annotation.Async 并配置并发线程池asyncTaskConfig 实现AsyncConfig ...
- xcfe桌面快捷键整理
转载自:https://my.oschina.net/u/565351/blog/502018 commands custom <Alt>F1:xfce4-popup-applicatio ...
- Knowledge From Practice(JavaScript)
1.HTML事件对象 onmouseover:鼠标移入事件 onmouseout:鼠标移出事件 onmousedown:鼠标落下事件 onmouseup:鼠标抬起事件 例子: onclick:鼠标点击 ...
- python 解方程
[怪毛匠子=整理] SymPy 库 安装 sudo pip install sympy x = Symbol('x') 解方程 solve([2 * x - y - 3, 3 * x + y - 7] ...
- ios 视图既显示阴影又有圆角实现
//- (UIView *)createTimeBG //{ // UIView *view = [[UIView alloc]init]; // view.backgroundColor ...
- vue中的$route和$router的区别
1. $route是一个对象 可以获取当前页面的路由的路径query.params.meta等参数: 2.$router是VueRouter的一个实例对象 在options中可以获取路由的routes ...