leveldb - sstable格式
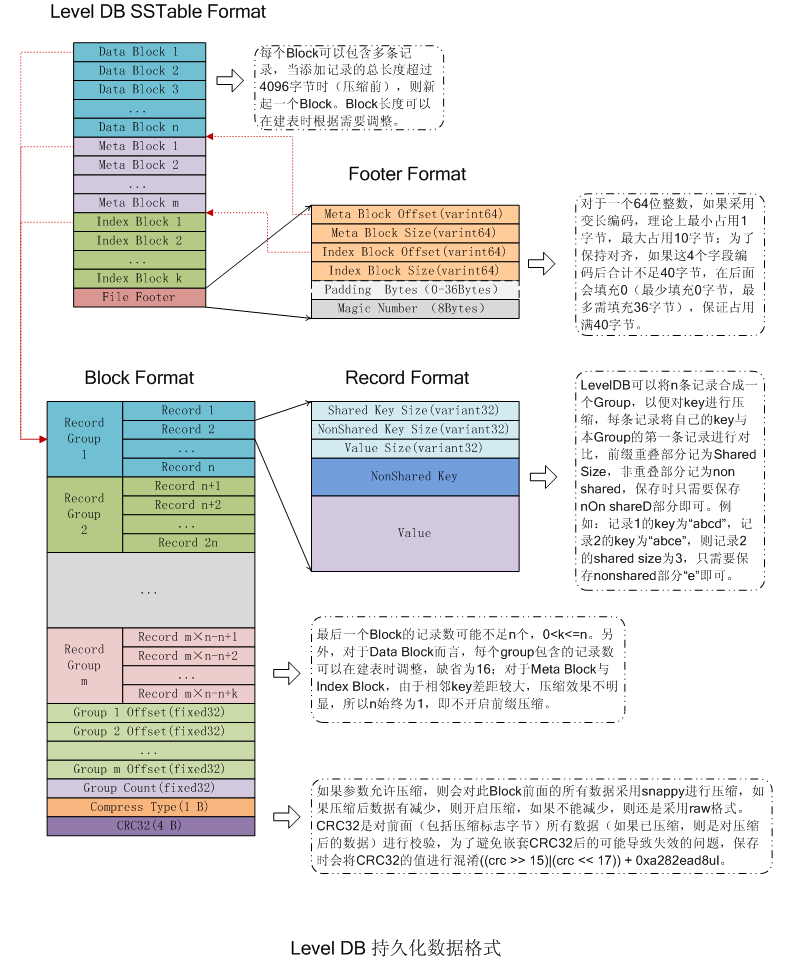
整体上,sstable文件分为数据区与索引区,尾部的footer指出了meta index block与data index block的偏移与大小,data index block指出了各data block的偏移与大小,meta index block指出了各meta block的偏移与大小。
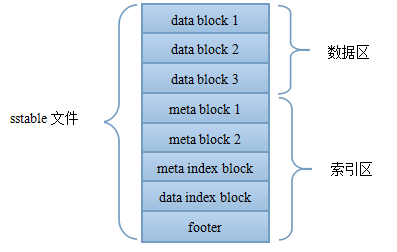
1)DataBlock:存储Key-Value记录,分为Data、type、CRC三部分
2)MetaBlock:暂时没有使用
3)MetaBlock_index:记录filter的相关信息(本文暂时没有考虑filter)
4)IndexBlock:描述一个DataBlock,存储着对应DataBlock的最大Key值,DataBlock在.sst文件中的偏移量和大小
5)Footer :索引的索引,记录IndexBlock和MetaIndexBlock在SSTable中的偏移量了和大小
footer
先看footer结构。如下图。footer位于sstable文件尾部,占用空间固定为48个字节。其末尾8个字节是一个magic_number。metaindex_handle与index_handle物理上占用了40个字节,但实际上存储可能连32字节都不到。每一个handle的结构BlockHandle如右图,逻辑上分别表示offset+size,在内存中占用16个字节,但存储时由于采用可变长度编码,每个handle的物理存储通常不到8+8字节。因此这里两个handle总共占用不到32个字节,剩余填充0。

leveldb footer + block handle
BlockHandle指出了block的偏移与大小。在sstable文件中,一般有多个data block,多个meta block(当前版本只有一个filter block,可扩充),1个meta index block,1个data index block。其中filter block的内部结构稍微不同于其他Block,但都是用BlockHandle来指向的。
block
逻辑上主要分为数据与重启点。重启点也是一个指针,指出了一些特殊的位置。data block中的key是有序存储的,相邻的key之间可能有重复,因此存储时采用前缀压缩,后一个key只存储与前一个key不同的部分。那些重启点指出的位置就表示该key不按前缀压缩,而是完整存储该key。除了减少压缩空间之外,重启点的第二个作用就是加速读取。如果说data index block可以通过二分来定位具体的block,那么重启点则可以通过二分的方法来定位具体的重启点位置,进一步减少了需要读取的数据。对于leveldb来讲,可以通过options.block_size与options.block_restart_interval来设置block的大小与重启点的间隔。默认data block的大小为4K。而重启点则每隔16个key。具体的单条record的存储格式如下图所示。
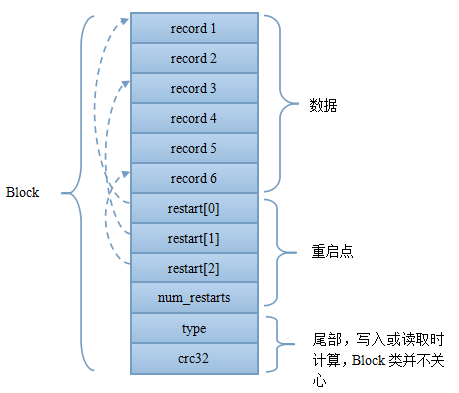
Block格式

Record 格式
data index block
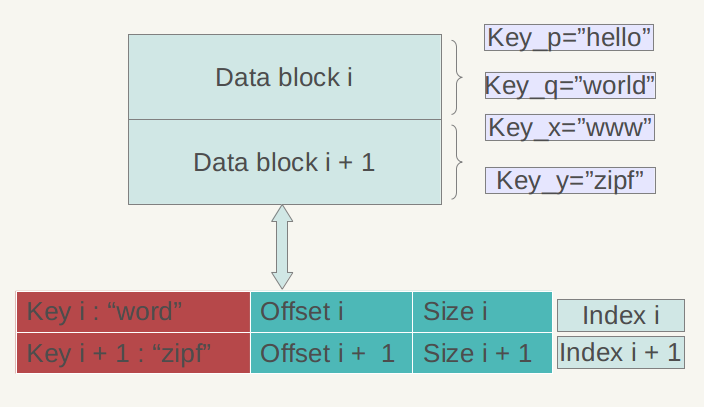
Index Block的结构与Data Block一样,只不过每个group只包含一条记录,即Data Block的最大Key与偏移。其实这里说最大Key并不是很准确,理论上,只要保存最大Key就可以实现二分查找,但是Level DB在这里做了个优化,它并保存最大key,而是保存一个能分隔两个Data Block的最短Key,如:假定Data Block1的最后一个Key为“abcdefg”,Data Block2的第一个Key为“abzxcv”,则index可以记录Data Block1的索引key为“abd”;这样的分割串可以有很多,只要保证Data Block1中的所有Key都小于等于此索引,Data Block2中的所有Key都大于此索引即可。这种优化缩减了索引长度,查询时可以有效减小比较次数。
data block与meta index block、data index block都是采用block来存储的(filter block稍微不同)。而对于block来讲,其都是按(key,value)格式存储一条条的record的。对于这些不同类型的block,其(key,value)都是什么了?总结如下图。现在只有一个meta block用于filter,因此meta index block中也只有一条记录,其key是filter. + filter_policy的name。
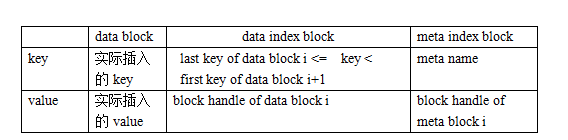
不同block的key, value
sstable格式
leveldb - sstable格式的更多相关文章
- LevelDB SSTable文件
[LevelDB SSTable文件] LevelDb不同层级有很多SSTable文件(以后缀.sst为特征),所有.sst文件内部布局都是一样的.上节介绍Log文件是物理分块的,SSTable也一样 ...
- leveldb 学习记录(五)SSTable格式介绍
本节主要记录SSTable的结构 为下一步代码阅读打好基础,考虑到已经有大量优秀博客解析透彻 就不再编写了 这里推荐 https://blog.csdn.net/tankles/article/det ...
- leveldb - log格式
log文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据.因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及D ...
- sstable, bigtable,leveldb,cassandra,hbase的lsm基础
先看懂文献1和2 1. 先了解sstable.SSTable: Sorted String Table [2] [10] WiscKey: 类似myisam, key value分离, 根据ssd优 ...
- caffe神经网络框架的辅助工具(将图片转换为leveldb格式)
caffe中负责整个网络输入的datalayer是从leveldb里读取数据的,是一个google实现的很高效的kv数据库. 因此我们训练网络必须先把数据转成leveldb的格式. 这里我实现的是把一 ...
- LevelDB/Rocksdb 特性分析
LevelDb是Google开源的嵌入式持久化KV 单机存储引擎.采用LSM(Log Structured Merge)tree的形式组织持久化存储的文件sstable.LSM会造成写放大.读放大的问 ...
- LevelDB,你好~
LevelDB,你好~ 上篇文章初识:LevelDB介绍了啥是LevelDB,LevelDB有啥特性,以及Linux环境下编译,使用及调试方法. 这篇文章的话,算是LevelDB源码学习的开端吧,主要 ...
- 【caffe-windows】 caffe-master 之 训练自己数据集(图片转换成lmdb or leveldb)
前期准备: 文件夹train:此文件夹中按类别分好子文件夹,各子文件夹里存放相应图片 文件夹test:同train,有多少类就有多少个子文件夹 trainlabels.txt : 存的是训练集的标签 ...
- HBase-存储-HFile格式
HBase-存储-HFile格式 实际的存储文件功能是由HFile类实现的,它被专门创建以达到一个目的:有效地存储HBase的数据.它们基于Hadoop的TFile类,并模仿Google的BigTab ...
随机推荐
- 第二章-如何使用github建立一个HelloWorld项目,git的add/commit/push/pull/fetch/clone等基本命令用法。--答题人:杨宇杰
1.配置Git 首先在本地创建ssh 秘钥:在git bash输入: $ ssh-keygen -t rsa -C "your_email@youremail.com" eg:$ ...
- 字符串和json之间的互相转化
在Firefox,chrome,opera,safari,ie9,ie8等高级浏览器直接可以用JSON对象的stringify()和parse()方法. JSON.stringify(obj)将JSO ...
- 利用NVelocity 模版生成文本文件
namespace Common { public class Tools { public string Process(string content, int startIndex, int le ...
- php笔试题(1)--转载
一份不错的php面试题,附答案,有准备换工作的同学可以参考一下.一.基础题1. 写出如下程序的输出结果 <?php $str1 = null; $str2 = false; ...
- java的四种引用,强弱软虚
1.利用软引用和弱引用解决OOM问题:用一个HashMap来保存图片的路径和相应图片对象关联的软引用之间的映射关系,在内存不足时,JVM会自动回收这些缓存图片对象所占用的空间,从而有效地避免了OOM的 ...
- 统计《ASP.Net特供视频教程》总长度
忽然想统计一下我录制过的视频一共多长时间,由于视频文件很多,一共72个,挨个打开进行累加不是程序员应该想起的办法.所以就打算写一个程序来完成这件事,最核心的问题就是“获得一个视频文件的时长”. ffm ...
- 64位Linux安装32位向日葵
查看linux系统版本信息如下,可以看出系统为64位. [root@localhost bin]# uname -aLinux localhost.localdomain 3.10.0-327.3.1 ...
- quartznet笔记
http://sourceforge.net/projects/quartznet/files/quartznet/
- EntityFramework中使用Repository装饰器
铺垫 通常在使用 EntityFramework 时,我们会封装出 IRepository 和 IUnitOfWork 接口,前者负责 CRUD 操作,后者负责数据提交 Commit. public ...
- [ACM_图论] 棋盘问题 (棋盘上放棋子的方案数)
不能同行同列,给定形状和大小的棋盘,求摆放k个棋子的可行方案 Input 2表示是2X2的棋盘,1表示k,#表示可放,点不可放(-1 -1 结束) Output 输出摆放的方案数目C Sample I ...