爬虫之Scrapy框架介绍
Scrapy介绍
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图
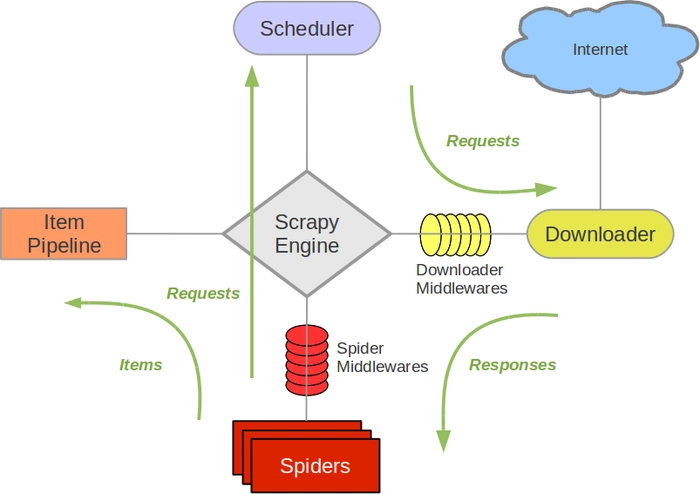
Scrapy Engine(引擎): 用来处理整个系统的数据流处理, 触发事务(框架核心)
Scheduler(调度器): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
Item Pipeline(管道):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
Downloader Middlewares(下载中间件):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
Spider Middlewares(调度中间件):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程
- 首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
- 然后,爬虫解析Response
- 若是解析出实体(Item),则交给实体管道进行进一步的处理。
- 若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
安装
Linux安装:
pip3 install scrapy
Windows安装:
# 1. pip3 install wheel # 2. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted # 3. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl # 4. pip3 install pywin32 # 5. pip3 install scrapy
命令行工具
# 1 查看帮助
scrapy -h
scrapy <command> -h # 2 有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
edit #编辑器,一般不用
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
bench #scrapy bentch压力测试
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs...
目录结构
project_name/
scrapy.cfg # 项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
project_name/
__init__.py
items.py # 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines.py # 项目管道文件,如:一般结构化的数据持久化
settings.py # 配置文件,如:递归的层数、并发数,延迟下载等。
spiders/ # 爬虫目录,如:创建文件,编写爬虫规则
__init__.py
爬虫1.py
爬虫2.py
爬虫3.py
注意:
1. 一般创建爬虫文件时,以网站域名命名
2. 默认只能在终端执行命令,为了更便捷操作:
如果想在pycharm中执行需要做:
#在项目目录下新建:entrypoint.py
from scrapy.cmdline import execute
# execute(['scrapy', 'crawl', 'amazon','--nolog']) #不要日志打印
# execute(['scrapy', 'crawl', 'amazon']) #我们可能需要在命令行为爬虫程序传递参数,就用下面这样的命令
#acrapy crawl amzaon -a keyword=iphone8
execute(['scrapy', 'crawl', 'amazon1','-a','keyword=iphone8','--nolog']) #不要日志打印 # execute(['scrapy', 'crawl', 'amazon1'])
项目实战
scrapy startproject Qiubai # 创建项目 cd Qiubai # 进入项目目录 scrapy genspider qiubai www.qiushibaike.com # 应用名称 爬取网页的起始url
2 编写爬虫文件:在步骤2执行完毕后,会在项目的spiders中生成一个应用名的py爬虫文件,文件源码如下:
import scrapy class QiubaiSpider(scrapy.Spider):
name = 'qiubai' # 应用名称
# 允许爬取的域名(如果遇到非该域名的url则爬取不到数据)
allowed_domains = ['https://www.qiushibaike.com/']
start_urls = ['https://www.qiushibaike.com/'] # 起始爬取的url def parse(self, response):
# xpath为response中的方法,可以将xpath表达式直接作用于该函数中
odiv = response.xpath('//div[@id="content-left"]/div')
content_list = [] # 用于存储解析到的数据
for div in odiv:
# xpath函数返回的为列表,列表中存放的数据为Selector类型的数据。我们解析到的内容被封装在了Selector对象中,需要调用extract()函数将解析的内容从Selecor中取出。
author = div.xpath('.//div[@class="author clearfix"]/a/h2/text()')[0].extract()
content=div.xpath('.//div[@class="content"]/span/text()')[0].extract() # 将解析到的内容封装到字典中
dic={
'作者':author,
'内容':content
}
# 将数据存储到content_list这个列表中
content_list.append(dic) return content_list
3 设置修改settings.py配置文件相关配置,修改内容及其结果如下:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' #伪装请求载体身份 ROBOTSTXT_OBEY = False # 可以忽略或者不遵守robots协议
4 执行爬虫程序:
scrapy crawl 爬虫名称 # 该种执行形式会显示执行的日志信息
scrapy crawl 爬虫名称 --nolog # 该种执行形式不会显示执行的日志信息
最后
今天是情人节,祝大家情人节快乐
有对象的已经去跟对象去约会了,爱学习的才会跟代码相伴(比如我)
送大家一段 python 的情人节代码吧:
print("\n".join([''.join([('Love'[(x-y) % len('Love')] if ((x*0.05)**2+(y*0.1)**2-1)**3-(x*0.05)**2*(y*0.1)**3 <= 0 else ' ') for x in range(-30, 30)]) for y in range(30, -30, -1)]))
好奇的去copy运行一下吧~
爬虫之Scrapy框架介绍的更多相关文章
- 爬虫之Scrapy框架介绍及基础用法
今日内容概要 爬虫框架之Scrapy 利用该框架爬取博客园 并发编程 今日内容详细 爬虫框架Scrapy 1.什么是框架? 框架类似于房子的结构,框架会提前帮你创建好所有的文件和内部环境 你只需要往对 ...
- python爬虫之scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- 爬虫相关-scrapy框架介绍
性能相关-进程.线程.协程 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. 串行执行 import requests def fetc ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- Python学习---爬虫学习[scrapy框架初识]
Scrapy Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能. Scrapy是一个为了爬取网站数据,提取结构性数据而编写的 ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- Python 爬虫之Scrapy框架
Scrapy框架架构 Scrapy框架介绍: 写一个爬虫,需要做很多的事情.比如:发送网络请求.数据解析.数据存储.反反爬虫机制(更换ip代理.设置请求头等).异步请求等.这些工作如果每次都要自己从零 ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
随机推荐
- 当我们按下电源键,Android 究竟做了些什么?
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由goo发表于云+社区专栏 相信我们对Android系统都不陌生,而Android系统博大精深,被各种各样的智能设备承载的同时,我们会否 ...
- dotnet core 入门命令
官方资料: https://docs.microsoft.com/zh-cn/dotnet/core/tools/dotnet-restore?tabs=netcore2x 常规 项目引用 NuGet ...
- jsp 简单下载
<%@ page language="java" import="java.util.*" contentType="text/html;cha ...
- 新数据革命: 开源C#图形化爬虫引擎Hawk5发布
https://ferventdesert.github.io/Hawk/ Hawk是一款由沙漠之鹰历时五年个人业余时间开发的,开源图形化爬虫和数据清洗工具,GitHub Star超过2k+,前几代版 ...
- PHP程序员从小白到高手,掌握这些技能少走弯路
PHP程序员从小白到高手,掌握这些技能少走弯路 PHP究竟是不是最好的语言,一直以来是程序员最大的“争议”,但毋庸置疑的是,PHP绝对是最有前途和力量的变成语言,也是你入门最值得学习的语言. 作为老牌 ...
- web框架开发-Django的Forms组件
校验字段功能 针对一个实例:用户注册. 模型:models.py class UserInfo(models.Model): name=models.CharField(max_length=32) ...
- Editplus5.0 注册码
EditPlus5.0注册码 注册名 Vovan 注册码 3AG46-JJ48E-CEACC-8E6EW-ECUAW EditPlus3.x注册码 注册名 linzhihui 注册码 5A2B6-69 ...
- 使用springMVC时的web.xml配置文件
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" " ...
- C++ cmake
cmake_minimum_required(VERSION 2.8) project(helloworld) option add_exectuable 告诉工程生成一个可执行文件. add_lib ...
- python小白——进阶之路——day2天-———变量的缓存机制+自动类型转换
# ###同一文件,变量的缓存机制 ''' -->Number 部分 1.对于整型而言,-5~正无穷范围内的相同值 id一致 2.对于浮点数而言,非负数范围内的相同值 id一致 3.布尔值而言, ...