HDFS之DataNode
DataNode工作机制
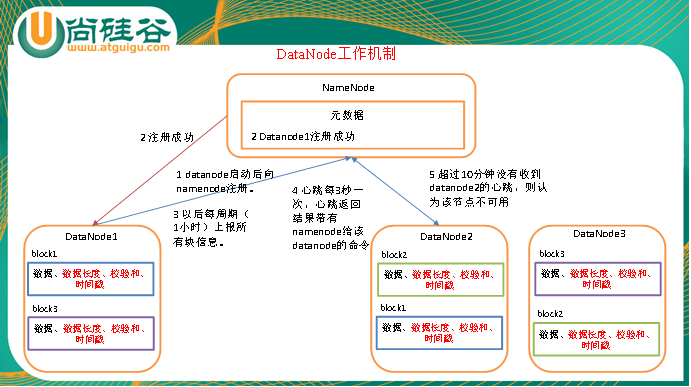
1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器
数据完整性
1)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum
掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
|
<property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name> dfs.heartbeat.interval </name> <value>3</value> </property> |
服役新数据节点
(1)在namenode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
[atguigu@hadoop105 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop105 hadoop]$ touch dfs.hosts
[atguigu@hadoop105 hadoop]$ vi dfs.hosts
添加如下主机名称(包含新服役的节点)
hadoop102
hadoop103
hadoop104
hadoop105
(2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性
|
<property> <name>dfs.hosts</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value> </property> |
(3)刷新namenode
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
(4)更新resourcemanager节点
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
(5)在namenode的slaves文件中增加新主机名称
增加105 不需要分发
hadoop102
hadoop103
hadoop104
hadoop105
(6)单独命令启动新的数据节点和节点管理器
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
(7)在web浏览器上检查是否ok
3)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 sbin]$ ./start-balancer.sh
退役旧数据节点
1)在namenode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts.exclude文件
[atguigu@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop102 hadoop]$ touch dfs.hosts.exclude
[atguigu@hadoop102 hadoop]$ vi dfs.hosts.exclude
添加如下主机名称(要退役的节点)
hadoop105
2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
|
<property> <name>dfs.hosts.exclude</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value> </property> |
3)刷新namenode、刷新resourcemanager
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
4)检查web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点。
5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
6)从include文件中删除退役节点,再运行刷新节点的命令
(1)从namenode的dfs.hosts文件中删除退役节点hadoop105
hadoop102
hadoop103
hadoop104
(2)刷新namenode,刷新resourcemanager
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
7)从namenode的slave文件中删除退役节点hadoop105
hadoop102
hadoop103
hadoop104
8)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-balancer.sh
HDFS之DataNode的更多相关文章
- HDFS Namenode&Datanode
HDFS Namenode&Datanode HDFS 机制粗略示意图 客户端写入文件流程: NN && DN Namenode(NN)工作机制 NN是整个文件系统的管理节点. ...
- org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in receiveBlock for block
Hbase依赖的datanode日志中如果出现如下报错信息:DataXceiverjava.io.EOFException: INFO org.apache.hadoop.hdfs.server.da ...
- Datanode启动问题 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering>
-- ::, INFO org.apache.hadoop.hdfs.server.datanode.DataNode: supergroup = supergroup -- ::, INFO org ...
- ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Incompatible namespaceIDs
用三台centos操作系统的机器搭建了一个hadoop的分布式集群.启动服务后失败,查看datanode的日志,提示错误:ERROR org.apache.hadoop.hdfs.server.dat ...
- FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to controller/192.168.1.183:9000. Exiting. java.io.IOExcep
2018-01-09 09:47:38,297 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed ...
- hdfs.server.datanode.DataNode: Block pool ID needed, but service not yet registered with NN
启动hadoop 发现 50070 的 livenode 数量是 0 查看日志, hdfs.server.datanode.DataNode: Block pool ID needed, but se ...
- Hadoop启动HDFS时DataNode未启动
在用$HADOOP_HOME/sbin/start-dfs.sh启动HDFS时发现只有NameNode和SecondaryNameNode启动,没有DataNode. 查看logs下的DataNode ...
- 启动HDFS时datanode无法启动的坑
启动HDFS 启动hdfs,进入sbin目录,也可以执行./start-all.sh - $cd /app/hadoop/hadoop-2.2.0/sbin - $./start-dfs.sh 在此之 ...
- hdfs的datanode工作原理
datanode的作用: (1)提供真实文件数据的存储服务. (2)文件块(block):最基本的存储单位.对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序 ...
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
随机推荐
- 使用zrender.js绘制体温单(2)
今天我们来画折线图 效果图 以下为模拟数据 [{"time":19,"text":"入\n院\n19\n时\n11\n分","po ...
- 数据类型(二)---day04
目录 上节课回顾 五 变量 (一)什么是变量 (二)变量的组成 (三)变量名的命名规范 (四)常量 (五)python变量内存管理 (六)变量的三种打印方式 六 数据类型 (一)数字类型 (二)字符串 ...
- boostrap原理.html
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 搭建 vue-cli 和 引入 Element-ui 最完整的入门例子(手把手)
搭建 vue-cli 脚手架 安装 git 安装 node 并配置环境变量,使用 zip 版本 # 检查 node 是否安装成功 node -v 使用淘宝镜像 npm config set regis ...
- js如何展示上传的图片
前言:本文章主要讲的是上传的图片如何展示在页面上. 一般来说,我们会先将本地图片上传到服务器,上传成功后,由后台返回图片的网络地址再在前端显示.但是,我今天讲的是不通过前面说的过程,而是直接使用js将 ...
- 适用于Windows桌面应用程序的.NET Core 3
介绍 9月,微软发布了新版.NET Core,用于构建Windows桌面应用程序,包括WPF和Windows Forms.从那时起开发人员可以将传统的nfx桌面应用程序(和控件库)迁移到.NET Co ...
- Python基础-语法知识
——编程语言的发展史 机器语言 优点:执行速度够快 缺点:开发效率非常低 汇编语言 优点:执行效率相较于机器语言略低 缺点:开发效率相较于机器语言略高 高级语言 C.C++.C#.java.PHP.p ...
- 前端技术之:如何运行使用了ES(import)的node程序
方式一: 在package.json文件的scripts域中,配置以下的命令: "start": "cross-env NODE_ENV=dev node -r es ...
- Python安装cx_Oracle与操作数据测试小结
这里简单总结一下Python操作Oracle数据库这方面的相关知识.只是简单的整理一下之前的实验和笔记.这里的测试服务器为CentOS Linux release 7.5. 个人实验.测试.采集数据的 ...
- 学习笔记13_第三方js控件&EasyUI使用
第三方UI包使用思路: 1.先映入各种JS包,包含JS版本包,第三方CSS包,第三方主JS包,第三方语言包. 2.确定要做什么,是对话框还是表格.3.根据Demo和目的,在<body>内, ...