spark成长之路(1)spark究竟是什么?
今年6月毕业,来到公司前前后后各种事情折腾下来,8月中旬才入职。本以为终于可以静下心来研究技术了,但是又把我分配到了一个几乎不做技术的解决方案部门,导致现在写代码的时间都几乎没有了,所以只能在每天下班后留在公司研究一下自己喜欢的技术,搞得特别晚才回,身心俱疲。
唉~以前天天写代码时觉得苦逼,现在没得代码写了,反而更累了。。。
言归正传,这次准备利用空余的时间,好好研究下大数据相关的技术,也算是弥补下自己的技术短板吧。这一个系列的文章是我从一个大数据小白开始学习的过程,不知道我究竟能学到哪个程度,也不清楚自己是否会半途而废,但是希望能尽量坚持下去,也希望看到这一系列博客的读者能更我一起努力,一起进步!
首先我们来看一下spark究竟是什么。相信很多读者跟我一样,听说过hadoop,也知道spark,更知道spark是现在最火的大数据技术,所以一直有一个疑问:spark是不是替代能够hadoop的下一代大数据技术?答案是:不是!
首先我们看看spark的官网介绍:Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
再来看看hadoop的官网介绍:The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.注意到,在官网的介绍中,hadoop只包含了4个模块:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
仔细比对就能明白,其实spark只是一个计算框架,它的能力是在现有数据的基础上提供一个高性能的计算引擎,然后提供一些上层的处理工具比如做数据查询的Spark SQL、做机器学习的MLlib等;而hadoop的功能则更加全面,它是包括了数据存储(HDFS)、任务计划和集群资源管理(YARN)以及离线并行计算(MapReduce)的一整套技术栈。因此可以看出,spark其实是依赖于第三方的数据源的,但这也是spark灵活的地方,它能够配合HBase、Hive,以及关系型数据库Oracle、Mysql等多种类型的数据工作。
说到这儿,如果你还没明白spark和hadoop的关系的话,我用一张图告诉你:
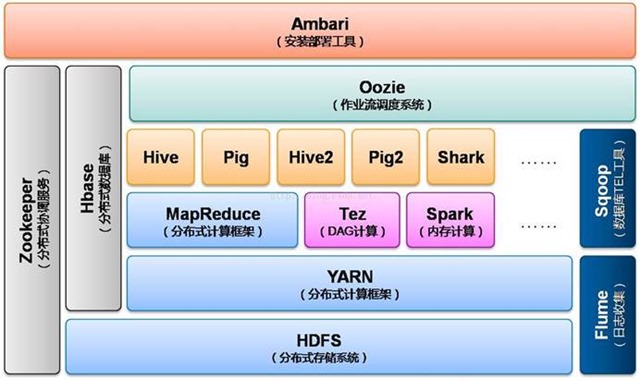
这个是hadoop2.x的生态系统架构图,可以看到人们现在甚至已经把spark纳入到hadoop的生态之中了(虽然这种说法是否妥当还需验证),足以见证:spark仅仅只是一个计算框架,它不能,也没有必要来替代hadoop,它存在最大的价值就是弥补MapReduce计算性能上的不足,提供超越其数倍甚至数十倍的计算能力。因此,我们可以将spark与MapReduce对标起来。
这里补充一个题外内容:hive和hbase的关系,有一个博客我觉得写的很好,于是接取下来自https://blog.csdn.net/zx8167107/article/details/79265537
HIVE:
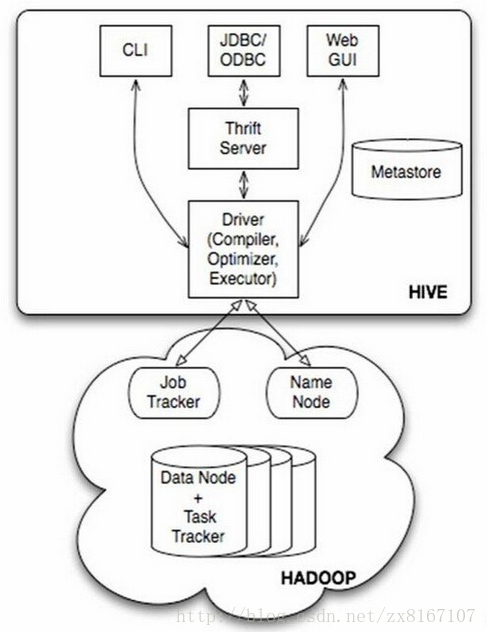
首先说说hive,众所周知是一款开源的数据仓库
1、hive不是数据库,而是数据仓库,主要依赖于hadoop来实现
2、底层文件系统是hadoop的hdfs,实现对hdfs上结构化数据的SQL操作HQL,速度较慢
3、计算引擎是hadoop的mapreduce
4、依靠存储在其他关系型数据库metastore来对hdfs结构化数据进行管理,实现类似数据库的功能
5、不具备数据库的一些主键、索引、update操作等特性,但是提供了分区、块索引、SQL等特性
6、比较适合存储海量的全量(历史+更新)轨迹数据,比对数据进行批量的挖掘、分析等操作
总结一下,hive是基于hadoop实现的数据仓库,适合存储海量全量数据,支持类SQL操作,性能相对较差,数据存储
有一定的限制,不支持更新、索引等事务。适合海量数据的挖掘和分析,通俗一点来说,hive其实就是借助mysql等数据库在
hadoop上层套了一个壳,来实现对hdfs上结构化数据的映射,为上层提供sql服务。
HBASE:
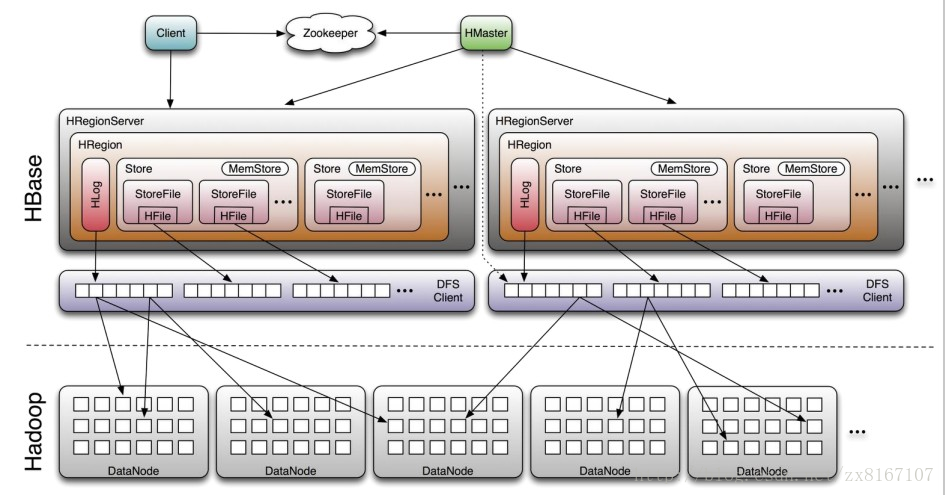
即Hadoop databse,顾名思义就是一个hadoop的数据库
1、nosql数据库之一,基于列式存储(列族),适合海量半结构化数据的存储和检索
2、不支持SQL、适合海量、带时间序列的数据的存储和检索、性能较好
3、原生支持基于rowkey的一级索引,rowkey按照字典序进行排序
4、运算执行引擎是hbase自身提供、底层存储基于hdfs
总结一下,hbase是NOSQL数据库的一种,基于分布式列式存储,适合海量半结构化带时间序列的数据的存储和检索,性能较优秀,hbase底层存储依赖于hdfs,与rdbms的区别与其他nosql类似,比如不支持SQL、事务性相对较差等等。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
综上,hbase是数据库、hive是数据仓库,而这有很大的区别、也有很多类似的地方比如都属于hadoop生态圈、存储都基于hdfs等。一般来说用hive作为海量结构化全量数据的存储、运算、挖掘、分析;hbase用来作为海量半结构化数据的存储、检索;这二者可以很好协同工作,hive上计算完的结果放在hbase中供检索,也可以将hbase里面的结构化数据和hive相结合,实现对hbase的sql操作等等。在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
通过ETL工具将数据源抽取到HDFS存储;
通过Hive清洗、处理和计算原始数据;
HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
数据应用从HBase查询数据;
spark成长之路(1)spark究竟是什么?的更多相关文章
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark进阶之路-Standalone模式搭建
Spark进阶之路-Standalone模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark的集群的准备环境 1>.master节点信息(s101) 2&g ...
- Spark进阶之路-Spark HA配置
Spark进阶之路-Spark HA配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 集群部署完了,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借 ...
- Spark进阶之路-日志服务器的配置
Spark进阶之路-日志服务器的配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如果你还在纠结如果配置Spark独立模式(Standalone)集群,可以参考我之前分享的笔记: ...
- Spark学习之路 (一)Spark初识
目录 一.官网介绍 1.什么是Spark 二.Spark的四大特性 1.高效性 2.易用性 3.通用性 4.兼容性 三.Spark的组成 四.应用场景 正文 回到顶部 一.官网介绍 1.什么是Spar ...
- spark学习之路1--用IDEA编写第一个基于java的程序打包,放standalone集群,client和cluster模式上运行
1,首先确保hadoop和spark已经运行.(如果是基于yarn,hdfs的需要启动hadoop,否则hadoop不需要启动). 2.打开idea,创建maven工程.编辑pom.xml文件.增加d ...
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark学习之路 (七)Spark 运行流程
一.Spark中的基本概念 (1)Application:表示你的应用程序 (2)Driver:表示main()函数,创建SparkContext.由SparkContext负责与ClusterMan ...
随机推荐
- 从SuperSocket的App.config中读取配置,并修改保存,再重启服务
string XmlPath = System.Windows.Forms.Application.ExecutablePath + ".config"; XmlDocument ...
- SQL Server ->> 无法将数据库从SINGLE_USER模式切换回MULTI_USER模式(Error 5064)
报错信息如下: Msg 5064, Level 16, State 1, Line 1Changes to the state or options of database 'test' cannot ...
- myEclipse mybatis自动生成工具xml配置
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE generatorConfiguration ...
- C#中的多线程 - 同步基础 z
原文:http://www.albahari.com/threading/part2.aspx 专题:C#中的多线程 1同步概要Permalink 在第 1 部分:基础知识中,我们描述了如何在线程上启 ...
- C++实现线性表的链接存储结构(单链表)
将线性表的抽象数据类型定义在链接存储结构下用C++的类实现,由于线性表的数据元素类型不确定,所以采用模板机制. 头文件linklist.h #pragma once #include <iost ...
- 跳舞玩偶Doll正式上线
有问题或者建议大家可以联系我的QQ 914287516 或者qq邮箱 官方qq群 325631077:
- Latex 参考文献引用
转:http://blog.sina.com.cn/s/blog_4b164557010143tl.html 导入 \usepackage[option]{natbib} 具体的 option 有 r ...
- angularJS报错$apply already in progress的原因和解决方法
如果我们使用了AngularJS中的$scope.$apply()或者$scope.$digest(),我们很可能会遇到类似下面的错误,虽然这个错误没有太大影响,但是在日志中看起来还是很不爽的,日志中 ...
- perl的一些小函数——split、join、sort
有时候,我们需要将一个字符串或一行文本通过某种方式转换为单个的元素存储在数组中,或者将许多元素通过某种分割符,将他们组合成一个字符串.perl刚好就提供了这样的功能,通过split或者join分割或组 ...
- 第六章.MyBatis缓存结构
一级缓存 测试案例: MyBatisTest.java //缓存 @Test public void testFindCustomerCache1() throws Exception{ SqlSes ...