Elasticsearch系列---分布式架构机制讲解
概要
本篇主要介绍Elasticsearch的数据索引时的分片机制,集群发现机制,primary shard与replica shard是如何分工合作的,如何对集群扩容,以及集群的容错机制。
分片机制
前面基本概念一节中,我们有提到建立索引时,会自动将数据拆分到多个分片(shard)中,默认数量是5,这个就是索引数据分片机制。我们在往Elasticsearch集群插入数据,并没有关心过数据最终落地到哪个shard上,这个过程对客户端来讲是透明的。
document路由原理
document要存储到Elasticsearch中,还要满足后续搜索的需求,路由到分片位置的算法肯定不能是随机的,要不然搜索就没法找了,路由的过程有一个公式:
shard = hash(routing) % number_of_primary_shards
routing值默认是document的ID值,也可以自行指定。先对routing信息求hash值,然后将hash结果对primary_shard的数量求模,比如说primary_shard是5,那么结果肯定落在[0,4]区间内,这个结果值就是该document的分片位置,如示意图所示:
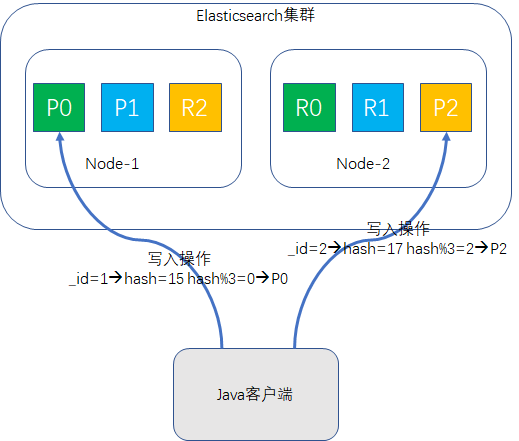
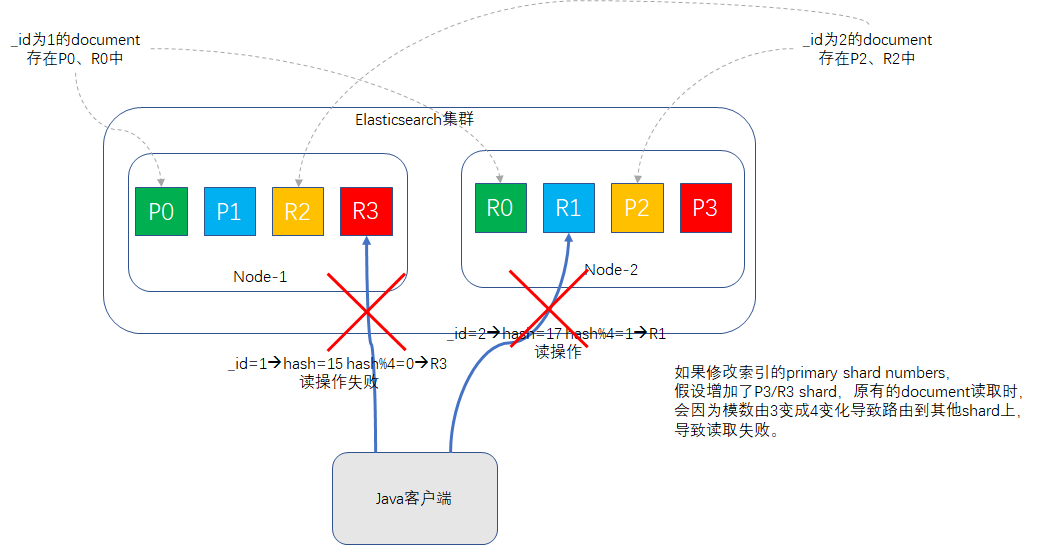
这个求模公式间接的解释了为什么了索引创建时指定了primary shard的值,后续就不让改了,模数改了,之前路由的document再执行该公式时,值就可能跟改之前得到的值不一致,这样document就找不到了,如示意图所示:
集群发现机制
在同一个网络环境下,只要启动一个Elasticsearch实例,并且cluster.name配置得一样,这个Elasticsearch实例就会自动加入到集群当中,这个是如何实现的?
这个依赖于Elasticsearch的自动发现机制Zen,在elasticsearch.yml配置文件中,有一行
discovery.zen.ping.unicast.hosts: ["192.168.17.137"]
表示单播发现方式,当该Elasticsearch实例启动时,会向192.168.17.137主机发送请求,并得到整个集群里所有节点的状态,然后去联系master节点,并加入集群。
摘抄了获取配置信息,注册discovery请求的部分源码如下:
org.elasticsearch.discovery.zen.ZenDiscovery启动时的构造器,会调用org.elasticsearch.discovery.zen.UnicastZenPing的构造器,其中UnicastZenPing的构造方式内会加载discovery.zen.ping.unicast.hosts配置项,并发送"internal:discovery/zen/unicast"请求(代码有删节):
public UnicastZenPing(Settings settings, ThreadPool threadPool, TransportService transportService,
UnicastHostsProvider unicastHostsProvider, PingContextProvider contextProvider) {
super(settings);
final int concurrentConnects = DISCOVERY_ZEN_PING_UNICAST_CONCURRENT_CONNECTS_SETTING.get(settings);
if (DISCOVERY_ZEN_PING_UNICAST_HOSTS_SETTING.exists(settings)) {
configuredHosts = DISCOVERY_ZEN_PING_UNICAST_HOSTS_SETTING.get(settings);
// we only limit to 1 addresses, makes no sense to ping 100 ports
limitPortCounts = LIMIT_FOREIGN_PORTS_COUNT;
} else {
// if unicast hosts are not specified, fill with simple defaults on the local machine
configuredHosts = transportService.getLocalAddresses();
limitPortCounts = LIMIT_LOCAL_PORTS_COUNT;
}
resolveTimeout = DISCOVERY_ZEN_PING_UNICAST_HOSTS_RESOLVE_TIMEOUT.get(settings);
transportService.registerRequestHandler(ACTION_NAME, ThreadPool.Names.SAME, UnicastPingRequest::new,
new UnicastPingRequestHandler());
}
shard&replica规则
一个index的数据,是拆分存储在多个shard当中,我们可以在Elasticsearch的数据目录里查看一下索引的存储结构(Elasticsearch服务器上导出的树状目录结构):
.
└── nodes
└── 0
├── indices
│ ├── 48G_CgE7TiWomlYsyQW1NQ #索引location的UUID
│ │ ├── 0 #primary shard,从0-4共5个
│ │ │ ├── index
│ │ │ │ ├── segments_3
│ │ │ │ └── write.lock
│ │ │ ├── _state
│ │ │ │ └── state-2.st
│ │ │ └── translog
│ │ │ ├── translog-2.ckp
│ │ │ ├── translog-2.tlog
│ │ │ ├── translog-3.ckp
│ │ │ ├── translog-3.tlog
│ │ │ ├── translog-4.tlog
│ │ │ └── translog.ckp
│ │ ├── 1
│ │ │ ├── index
│ │ │ │ ├── segments_3
│ │ │ │ └── write.lock
│ │ │ ├── _state
│ │ │ │ └── state-2.st
│ │ │ └── translog
│ │ │ ├── translog-2.ckp
│ │ │ ├── translog-2.tlog
│ │ │ ├── translog-3.ckp
│ │ │ ├── translog-3.tlog
│ │ │ ├── translog-4.tlog
│ │ │ └── translog.ckp
│ │ ├── 2
│ │ │ ├── index
│ │ │ │ ├── _1.cfe
│ │ │ │ ├── _1.cfs
│ │ │ │ ├── _1.si
│ │ │ │ ├── segments_7
│ │ │ │ └── write.lock
│ │ │ ├── _state
│ │ │ │ └── state-2.st
│ │ │ └── translog
│ │ │ ├── translog-4.ckp
│ │ │ ├── translog-4.tlog
│ │ │ ├── translog-5.ckp
│ │ │ ├── translog-5.tlog
│ │ │ ├── translog-6.tlog
│ │ │ └── translog.ckp
│ │ ├── 3
│ │ │ ├── index
│ │ │ │ ├── _1.cfe
│ │ │ │ ├── _1.cfs
│ │ │ │ ├── _1.si
│ │ │ │ ├── segments_7
│ │ │ │ └── write.lock
│ │ │ ├── _state
│ │ │ │ └── state-2.st
│ │ │ └── translog
│ │ │ ├── translog-4.ckp
│ │ │ ├── translog-4.tlog
│ │ │ ├── translog-5.ckp
│ │ │ ├── translog-5.tlog
│ │ │ ├── translog-6.tlog
│ │ │ └── translog.ckp
│ │ ├── 4
│ │ │ ├── index
│ │ │ │ ├── _0.cfe
│ │ │ │ ├── _0.cfs
│ │ │ │ ├── _0.si
│ │ │ │ ├── segments_5
│ │ │ │ └── write.lock
│ │ │ ├── _state
│ │ │ │ └── state-2.st
│ │ │ └── translog
│ │ │ ├── translog-3.ckp
│ │ │ ├── translog-3.tlog
│ │ │ ├── translog-4.ckp
│ │ │ ├── translog-4.tlog
│ │ │ ├── translog-5.tlog
│ │ │ └── translog.ckp
│ │ └── _state
│ │ └── state-16.st
├── node.lock
└── _state
├── global-88.st
└── node-22.st
如上目录结构所示,展示了location索引(UUID为48G_CgE7TiWomlYsyQW1NQ)的存储信息,共5个primary shard,编号从0-4。
primary shard与replica shard,还有其他几点特性:
- shard是最小的存储单元,像上面的0,1,2目录,承载部分数据。
- document是最小的数据单元,只能存在一个primary shard中以及对应的replica shard中(可能有多个),不会拆分存储,也不会存在于多个primary shard里。
- replica shard是primary shard的数据副本,冗余存储,负责容错,也可以承担查询请求。
- primary shard不会和自己的replica shard放在一台机器上,否则容错机制就失效了,但是可以和别的replica shard混搭。
- primary shard的数量在创建索引的时是多少就多少,后续不能改,但replica shard的数量可以随时修改。
扩容机制
扩容分为垂直扩容和水平扩容两种,垂直扩容指增加单台服务器的CPU、内存大小,磁盘容量,简单来讲就是换更强大的服务器;水平扩容就是增加机器数量,通过集群化部署与分布式的技术手段,也能构建出强大的计算和存储能力。
二者简单对比:
- 垂直扩容:操作简单,无需要更改集群方案,缺点就是贵,成本呈指数上升,并且单台服务器瓶颈很明显。
- 水平扩容:业务经常采用,因为更省钱,可以多非常多的普通服务器搭建,缺点是节点数越多,集群内节点之间通信会出现网络拥塞的问题。
Elastisearch非常适合用水平扩容方案,能胜任上百个节点,支撑PB级别的数据规模,并且扩容操作后,每增加新的节点会触发索引分片的重新分配。
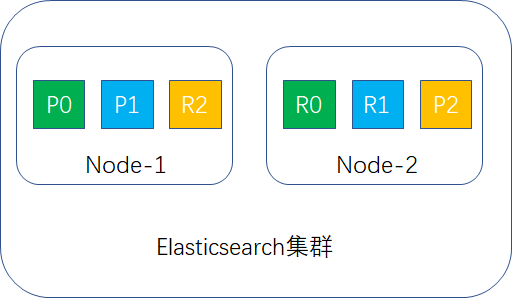
举个例子,假定Elasticsearch有2个节点,primary shard设置为3,replica shard设置为1,这样1个索引就有3个primary shard,3个replica shard,P表示primary shard,R表示replica shard,分布示例图如下:
当新加入一个node-3时,触发node-1和node-2的shard进行重新分配,假定P0和R1两个shard移到node-3当中,如图所示:
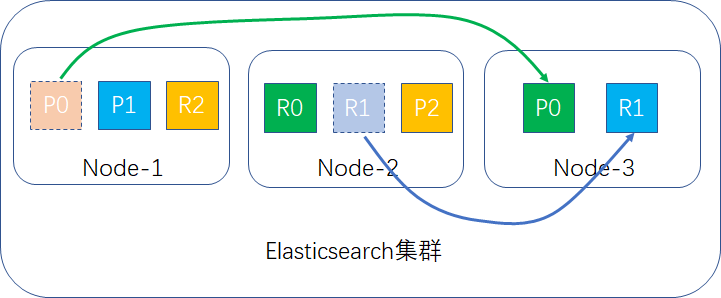
重分配完成后,此时集群的示例如下:
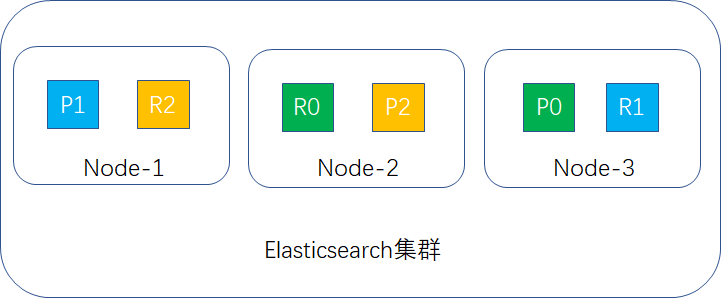
最后补充两点:
- 同一个index的primay shard和replica shard不能在同一个机器上,但不同index的primary shard和replica shard可以混搭。
- 负载均衡也不是完全平均的,有的多有的少,Elasticsearch会根据当前情况自动分配shard。
容错机制
单node环境下的容错
假定Elasticsearch集群只有一个node,primary shard设置为3,replica shard设置为1,这样1个索引就应该有3个primary shard,3个replica shard,但primary shard不能与其replica shard放在一个node里,导致replica shard无法分配,这样集群的status为yellow,示例图如下:
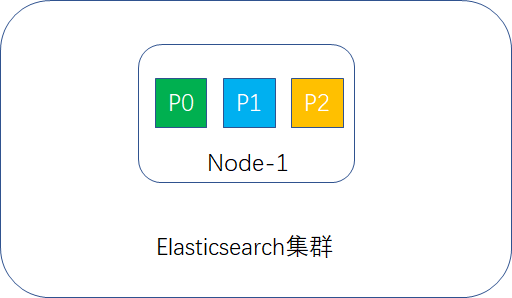
集群可以正常工作,一旦出现node宕机,数据全部丢失,并且集群不可用。
结论:单node环境容错性为0.
2台node环境下的容错
primary shard与replica shard的设置与上文相同,此时Elasticsearch集群只有2个node,shard分布如下图所示:
如果其中一台宕机,如node-2宕机,如图所示:
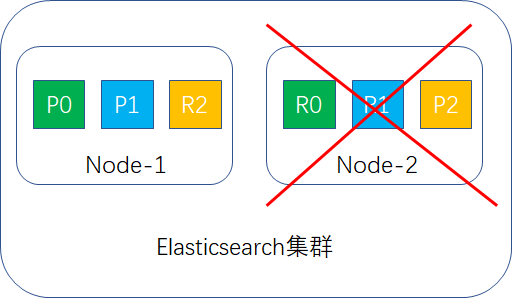
此时node-1节点的R2(replica shard)会升为P2(primary shard),此时集群还能正常用,数据未丢失。
结论:双node环境容错性为1。
3台node环境下的容错
我们先按primary shard为3,replica shard为1进行容错性计算。
此时每台node存放2个shard,如果一台宕机,此时另外2台肯定还有完整的数据,如果两台宕机,剩下的那台就只有2/3的数据,数据丢失1/3,容错性为1台。
如果是这样设置,那3台的容错性和2台的容错性一样,就存在资源浪费的情况。
那怎么样提升容错性呢?
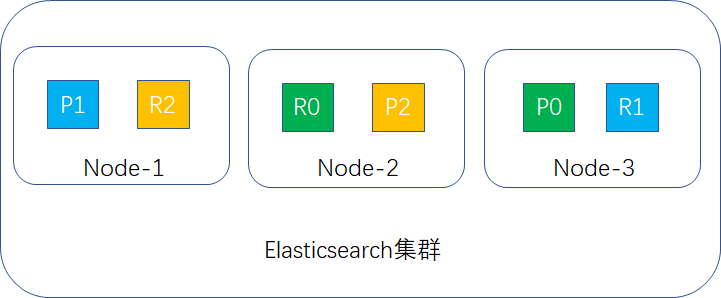
把replica shard的值改成2,这样每台node存放3个shard,如下图所示:
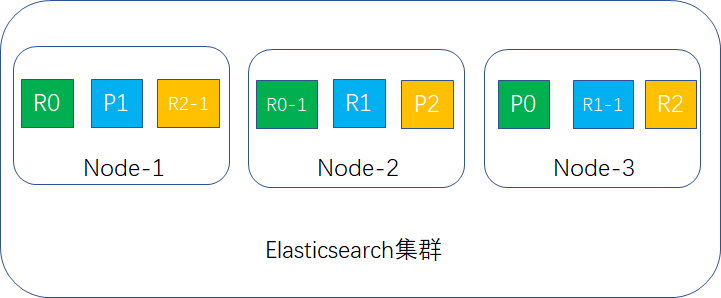
如果有2台宕机,就剩下node-2,此时集群的数据还是完整的,replica会升成primary shard继续提供服务,如下图所示:
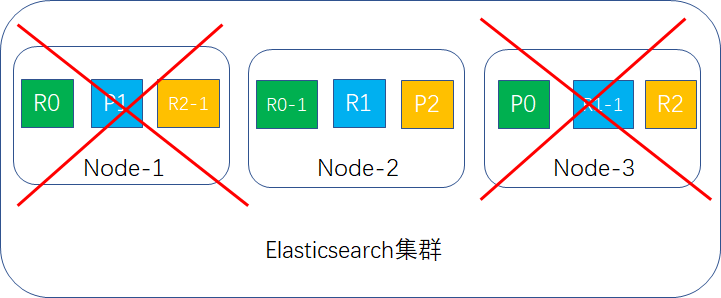
结论:3台node环境容错性最大可以是2。
扩容极限与最佳实践
根据上面3个场景,我们可以知道,如果shard总数是6个(包含primary shard 和replica shard),那么node数量上限也为6,即每台node存储1个shard,这个数据即为扩容极限,如果要突破极限,可以通过增大replica的值来实现,这样有更多的replica shard去分担查询请求,占用更多的节点,整个集群的CPU、IO、Memory资源更多,整体吞吐量也越高。
当然这个replica也不是越大越好,冗余存储占用磁盘资源,replica越大,集群内有效数据的磁盘利用率就越低。以3台node为例,想要达到容错性,磁盘利用率的最佳值,replica=2是最适宜的。
实际生产中,可以根据数据量,并发数等实际需求,在创建索引时合理设置primary shard的数量,后期优化时,再调整replica shard的值,这个需要反复验证,不断的演算调整,最终让生产Elasticsearch集群的吞吐量达到一个最佳值。
容错过程与选举机制
Elasticsearch集群中,所有的node都是对等的角色,所有的node都能接收请求,并且能自动转请求到相应的节点上(数据路由),最后能将其他节点处理的数据进行响应收集,返回给客户端。在集群中,也存在一个master节点,它的职责多一些,需要管理与维护集群的元数据,索引的创建与删除和节点的增加和删除,它都会收到相应的请求,然后进行相应的数据维护。master node在承担索引、搜索请求时,与其他node一起分摊,并不承担所有的请求,因而不存在单点故障这个问题。
我们假设一下集群有3台node,其中node-1宕机的过程,如果node-1是master node,关键步骤如下:
- 丢失了3个shard,由于P1丢失,cluster.status瞬间状态变成red。
- 重新进行master选举,自动选另一个node作为master。
- 新的master将丢失了P1对应的R1(在node-3上面)提升为primary shard ,现全部primary shard active,但是P1,P2的replica shard无法启动,cluster.status变成yellow。
- 重启故障的node-1节点,新的master会将缺失的副本都copy一份到node-1上,node-1会使用之间已有的数据,并且同步一下宕机期间的数据修改,此时所有的shard全部active状态,cluster.status重新变成green。
小结
本篇针对Elasticsearch的一些内部原理进行了简单的介绍,这些原理针对Elasticsearch的使用者是透明的,为了增加可阅读性,自行增加一些讲解的原理图,若有不详尽之处或错误之处请指正,谢谢。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区

Elasticsearch系列---分布式架构机制讲解的更多相关文章
- Elasticsearch基础分布式架构
写在前面的话:读书破万卷,编码如有神-------------------------------------------------------------------- 参考内容: <Ela ...
- Elasticsearch由浅入深(二)ES基础分布式架构、横向扩容、容错机制
Elasticsearch的基础分布式架构 Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式系统,分布式是为了应对大数据量. Elasticsearch ...
- Elasticsearch系列---实现分布式锁
概要 Elasticsearch在文档更新时默认使用的是乐观锁方案,而Elasticsearch利用文档的一些create限制条件,也能达到悲观锁的效果,我们一起来看一看. 乐观锁与悲观锁 乐观锁 E ...
- ElasticSearch实战系列十: ElasticSearch冷热分离架构
前言 本文主要介绍ElasticSearch冷热分离架构以及实现. 冷热分离架构介绍 冷热分离是目前ES非常火的一个架构,它充分的利用的集群机器的优劣来实现资源的调度分配.ES集群的索引写入及查询速度 ...
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
- elasticsearch的分布式基础概念(1)
Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式的系统,分布式是为了应对大数据量 隐藏了复杂的分布式机制 分片机制(随随便便就将一些document插入 ...
- Elasticsearch系列---简单入门实战
概要 本篇主要介绍一下Elasticsearch Document的数据格式,在Java应用程序.关系型数据库建模的对比,介绍在Kibana平台编写Restful API完成基本的集群状态查询,Doc ...
- Elasticsearch系列---实战零停机重建索引
前言 我们使用Elasticsearch索引文档时,最理想的情况是文档JSON结构是确定的,数据源源不断地灌进来即可,但实际情况中,没人能够阻拦需求的变更,在项目的某个版本,可能会对原有的文档结构造成 ...
随机推荐
- VS2017-Linux项目-使用第三方库如何配置
1.虚拟机Ubuntu 16.04,安装第三方库,perftools::tcmalloc. 2.Win10下vs2017创建linux项目. 3.项目>>属性>>VC++ 目录 ...
- java学习6-java基础类库
1.与用户互动 2.系统相关 3.常用类 4.日期.时间类
- 【Autofac打标签模式】PropertySource和Value
[ Autofac打标签模式]开源DI框架扩展地址: https://github.com/yuzd/Autofac.Annotation/wiki *:first-child { margin-to ...
- Azure DevOps 替换 appsettings 解决方案
之前发布了 <.Net Core DevOps -免费用Azure四步实现自动化发布(CI/CD)>之后,有很多朋友私信我说如何替换 appsettings 里面的 ConnectionS ...
- 6G仅仅是比5G多1G吗??
第六代移动通信系统(6th generation mobile networks,或6th generation wireless systems),简称6G,是指第六代移动通信技术,是5G系统后的延 ...
- Java基础(二十一)集合(3)List集合
一.List接口 List集合为列表类型,列表的主要特征是以线性方式存储对象. 1.实例化List集合 List接口的常用实现类有ArrayList和LinkedList,根据实际需要可以使用两种方式 ...
- APP打包设置程序版本号
正确设置方式是: 注意,以下修改不会起作用<manifestxmlns:android="http://schemas.android.com/apk/res/android" ...
- 蓝桥杯基础练习 Huffuman树
基础练习 Huffuman树 问题描述 Huffman树在编码中有着广泛的应用.在这里,我们只关心Huffman树的构造过程. 给出一列数{pi}={p0, p1, -, pn-1},用这列数构造Hu ...
- mysql获取刚插入(添加)记录的自动编号id
我们在写数据库程序的时候,经常会需要获取某个表中的最大序号数, 一般情况下获取刚插入的数据的id,使用select max(id) from table 是可以的.但在多线程情况下,就不行了. 下面介 ...
- MySQL在渗透测试中的应用
原文地址:https://xz.aliyun.com/t/400 前言作为一个安全爱好者你不可能不知道MySQL数据库,在渗透过程中,我们也很经常遇到MySQL数据库的环境,本文就带大家了解MySQL ...