决策树算法系列之一 ID3
1 什么是决策树
- 通俗来说,决策树分类的思想类似于找对象
- 一个女孩的母亲要给这个女孩介绍男朋友 (分类问题、见或不见)
- 女孩有自己的一套标准
| 长相 | 收入 | 职业 | 见面与否 |
|---|---|---|---|
| 丑 | 高 | 某箭队经理 | 不见 |
| 中等 | 低 | 某大学学生会主席 | 不见 |
| 中等 | 中等 | 某NN记者 | 不见 |
| 中等 | 高 | 某上市公司CTO | 见 |
| 帅 | 中等 | 公务员 | 见 |
那么有下面的对话
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
2 决策树的做法
每次选择一个属性进行判断, 若不能得出结论,继续选择其
他属性进行判断,直到能够“肯定地”判断
长相 -> 收入 -> 职业
如何让机器学习到这种有递进关系、且考虑有优先顺序属性像树结构的分类方法?
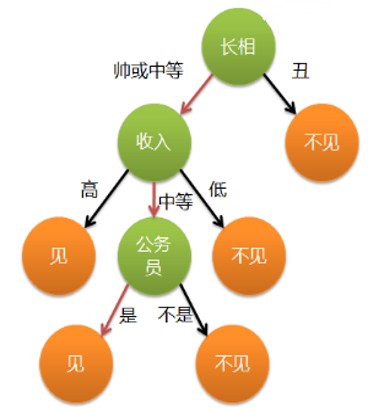
图1 一颗简单的决策树
3 决策树的构建
- 步骤1:将所有的数据看成是一个节点,进入步骤2;
- 步骤2:从中挑选一个数据特征对节点进行分割,进入步骤3;
- 步骤3:生成若干孩子节点,对每一个孩子节点进行判断若满足停止分裂的条件,进入步骤4;否则,进入步骤2;
- 步骤4:设置该节点是子节点,其输出为该节点数量占比最大的类别。
所以有三个问题:
(1) 数据如何分割
离散型数据的分割
连续型数据的分割
(2)如何选择分裂的属性
分裂算法(ID3 C4.5 CART)
(3)什么时候停止分裂
最小节点数、树深度、所有特征已经使用完毕
4 一个做分类的数据集
| 天气 | 温度 | 湿度 | 是否有风 | 是否室内打网球 |
|---|---|---|---|---|
| 晴 | 热 | 高 | 否 | 否 |
| 晴 | 热 | 高 | 是 | 否 |
| 阴 | 热 | 高 | 否 | 是 |
| 雨 | 温 | 高 | 否 | 是 |
| 雨 | 凉爽 | 中 | 否 | 是 |
| 雨 | 凉爽 | 中 | 是 | 否 |
| 阴 | 凉爽 | 中 | 是 | 是 |
| 晴 | 温 | 高 | 否 | 否 |
| 晴 | 凉爽 | 中 | 否 | 是 |
| 雨 | 温 | 中 | 否 | 是 |
| 晴 | 温 | 中 | 是 | 是 |
| 阴 | 温 | 高 | 是 | 是 |
| 阴 | 热 | 中 | 否 | 是 |
| 雨 | 温 | 高 | 是 | 否 |
5 ID算法
训练集为D, 总样本数|D|
训练集中有N个类别,|Ci|为第i个类别的数量
假设其中一个属性A有n个不同离散取值(a1,a2…an)
假设取值a1样本集为Da1,个数为|Da1|,其中属于第j个类的个数为|Da1,j |
假设取值a2样本集为Da2,个数为|Da2|,其中属于第j个类的个数为|Da2,j|
…
假设取值an样本集为Dan,个数为|Dan|,其中属于第j个类的个数为|Dan,j|
(1) 计算数据集D的经验熵
\[H\left( D \right) = - \sum\limits_{i = 1}^N {\frac{{\left| {{C_i}} \right|}}{{\left| D \right|}}} \log \frac{{\left| {{C_i}} \right|}}{{\left| D \right|}}\]
(2) 计算属性A对数据集D的经验条件熵
\[ H\left( {D\left| A \right.} \right) = \sum\limits_{i = 1}^n {\frac{{\left| {{D_{ai}}} \right|}}{{\left| D \right|}}} H\left( {{D_{ai}}} \right) = \sum\limits_{i = 1}^n {\left( {\frac{{\left| {{D_{ai}}} \right|}}{{\left| D \right|}}\left( { - \sum\limits_{j = 1}^N {\frac{{\left| {{D_{ai,j}}} \right|}}{{\left| {{D_{ai}}} \right|}}\log \frac{{\left| {{D_{ai,j}}} \right|}}{{\left| {{D_{ai}}} \right|}}} } \right)} \right)} \]
(3) 计算属性A信息增益
\[ G\left( {D\left| A \right.} \right){\rm{ = }}H\left( D \right) - H\left( {D\left| A \right.} \right) \]
选择使得G(D|A)最大的属性A作为最优属性进行决策划分
6 具体实例
(1) 计算数据集D的经验熵
一共14个样本,9个正例、5个负例
\[ H\left( D \right) = - \left( {\frac{{\rm{9}}}{{{\rm{14}}}}\log \frac{{\rm{9}}}{{{\rm{14}}}}{\rm{ + }}\frac{{\rm{5}}}{{{\rm{14}}}}\log \frac{{\rm{5}}}{{{\rm{14}}}}} \right){\rm{ = }}0.2830 \]
(2) 计算属性对数据集D的经验条件熵 (天气属性)
天气一共有晴、阴、雨三个属性
天气 =晴 , 2个正例、3个负例,所以
\[H\left( {D\left| {{A_晴}} \right.} \right) = - \left( {\frac{2}{5}\log \frac{2}{5}{\rm{ + }}\frac{3}{5}\log \frac{3}{5}} \right){\rm{ = }}0.{\rm{2923}}\]
天气 =阴, 4个正例、0个负例, 所以
\[H\left( {D\left| {{A_阴}} \right.} \right) = - \left( {\frac{4}{4}\log \frac{4}{4}{\rm{ + }}\frac{0}{4}\log \frac{0}{4}} \right){\rm{ = 0}}\]
天气 =雨, 3个正例、2个负例,所以
\[ H\left( {D\left| {{A_雨}} \right.} \right) = - \left( {\frac{3}{5}\log \frac{3}{5}{\rm{ + }}\frac{2}{5}\log \frac{2}{5}} \right){\rm{ = }}0.{\rm{2923}} \]
所以天气属性的经验条件熵为
\[ H\left( {D\left| A \right.} \right) = \frac{{\rm{5}}}{{{\rm{14}}}} \cdot 0.{\rm{2923 + }}\frac{{\rm{4}}}{{{\rm{14}}}} \cdot {\rm{0 + }}\frac{{\rm{5}}}{{{\rm{14}}}} \cdot 0.{\rm{2923 = }}0.{\rm{2}}0{\rm{87}} \]
(3) 天气属性的信息增益
\[ G\left( {D\left| A \right.} \right) = H\left( D \right) - H\left( {D\left| A \right.} \right) = 0.0{\rm{743}} \]
同理可以算出温度、湿度、是否有风的信息增益
| 属性 | 信息增益 |
|---|---|
| 天气 | 0.0743 |
| 温度 | 0.0088 |
| 湿度 | 0.0457 |
| 是否有风 | 0.0145 |
因此天气的信息增益最大,决策树第一个决策节点选择天气进行决策即有:
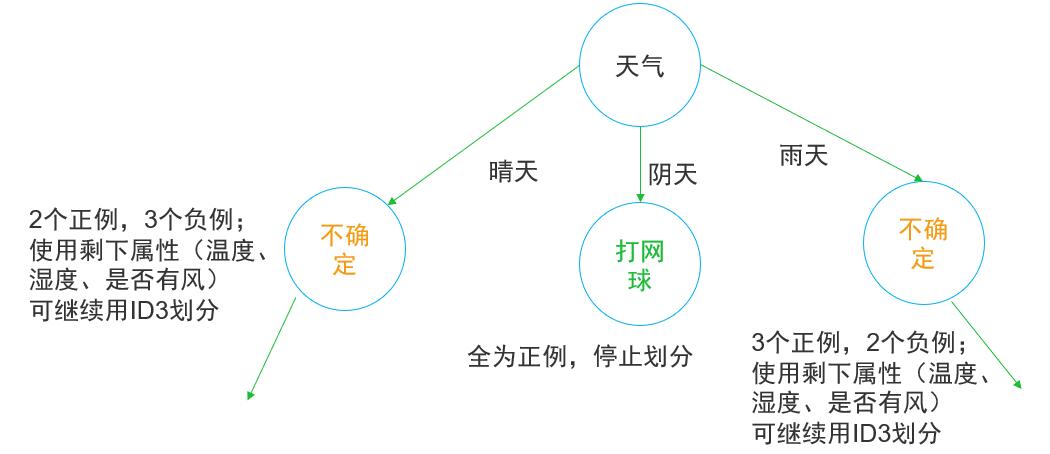
图2 决策树节点划分
决策树算法系列之一 ID3的更多相关文章
- 机器学习回顾篇(7):决策树算法(ID3、C4.5)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 【sklearn决策树算法】DecisionTreeClassifier(API)的使用以及决策树代码实例 - 鸢尾花分类
决策树算法 决策树算法主要有ID3, C4.5, CART这三种. ID3算法从树的根节点开始,总是选择信息增益最大的特征,对此特征施加判断条件建立子节点,递归进行,直到信息增益很小或者没有特征时结束 ...
- 就是要你明白机器学习系列--决策树算法之悲观剪枝算法(PEP)
前言 在机器学习经典算法中,决策树算法的重要性想必大家都是知道的.不管是ID3算法还是比如C4.5算法等等,都面临一个问题,就是通过直接生成的完全决策树对于训练样本来说是“过度拟合”的,说白了是太精确 ...
- ID3决策树算法原理及C++实现(其中代码转自别人的博客)
分类是数据挖掘中十分重要的组成部分.分类作为一种无监督学习方式被广泛的使用. 之前关于"数据挖掘中十大经典算法"中,基于ID3核心思想的分类算法C4.5榜上有名.所以不难看出ID3 ...
- 决策树算法原理(ID3,C4.5)
决策树算法原理(CART分类树) CART回归树 决策树的剪枝 决策树可以作为分类算法,也可以作为回归算法,同时特别适合集成学习比如随机森林. 1. 决策树ID3算法的信息论基础 1970年昆兰找 ...
- python机器学习笔记 ID3决策树算法实战
前面学习了决策树的算法原理,这里继续对代码进行深入学习,并掌握ID3的算法实践过程. ID3算法是一种贪心算法,用来构造决策树,ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性 ...
- 决策树算法——ID3
决策树算法是一种有监督的分类学习算法.利用经验数据建立最优分类树,再用分类树预测未知数据. 例子:利用学生上课与作业状态预测考试成绩. 上述例子包含两个可以观测的属性:上课是否认真,作业是否认真,并以 ...
- ID3和C4.5分类决策树算法 - 数据挖掘算法(7)
(2017-05-18 银河统计) 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来判断其可行性的决策分析方法,是直观运用概率分析的一种图解法.由于这种决策分支画 ...
- 机器学习-ID3决策树算法(附matlab/octave代码)
ID3决策树算法是基于信息增益来构建的,信息增益可以由训练集的信息熵算得,这里举一个简单的例子 data=[心情好 天气好 出门 心情好 天气不好 出门 心情不好 天气好 出门 心情不好 天气不好 ...
随机推荐
- c语言实现字符指针(字符串)数组的排序
需求: "ff555d", "114ddd", "114dd","aaa", "aaab", &qu ...
- 搭建自己的技术博客系列(二)把 Hexo 博客部署到 GitHub 上
1.在GitHub上建一个新仓库
- Maven工程读取properties文件过程
1.创建需要读取的properties文件 2.在xml文件中加载配置文件 <!-- 加载配置文件 --> <context:property-placeholder locatio ...
- PythonI/O进阶学习笔记_4.自定义序列类(序列基类继承关系/可切片对象/推导式)
前言: 本文代码基于python3 Content: 1.python中的序列类分类 2. python序列中abc基类继承关系 3. 由list的extend等方法来看序列类的一些特定方法 4. l ...
- Django跳转到不同的页面的方法和实例–使用Django建立你的第一个网站
1 前记 这次记录的这些东西,主要是自己在搭建个人网站的时候遇到的一些问题记录,不算严格意义上的教程和使用说明.按照目前自己的web水平,去写这方面的教程无疑是误人子弟.因为自己虽然做程序员很多年,但 ...
- 疑难杂症----udf提权无法导出.dll
昨天进行测试一个网站,进行udf提权时候,没办法导出.dll, 起初以为是这个马的问题,后来用专用马,一样不行,但是有报错了,有上网找了半天,终于被我找到了. Mysql数据库从文件导入或导出到文件, ...
- Cookie的临时存储和定时存储
Cookie解决了不同请求的数据共享问题.是由服务器保存在客户端的小文本文件,包含了用户的信息,可以避免用户重复输入用户名和密码进行登录.浏览器请求Cookie,服务器响应时返回Cookie,浏览器存 ...
- Vue最全指令大集合————VUE
# Vue指令大集合(无slot) #### 包含内容: 1. v-cloak2. v-html3. v-text4. v-bind5. v-show6. v-model7. v-for8. v-if ...
- ppt课件动手动脑实际验证
1关于double精度 源代码:public class Doublejingdu { public static void main(String[] args) { System.out.prin ...
- selenium-01-2环境搭建
首先下载好Eclipse 和配置好Java 环境变量 步骤省略, 请百度 方法一 添加jar包 官方下载地址: http://www.seleniumhq.org/download/ 官方地址 ...