用python爬虫简单爬取 笔趣网:类“起点网”的小说

首先:文章用到的解析库介绍
BeautifulSoup:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
爬取小说原因背景:
以前很喜欢看起点网上面的小说,但是很多都要钱,穷学生没多少钱,就发现了笔趣网。
笔趣看是一个小说网站,这里有很多起点中文网的免费小说,而且这个网站只能在线浏览,不支持小说打包下载。
所以本次爬取呢,就是从该网站爬取并保存一个名为《一念永恒》的小说。
另外本次爬取只是做例子演示,请支持正版资源!!!!!!!!!!!
那么简单的爬取开始:
①打开url链接,按F12或者右键- 检查 进入开发者工具
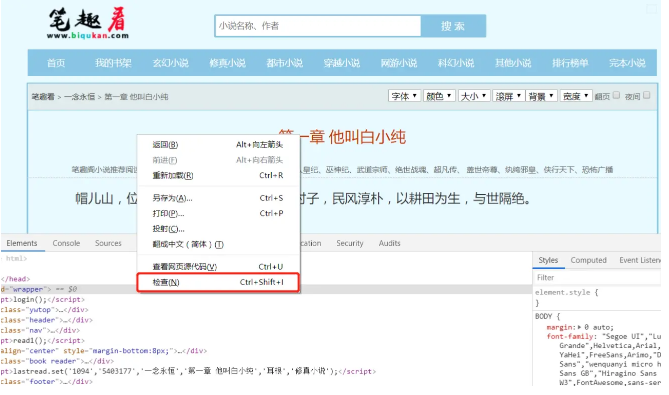
② 在开发者工具中,捕获我们要找到的请求条目信息
选择主文章的一部分内容,选择复制粘贴那一部分,
然后再打开开发者工具栏:
“network—选择放大镜图标sreach—然后再搜索栏粘贴我们要搜索的内容”
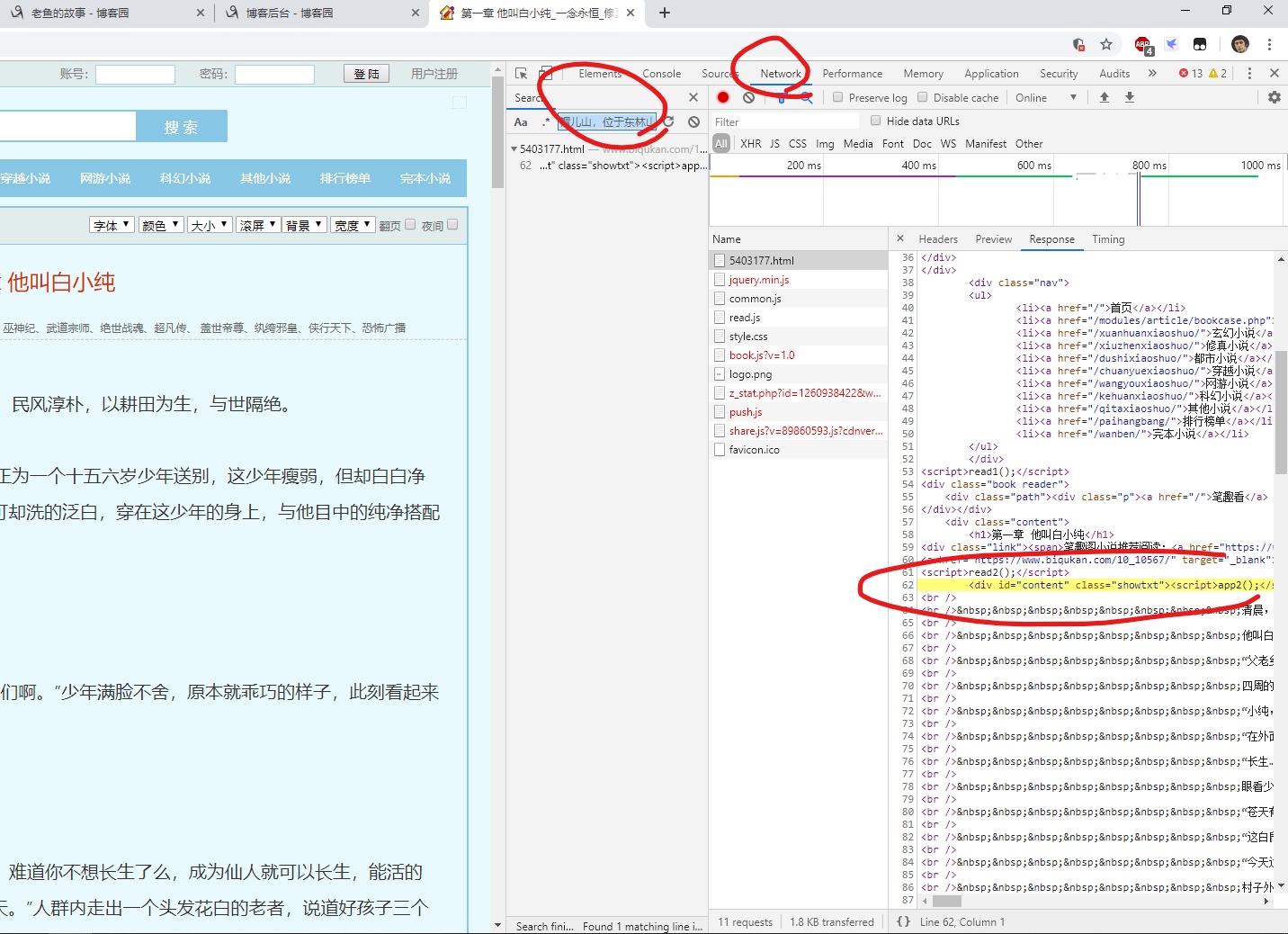
然后会在下方得到条目信息,点击,页面会跳转到加载正文的请求响应条目中。
我们可以看到:
正文部分是处于 id 为 content 和 class 为 showtxt 的 div 中。
③ 构造url请求
上面的信息是不够的,因为现在的网站都有了反爬能力,我们所需要是模拟一条正常从浏览器中发出的url请求链接。
这里我们会用到: User-Agent(浏览器标识)
还是开发者工具,点击Headers,就可以看到Request-Response条目明细。
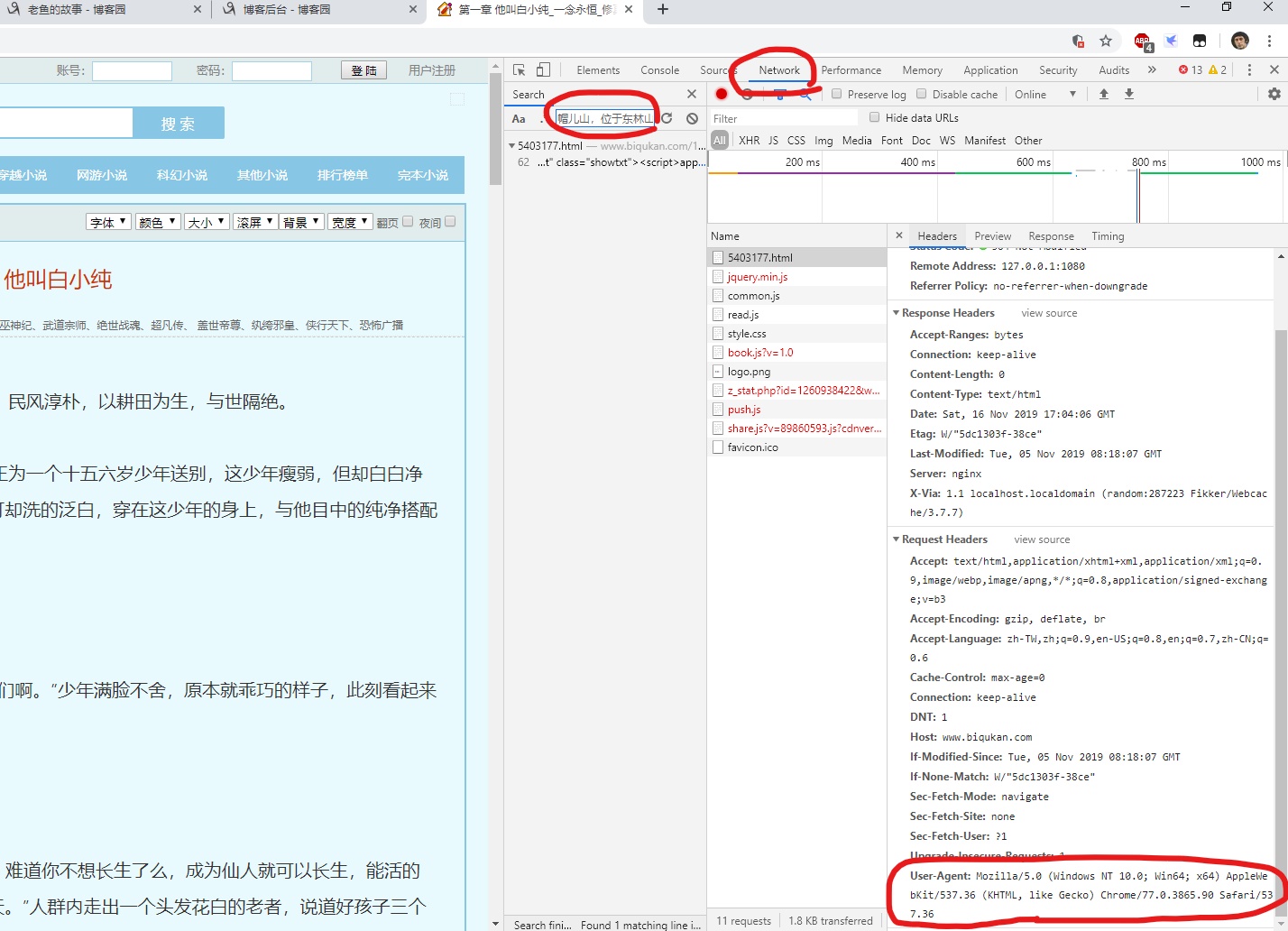
④ 发出请求:
有了字段的详细内容,我们就可以编写出请求网页的代码
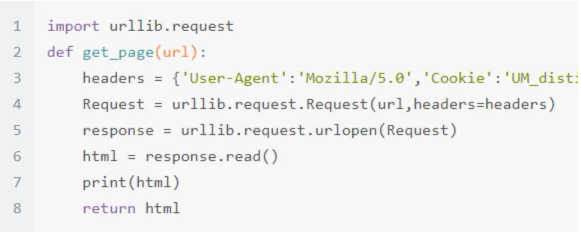
⑤ 获得相应内容,然后运行,得到内容如下:
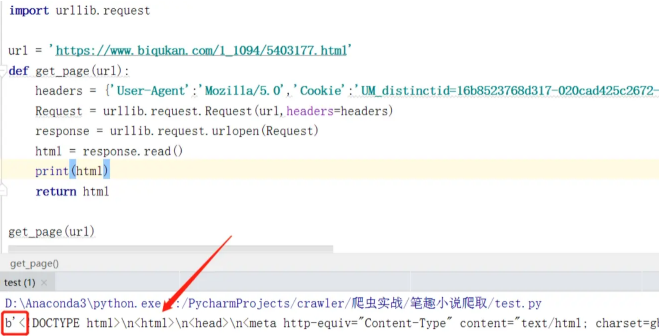
解析响应数据
下面,我们使用BeautifulSoup进行解析 运行….代码结果如图:
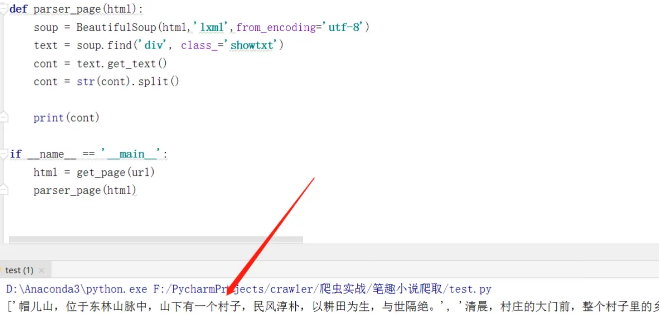
到这里,小说就爬取完成了。
用python爬虫简单爬取 笔趣网:类“起点网”的小说的更多相关文章
- 爬虫入门实例:利用requests库爬取笔趣小说网
w3cschool上的来练练手,爬取笔趣看小说http://www.biqukan.com/, 爬取<凡人修仙传仙界篇>的所有章节 1.利用requests访问目标网址,使用了get方法 ...
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html 模块:requests,bs4,queue,sys,time 步骤:给出URL--> 访问U ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
随机推荐
- Sublime Text 3 免费注册方法(福利)
对于使用Sublime Text但是又不愿花钱注册的小伙伴,福利到了,免费注册一下你的Sublime吧. 版本3207: 打开Sublime text,然后点击菜单Help->Enter Lis ...
- 机器学习笔记(六) ---- 支持向量机(SVM)
支持向量机(SVM)可以说是一个完全由数学理论和公式进行应用的一种机器学习算法,在小批量数据分类上准确度高.性能好,在二分类问题上有广泛的应用. 同样是二分类算法,支持向量机和逻辑回归有很多相似性,都 ...
- 华为云DevCloud为开发者提供高效智能的可信开发环境
在HUAWEI CONNECT 2019期间,在华为云云服务开发者分论坛上,华为云布道师做了<CloudIDE:开发者的高效.智能的可信开发环境>专题演讲,主要介绍了华为云DevCloud ...
- 二叉树的建立&&前中后遍历(递归实现)&&层次遍历
下面代码包含了二叉树的建立过程,以及三种遍历方法了递归实现,代码中还利用队列实现了层次遍历. import java.util.LinkedList; import java.util.Queue; ...
- NSDateFormatter格式详细列表一览
转自:http://www.cnblogs.com/xinus/archive/2012/10/29/NSDateFormatter_samples.html 前言:iOS开发中NSDateForma ...
- git 使用详解 (1)——历史
版本控制系统(VCS) 有了它你就可以将某个文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态.你可以比较文件的变化细节,查出最后是谁修改了哪个地方,从而导致出现怪异问题,又是谁在何时报 ...
- hdu3015,poj1990树状数组
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3015 题意:给定n组数,每组数有值x和值h,求n组数两两的val的总和.将所有x和所有h分别离散化(不 ...
- 2018 ACM-ICPC南京区域赛题解
解题过程 开场开A,A题shl看错题意,被制止.然后开始手推A,此时byf看错E题题意,开始上机.推出A的规律后,shl看了E题,发现题意读错.写完A题,忘记判断N=0的情况,WA+1.过了A后,sh ...
- CF372C Watching Fireworks is Fun(单调队列优化DP)
A festival will be held in a town's main street. There are n sections in the main street. The sectio ...
- 【Redis】349- Redis 入门指南
点击上方"前端自习课"关注,学习起来~ 1. 概述 1.1. Redis 简介 Redis 是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映 ...