scrapy抓取拉勾网职位信息(二)——拉勾网页面分析

网站结构分析:
四个大标签:首页、公司、校园、言职
我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进。
首先是四个大标签,鼠标点击进入后可以发现首页、公司、校园,这三个包含有招聘职位
1、首先是对首页的分析
首页正文部分包括:搜索栏(含热门搜索)、职业方向标签(java、php。。。)、热门职位、热门公司
搜索栏:搜索标签的岗位数量较少,我们要做全站数据爬取的话,不跟进这个标签
职业方向标签:这个标签指向的url都是lagou.com/zhaopin/.* (.*代表0个或多个任意字符)这种形式,岗位较全,需要跟进这些页面
热门职位:这个标签指向的url都是lagou.com/jobs/...这种形式,职业方向标签内详情页可能会有重复,同样不跟进
热门公司:这个标签指向的url都是lagou.com/gongsi/\d+这种形式,点进去后可以看到详情页都包含在lagou.com/gongsi/j.*这种链接中,但实际上这个与上方四个大标签的公司标签也是重复的,所以这些页面也不在首页跟进
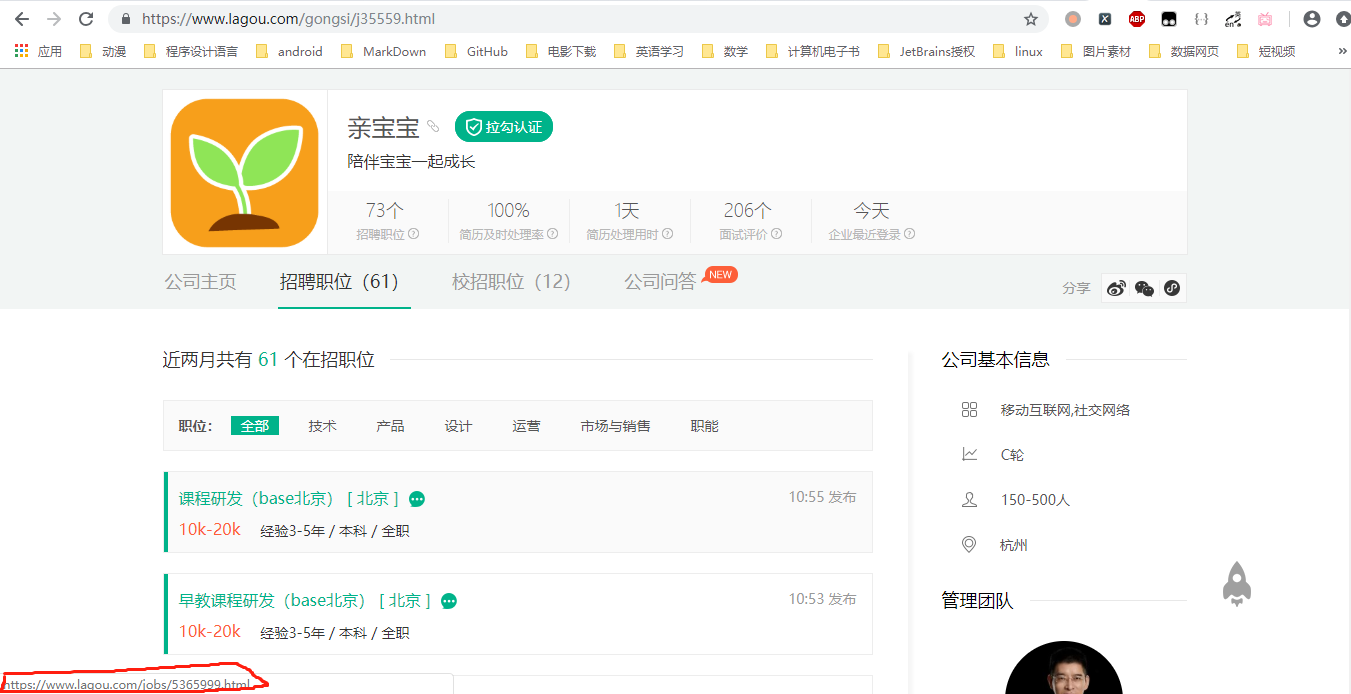
2、对大标签公司的分析
可以看到各个公司标签都包含在lagou.com/gongsi/这个链接下,每一个公司名类似lagou.com/gongsi/\d+.html(\d+代表一个或者多个数字)

进入其中一个公司页面,可以看到所有的招聘职位都在lagou.com/gongsi/j\d+.html这样的页面下(\d+代表一个或者多个数字),而岗位详情页类似lagou.com/jobs/\d+.html
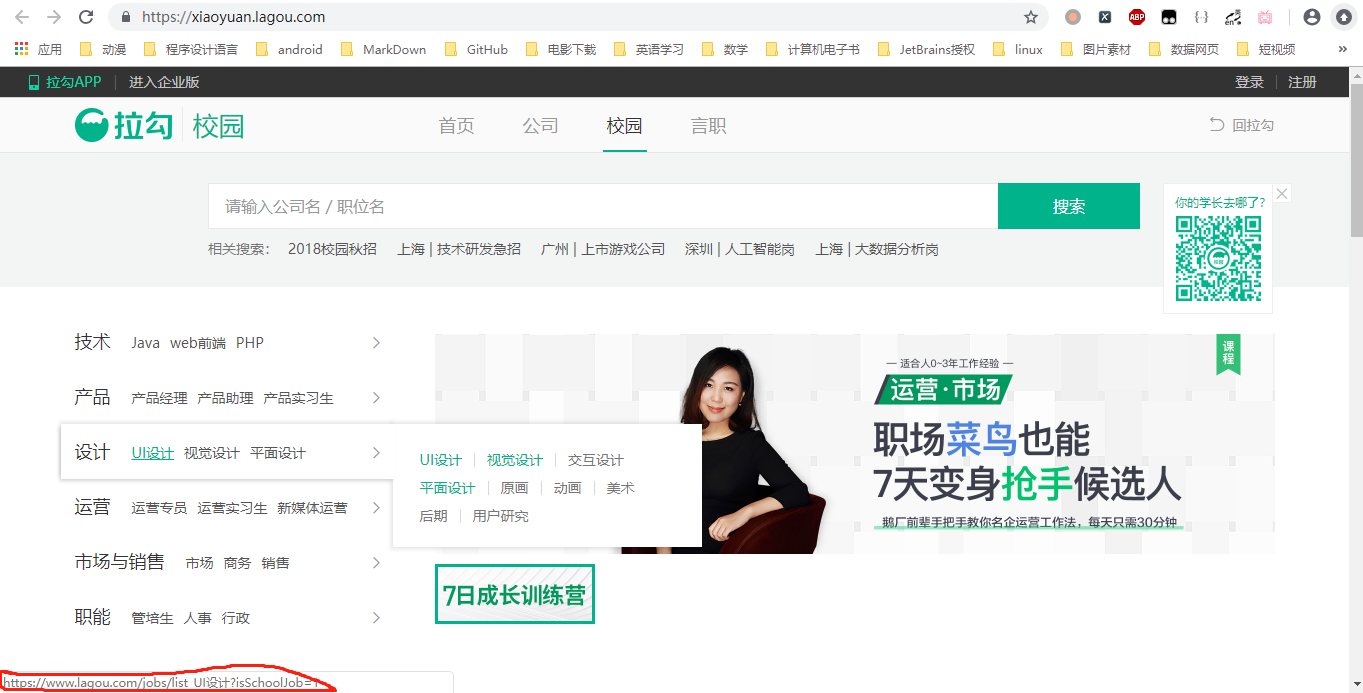
3、大标签校园的分析
可以看出来,这个和首页的结构比较类型,那我们就和首页一样,选取职业方向标签的url作为跟进的目标,可以看出每一个标签都是类似lagou.com/jobs/list_.* (.*代表0个或多个任意字符)
通过以上分析,我们就知道对于拉勾网来说,要想做到全站抓取,需要跟进哪些链接。
scrapy抓取拉勾网职位信息(二)——拉勾网页面分析的更多相关文章
- 抓取某东的TT购买记录分析TT购买趋势
最近学习了一些爬虫技术,想做个小项目检验下自己的学习成果,在逛某东的时候,突然给我推荐一个TT的产品,点击进去浏览一番之后就产生了抓取TT产品,然后进行数据分析,看下那个品牌的TT卖得最好. 本文通过 ...
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- scrapy抓取斗鱼APP主播信息
如何进行APP抓包 首先确保手机和电脑连接的是同一个局域网(通过路由器转发的网络,校园网好像还有些问题). 1.安装抓包工具Fiddler,并进行配置 Tools>>options> ...
- Java广度优先爬虫示例(抓取复旦新闻信息)
一.使用的技术 这个爬虫是近半个月前学习爬虫技术的一个小例子,比较简单,怕时间久了会忘,这里简单总结一下.主要用到的外部Jar包有HttpClient4.3.4,HtmlParser2.1,使用的开发 ...
- 通过Scrapy抓取QQ空间
毕业设计题目就是用Scrapy抓取QQ空间的数据,最近毕业设计弄完了,来总结以下: 首先是模拟登录的问题: 由于Tencent对模拟登录比较讨厌,各个防备,而本人能力有限,所以做的最简单的,手动登录后 ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- scrapy抓取淘宝女郎
scrapy抓取淘宝女郎 准备工作 首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找 ...
- Scrapy抓取Quotes to Scrape
# 爬虫主程序quotes.py # -*- coding: utf-8 -*- import scrapy from quotetutorial.items import QuoteItem # 启 ...
- 分布式爬虫:使用Scrapy抓取数据
分布式爬虫:使用Scrapy抓取数据 Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘. ...
随机推荐
- POJ 2823 Sliding Window ST RMQ
Description An array of size n ≤ 106 is given to you. There is a sliding window of size k which is m ...
- Android程序始终横屏
在AndroidManifest.xml文件里面的activity标签中加入以下属性 android:screenOrientation="landscape" android:c ...
- [Luogu 2590] ZJOI2008 树的统计
[Luogu 2590] ZJOI2008 树的统计 裸树剖不解释. 比板子还简单. #include <algorithm> #include <cstdio> #inclu ...
- Freemarker <#list List/Map/Array[] as Object>
http://blog.csdn.net/ani521smile/article/details/52164366 详细教程链接
- 【比赛】洛谷夏令营NOIP模拟赛
Day1 第一题 水题 第二题 题意:一个n*m的字符矩阵从左上到右下,经过字符形成回文串的路径数.n≤500 回文串,考虑两段往中间DP. f[k][x][y]表示走了k步,左上点横坐标为x,右下点 ...
- A Simple Math Problem(矩阵快速幂)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1757 思路:矩阵快速幂模板题,不过因为刚刚入门矩阵快速幂,所以经常把数组f存反,导致本地错误一晚,差点 ...
- Java 中的方法内部类
方法内部类就是内部类定义在外部类的方法中,方法内部类只在该方法的内部可见,即只在该方法内可以使用. 一定要注意哦:由于方法内部类不能在外部类的方法以外的地方使用,因此方法内部类不能使用访问控制符和 s ...
- 多线程伪共享FalseSharing
1. 伪共享产生: 在SMP架构的系统中,每个CPU核心都有自己的cache,当多个线程在不同的核心上,并且某线程修改了在同一个cache line中的数据时,由于cache一致性原则,其他核心cac ...
- linux dpm机制分析(上)【转】
转自:http://blog.csdn.net/lixiaojie1012/article/details/23707681 1 DPM介绍 1.1 Dpm: 设备电源管理, ...
- python之requests库使用问题汇总
一.请求参数类型 1.get requests.get(url, data, cookies=cookies) url:字符串: data:字典类型,可以为空: cookies:字典类型,可以为空: ...