<scrapy爬虫>爬取猫眼电影top100详细信息
1.创建scrapy项目
dos窗口输入:
scrapy startproject maoyan
cd maoyan
2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义)
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
#影片中文名称/英文名称
ztitle = scrapy.Field()
etitle = scrapy.Field()
#影片类型
type = scrapy.Field()
#导演
dname = scrapy.Field()
#主演
star = scrapy.Field()
#上映时间
releasetime = scrapy.Field()
#影片时间
time = scrapy.Field()
# 评分
score = scrapy.Field()
#图片链接
image = scrapy.Field()
#详情信息
info = scrapy.Field()
3.创建爬虫文件
dos窗口输入:
scrapy genspider -t crawl myspider maoyan.com
4.编写myspider.py文件(接收响应,处理数据)
# -*- coding: utf-8 -*-
import scrapy
#导入链接规则匹配
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
#导入模板
from maoyan.items import MaoyanItem class MaoyanSpider(CrawlSpider):
name = 'myspider'
allowed_domains = ['maoyan.com']
start_urls = ['https://maoyan.com/board/4?offset=0'] rules = (
Rule(LinkExtractor(allow=r'offset=\d+'),follow=True),
Rule(LinkExtractor(allow=r'/films/\d+'),callback='parse_maoyan',follow=False),
) def parse_maoyan(self, response):
item = MaoyanItem()
# 影片中文名称/英文名称
item['ztitle'] = response.xpath('//h3/text()').extract()[0]
item['etitle'] = response.xpath('//div[@class="ename ellipsis"]/text()').extract()[0]
# 影片类型
item['type'] = response.xpath('//li[@class="ellipsis"][1]/text()').extract()[0]
# 导演
item['dname'] = response.xpath('//a[@class="name"]/text()').extract()[0].strip()
# 主演
star_1 = response.xpath('//li[@class="celebrity actor"][1]//a[@class="name"]/text()').extract()[0].strip()
star_2 = response.xpath('//li[@class="celebrity actor"][2]//a[@class="name"]/text()').extract()[0].strip()
star_3 = response.xpath('//li[@class="celebrity actor"][3]//a[@class="name"]/text()').extract()[0].strip()
item['star'] = star_1 + "\\" + star_2 + '\\' +star_3
# 上映时间
item['releasetime'] = response.xpath('//li[@class="ellipsis"][3]/text()').extract()[0]
# 影片时间
item['time'] = response.xpath('//li[@class="ellipsis"][2]/text()').extract()[0].strip()[-5:]
# 评分,没抓到
# item['score'] = response.xpath('//span[@class="stonefont"]/text()').extract()[0]
item['score'] = "None"
# 图片链接
item['image'] = response.xpath('//img[@class="avatar"]/@src').extract()[0]
# 详情信息
item['info'] = response.xpath('//span[@class="dra"]/text()').extract()[0].strip() yield item
5.编写pipelines.py(存储数据)
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json class MaoyanPipeline(object):
def __init__(self):
self.filename = open('maoyan.txt','wb') def process_item(self, item, spider):
text = json.dumps(dict(item),ensure_ascii=False) + '\n'
self.filename.write(text.encode('utf-8'))
return item def close_spider(self,spider):
self.filename.close()
6.编写settings.py(设置headers,pipelines等)
robox协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
headers
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
pipelines
ITEM_PIPELINES = {
'maoyan.pipelines.MaoyanPipeline': 300,
}
7.运行爬虫
dos窗口输入:
scrapy crawl myspider
运行结果:
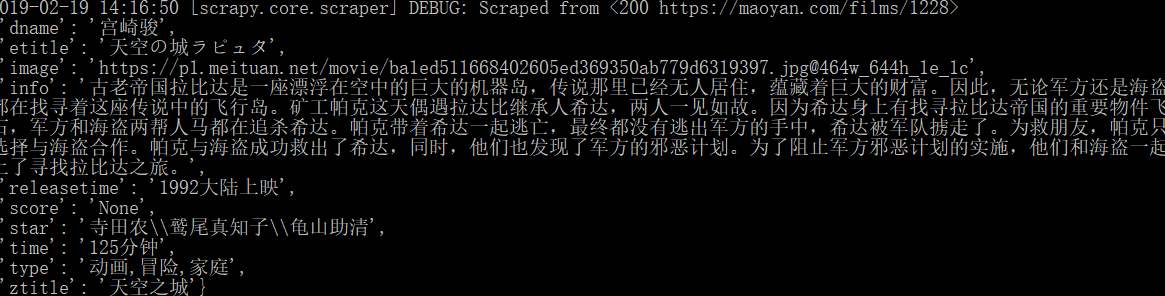
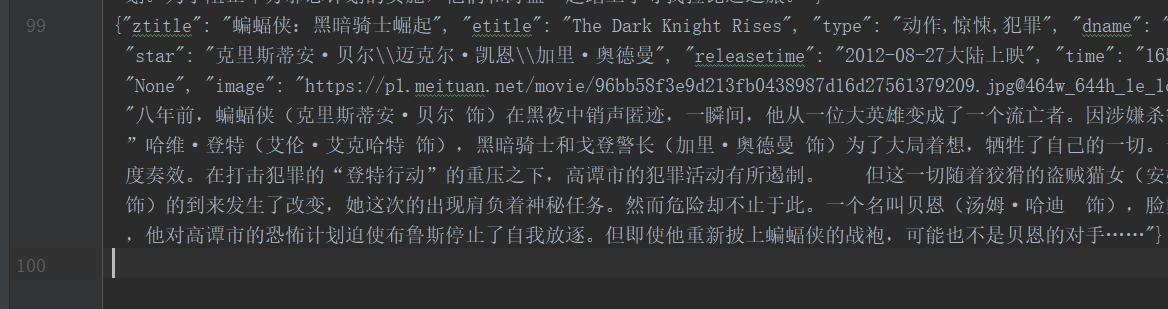
emmmm,top100只爬到99个,
问题:

源码里面评分是□.□!!!全是套路,外面可以找到这个评分,懒得折腾了
单独爬取zname是100个,可能是哪个属性的xpath匹配,网页详情页没有,实现功能就行了
爬取成功
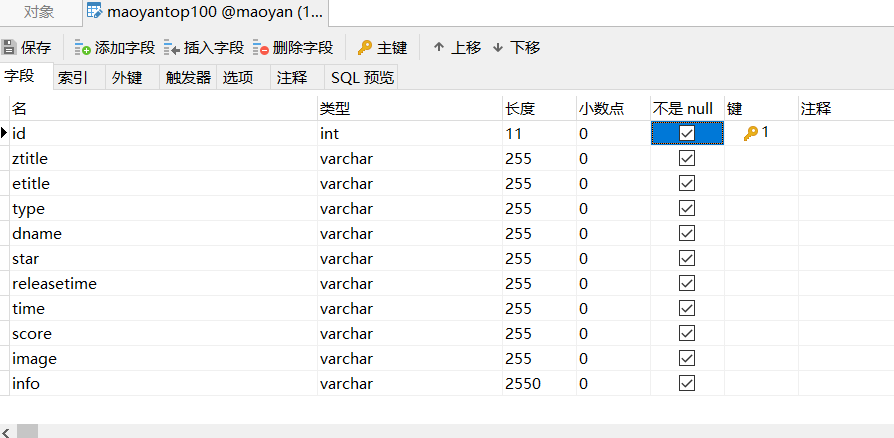
8.存储到mysql数据库
在mysql数据库建立相应的数据库和表:
改写一下pipelines.py文件即可:
import pymysql.cursors class MaoyanPipeline(object):
def __init__(self):
#连接数据库
self.connect = pymysql.connect(
host = 'localhost',
user = 'root',
password = '',
database = 'maoyan',
charset = 'utf8' # 别写成utf-8
)
self.cursor = self.connect.cursor() # 建立游标 def process_item(self, item, spider):
item = dict(item)
sql = "insert into maoyantop100(ztitle,etitle,type,dname,star,releasetime,time,score,image,info) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(item['ztitle'],item['etitle'],item['type'],item['dname'],item['star'],item['releasetime'],item['time'],item['score'],item['image'],item['info'],))
self.connect.commit()
return item def close_spider(self,spider):
self.cursor.close()
self.connect.close()
运行:

存储成功:
<scrapy爬虫>爬取猫眼电影top100详细信息的更多相关文章
- python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests.BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名.图片.名称.演 ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- # 爬虫连载系列(1)--爬取猫眼电影Top100
前言 学习python有一段时间了,之前一直忙于学习数据分析,耽搁了原本计划的博客更新.趁着这段空闲时间,打算开始更新一个爬虫系列.内容大致包括:使用正则表达式.xpath.BeautifulSoup ...
随机推荐
- mysql 触发器实现级联删除有外键的多张表
2019-10-12 10:17:44 1.数据,建表时有可能会报错,只需要把前三行注释删掉就行 -- ---------------------------- -- Table structure ...
- nodejs . module.exports
//utils.js let a = 100; console.log(module.exports); //能打印出结果为:{} console.log(exports); //能打印出结果为:{} ...
- GetOpenFilename的基本用法
GetOpenFilename '一.概述基本语法 Application.GetOpenFilename 方法 显示标准的“打开”对话框,并获取用户文件名,而不必真正打开任何文件,只是把打开文件名称 ...
- Android开发 navigation的跳转动画实现
前言 此篇博客只简短的介绍navigation如何添加跳转页面的动画属性,如果你还为接触了解过navigation.建议你看我另一篇博客Android开发 navigation入门详解 创建动画xml ...
- SQL Server - Store procedure 如何返回值
存储过程 返回值 procedure return values : http://www.cnblogs.com/SunnyZhu/p/5542347.html return.select.outp ...
- 单调栈——cf777E
傻逼单调栈啊我怎么想了半天dp #include <bits/stdc++.h> using namespace std; typedef long long LL; typedef st ...
- 初步了解Redis
参考: https://juejin.im/post/5b4dd82ee51d451925629622?utm_source=gold_browser_extension https://www.cn ...
- 尚学linux课程---10、linux环境下安装python
尚学linux课程---10.linux环境下安装python 一.总结 一句话总结: 直接在官网下载python的源码包即可,然后在linux下安装 linux下安装软件优先想到的的确是yum,但是 ...
- redis 本地连接可以 远程连接不上问题
1.所连主机防火墙关一下. 1:查看防火状态 systemctl status firewalld service status iptables 2:暂时关闭防火墙 systemctl stop ...
- Python 日期和时间_python 当前日期时间_python日期格式化
Python 日期和时间_python 当前日期时间_python日期格式化 Python程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能. Python 提供了一个 time 和 cal ...