第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
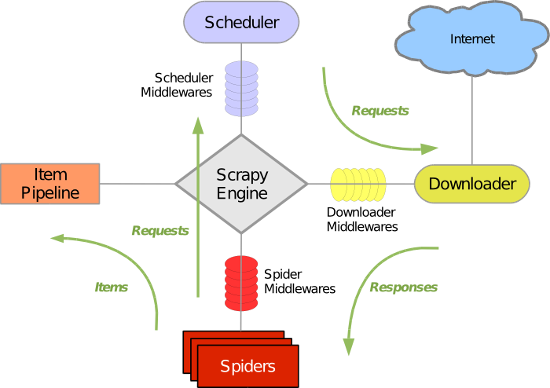
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
创建Scrapy框架项目
Scrapy框架项目是有python安装目录里的Scripts文件夹里scrapy.exe文件创建的,所以python安装目录下的Scripts文件夹要配置到系统环境变量里,才能运行命令生成项目
创建项目
首先运行cmd终端,然后cd 进入要创建项目的目录,如:cd H:\py\14
进入要创建项目的目录后执行命令 scrapy startproject 项目名称
scrapy startproject pach1
项目创建成功
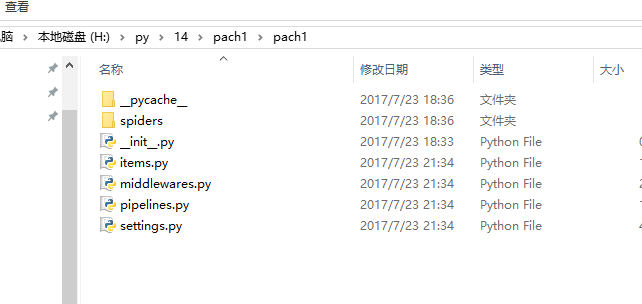
项目说明
目录结构如下:
├── firstCrawler
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
scrapy.cfg: 项目的配置文件tems.py: 项目中的item文件,用来定义解析对象对应的属性或字段。pipelines.py: 负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库)settings.py: 项目的设置文件.- spiders:实现自定义爬虫的目录
- middlewares.py:Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。

创建第一个爬虫
创建爬虫文件在spiders文件夹里创建
1、创建一个类必须继承scrapy.Spider类,类名称自定义
类里的属性和方法:
name属性,设置爬虫名称
allowed_domains属性,设置爬取的域名,不带http
start_urls属性,设置爬取的URL,带http
parse()方法,爬取页面后的回调方法,response参数是一个对象,封装了所有的爬取信息
response对象的方法和属性
response.url获取抓取的rul
response.body获取网页内容字节类型
response.body_as_unicode()获取网站内容字符串类型
# -*- coding: utf-8 -*-
import scrapy class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/'] def parse(self, response):
current_url = response.url #获取抓取的rul
body = response.body #获取网页内容字节类型
unicode_body = response.body_as_unicode() #获取网站内容字符串类型
print(unicode_body)
爬虫写好后执行爬虫,cd到爬虫目录里执行scrapy crawl adc --nolog命令,说明:scrapy crawl adc(adc表示爬虫名称) --nolog(--nolog表示不显示日志)
也可以在PyCharm执行命令

第三百二十四节,web爬虫,scrapy模块介绍与使用的更多相关文章
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册
第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册 基于类的路由映射 from django.conf.urls import url, incl ...
- 第三百七十四节,Django+Xadmin打造上线标准的在线教育平台—创建课程app,在models.py文件生成4张表,课程表、课程章节表、课程视频表、课程资源表
第三百七十四节,Django+Xadmin打造上线标准的在线教育平台—创建课程app,在models.py文件生成4张表,课程表.课程章节表.课程视频表.课程资源表 创建名称为app_courses的 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection) Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数 ...
随机推荐
- Flink 中的kafka何时commit?
https://ci.apache.org/projects/flink/flink-docs-release-1.6/internals/stream_checkpointing.html @Ove ...
- .NET Core 中读取appsettings.json配置文件的方法
appsettings.json配置文件结构如下: { "WeChatPay": { "WeChatApp_ID": "wx9999998999&qu ...
- javascript基础拾遗(十二)
1.javascript的单线程特性 在javascript中,所有的代码都是单线程的 因此所有的网络操作,浏览器事件,都必须是异步执行的,异步执行的逻辑是回调. function callback( ...
- 【Java】Java日志框架Logback的简单例子
常用的日志框架 SLF4J,全称Simple Logging Facade for Java,即Java简单日志外观框架,顾名思义,它并非具体的日志实现,而是日志外观框架 java.util.logg ...
- webpack配置提取公共代码
公共代码提取功能是针对多入口文件的: 背景:在pageA.js和pageB.js中分别引用subPageA.js和subPageB.js webpack.config.js文件: var path = ...
- Android.mk用法整理
[时间:2016-05] [状态:Open] 输出消息 由于Android.mk使用的GNU Make的语法,可以方便的使用.ndk提供了一下三种格式的消息输出: error: debug print ...
- jetty debug 启动 jettyconfig配置文件
jetty 代码启动 debug很简单 run----->>>debug as 代码启动配置文件 start 方法 @Test public void serverStrart( ...
- python rabittmq 使用
Reference: https://www.rabbitmq.com/tutorials/tutorial-three-python.html 1 "Hello World!" ...
- 好用的vim插件
# 好用的vim插件 ### 简介------------------------------ 记录vim好用的插件 ### vimcdoc vim中文帮助文档-------------------- ...
- Android开发(四)——Android中的颜色
Android开发中关于资源文件的存储操作.对于Android资源也是非常重要的,主要包括文本字符串(strings).颜色(colors).数组(arrays).动画(anim).布局(layout ...