pyspark+anaconda配置
参考 https://www.e-learn.cn/content/python/786199
注意
所有的变量都放在环境变量而非用户变量。比如JAVA_HOME。
不然虽然pyspark没问题,但是java会出问题懒得改下面的图了
1.安装anaconda
官网下载安装python3.7版
2.安装JAVA
官网下载安装
https://www.oracle.com/technetwork/java/javase/overview/index.html (建议 安装 jdk-8u211,8开头的1.8版本。安装12.0跑代码的时候出错)
设置环境变量
安装好以后,配置Java的环境变量,右键我的电脑,依次点击属性-高级系统设置-环境变量
新建用户变量: JAVA_HOME;C:\Program Files\Java\jdk-XXXXXX
//这里有问题,见最后的错误及解决

在系统变量中找到Path,点击按钮新建,然后添加文字%JAVA_HOME%\bin,最后按回车Enter,一直点击确定,就保存了更改,这样就将bin文件夹中的Java程序放到了系统变量中。

3.下载安装并配置Spark
官网 http://spark.apache.org/downloads.html
官方网站Download Apache Spark下载相应版本的spark,因为spark是基于hadoop的,需要下载对应版本的hadoop才行,这个页面有对hadoop的版本要求

配置环境变量
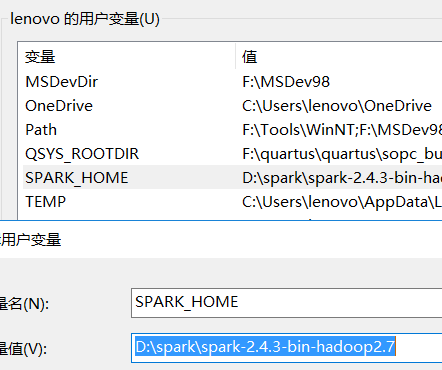
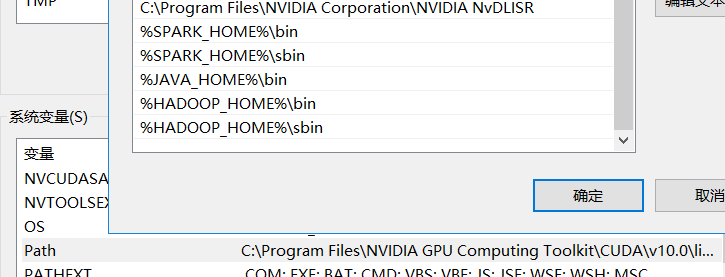
分别在用户变量添加SPARK_HOME ,在环境变量的PATH 添加对应的bin,sbin
4.安装并配置Hadoop
http://hadoop.apache.org/releases.html
上面安装spark的时候有对hadoop的版本要求,这里要求的是2.7及以后的版本,进入官方网站Apache Hadoop Releases下载3.1.2 binary版本,
其中source版本是该版本hadoop的源代码,下载以后解压(需要管理员权限解压)

配置环境变量:
右键我的电脑,依次点击属性-高级系统设置-环境变量
新增用户变量 HADOOP_HOME
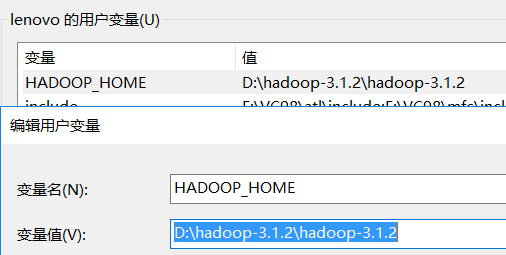
然后找到系统变量Path 点击按钮新建,然后添加文本%HADOOP%\bin,按回车enter,继续新建一个,添加文本%HADOOP%\sbin,
按键回车,一直点击确定,就保存了更改,这样就将bin、sbin文件夹中的程序放到了系统变量中

从网站中下载一个压缩包,然后解压出来,复制其中的winutils.exe和winutils.pdb到hadoop的安装文件夹中,
复制目录为:D:\hadoop-3.1.2\hadoop-3.1.2\bin
https://github.com/srccodes/hadoop-common-2.2.0-bin
5.安装pyspark
cmd,进入spark的python目录
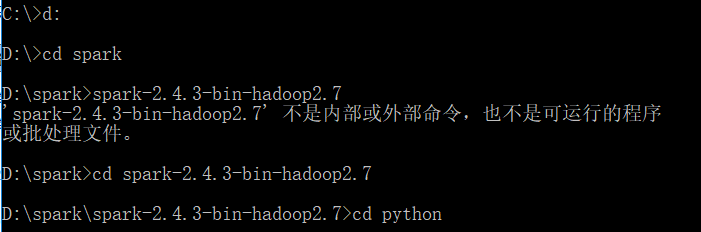
pip install pyspark

6.检查
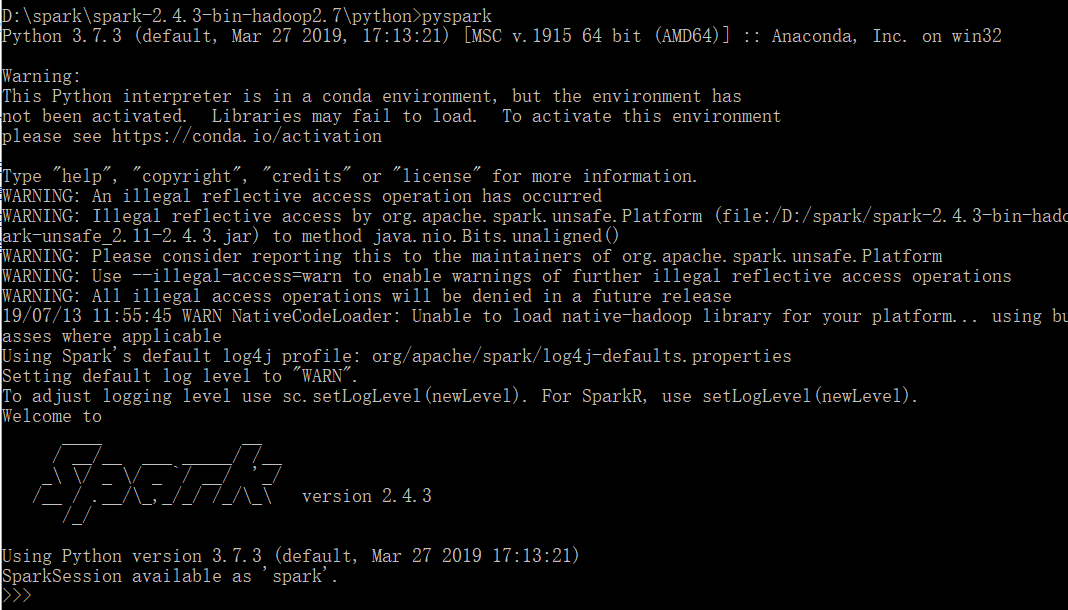
参考https://blog.csdn.net/qq_38799155/article/details/78254580
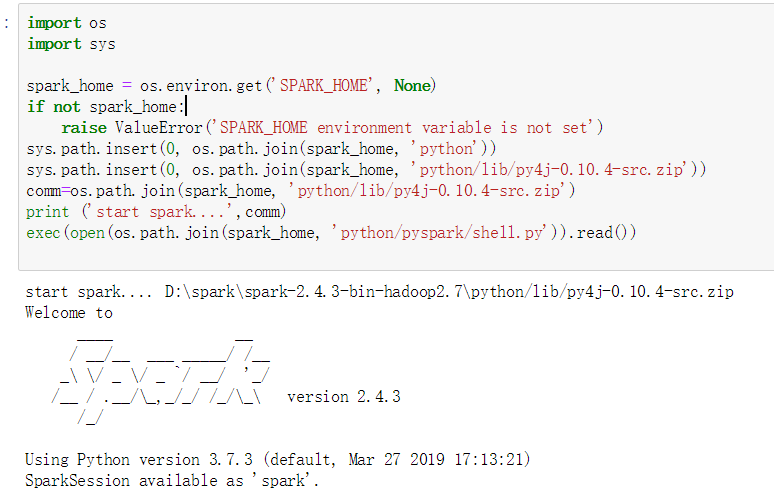
import os
import sys spark_home = os.environ.get('SPARK_HOME', None)
if not spark_home:
raise ValueError('SPARK_HOME environment variable is not set')
sys.path.insert(0, os.path.join(spark_home, 'python'))
sys.path.insert(0, os.path.join(spark_home, 'python/lib/py4j-0.10.4-src.zip'))
comm=os.path.join(spark_home, 'python/lib/py4j-0.10.4-src.zip')
print ('start spark....',comm)
exec(open(os.path.join(spark_home, 'python/pyspark/shell.py')).read())
遇到的问题

原因,添加的JAVA环境路径包含空格

修改为

pyspark+anaconda配置的更多相关文章
- Anaconda 配置 Python 环境
原文地址:Anaconda 配置 Python 环境 0x00 环境 Anaconda: 2019.03 Python: 3.6.8 0x01 Linux 安装 Anaconda 交互安装 Anaco ...
- Anaconda配置环境变量+创建虚拟环境+pycharm使用虚拟环境
Anaconda配置环境变量+创建虚拟环境 配置环境变量 没有添加系统变量,所有系统根本识别不了conda命令,找不到位置,所以添加以下系统变量: 添加对应Anaconda环境变量:(以自己的安装路径 ...
- Anaconda配置多spyder多python环境
作者:桂. 时间:2017-04-17 22:02:37 链接:http://www.cnblogs.com/xingshansi/p/6725298.html 前言 最近在看<统计学习方法 ...
- 【Python】Anaconda配置
Anaconda 是一个用于科学计算的Python发行版,支持 Linux.Mac.Windows 系统,提供了包管理与环境管理的功能,可以很方便地解决多版本 Python 并存.切换以及各种第三方包 ...
- WIN10下使用Anaconda配置opencv、tensorflow、pygame并在pycharm中运用
昨天想运行一段机器学习的代码,在win10系统下配置了一天的python环境,真的是头疼,准备写篇博客来帮助后面需要配置环境的兄弟. 1.下载Anaconda 根据昨天的经历,发现Anaconda真的 ...
- Win7系统中用anaconda配置tensorflow运行环境
前言:anaconda是一个python Data Science Platform.安装它的契机是因为要用tensorflow. 安装完后感觉用它来管理python运行环境还是挺方便的,常用的con ...
- anaconda配置清华大学开源软件镜像
配置镜像在anaconda安装好之后,默认的镜像是官方的,由于官网的镜像在境外,使用国内的镜像能够加快访问的速度.这里选择了清华的的镜像.镜像的地址如下:tuna.Anaconda 安装包可以到 ht ...
- 【Python开发】Pycharm下的Anaconda配置
我的系统是Win 64位的,用的Python 3.5.1 ,最近在学机器学习,用到了Numpy这个科学计算库,网上查了之后,看到很多装Numpy出问题的情况,所以决定装Anaconda,简单一些,并且 ...
- Anaconda配置Python开发环境
Anaconda介绍 Anaconda 是在 linux.windows 和 mac os x 上执行 Python/R 数据分析和机器学习的最简单的方式并且它是开源的.它在全球拥有超过 1, 100 ...
随机推荐
- postgres模糊匹配大杀器
ArteryBase-模糊匹配大杀器 问题背景 随着pg越来越强大,abase目前已经升级到5.0(postgresql10.4),目前abase5.0继承了全文检索插件(zhparser),使用全文 ...
- 【源码解读】js原生消息提示插件
效果如下: 关闭message后前后message的衔接非常丝滑,这部分是我比较感兴趣的.带着这个问题先了解下DOM结构,顺便整理下作者的思路. 从DOM里我们可以看到所有的message都在一个容器 ...
- mysql 设置外键约束时如何删除数据
Mysql中如果表和表之间建立的外键约束,则无法删除表及修改表结构 解决方法是在Mysql中取消外键约束: SET FOREIGN_KEY_CHECKS=0; 然后将原来表的数据导出到sql语句,重新 ...
- proxmox ve系统绑定上联外网出口bond双网卡
背景描述:一个客户搭建proxmox ve系统,要求上联出口双网卡绑定bond, proxmox ve下载地址:超链接 记录日期:2020/5/9 前期准备:服务器接好2个网卡 交换机:H3C 1.p ...
- DNS是如何工作的?
今天很多人都在讲域名系统和互联网作为一个整体是如何工作的,域名系统---也就是大家所熟知的DNS.不幸的是,对于天龙人和普通人来说,他们并不了解DNS到底是什么鬼.今天就来聊聊DNS,和那些想了解DN ...
- 在线配置热加载配置 go-kratos.dev 监听key
paladin https://v1.go-kratos.dev/#/config-paladin example Service(在线配置热加载配置) # service.go type Servi ...
- 京东热 key 探测框架新版发布,单机 QPS 可达 35 万
https://mp.weixin.qq.com/s/3URAvUF6zwxeF5Kkc1aWHA 京东热 key 探测框架新版发布,单机 QPS 可达 35 万 原创 Hollis Hollis 2 ...
- 令牌桶、漏斗、冷启动限流在sentinel的应用
分布式系统为了保证系统稳定性,在服务治理的限流中会根据不同场景进行限流操作,常见的限流算法有: 令牌桶:可容忍一定突发流量的速率的限流,令牌桶算法的原理是系统以恒定的速率产生令牌,然后把令牌放到令牌桶 ...
- eclipse项目放到github
一,下载git ,配置用户名和邮箱: git config --global user.name "name" git config --global user.ema ...
- 日志框架(Log4J、SLF4J、Logback)--日志规范与实践
文章目录 一.Log4j 1.1新建一个Java工程,导入Log4j包,pom文件中对应的配置代码如下: 1.2resources目录下创建log4j.properties文件. 1.3输出日志 1. ...