Spark Shuffle之Sort Shuffle
源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正。原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/sort-shuffle.md
正如你所知,spark实现了多种shuffle方法,通过 spark.shuffle.manager来确定。暂时总共有三种:hash shuffle、sort shuffle和tungsten-sort shuffle,从1.2.0开始默认为sort shuffle。本节主要介绍sort shuffle。
从1.2.0开始默认为sort shuffle(spark.shuffle.manager = sort),实现逻辑类似于Hadoop MapReduce,Hash Shuffle每一个reducers产生一个文件,但是Sort Shuffle只是产生一个按照reducer id排序可索引的文件,这样,只需获取有关文件中的相关数据块的位置信息,并fseek就可以读取指定reducer的数据。但对于rueducer数比较少的情况,Hash Shuffle明显要比Sort Shuffle快,因此Sort Shuffle有个“fallback”计划,对于reducers数少于 “spark.shuffle.sort.bypassMergeThreshold” (200 by default),我们使用fallback计划,hashing相关数据到分开的文件,然后合并这些文件为一个,具体实现为BypassMergeSortShuffleWriter。
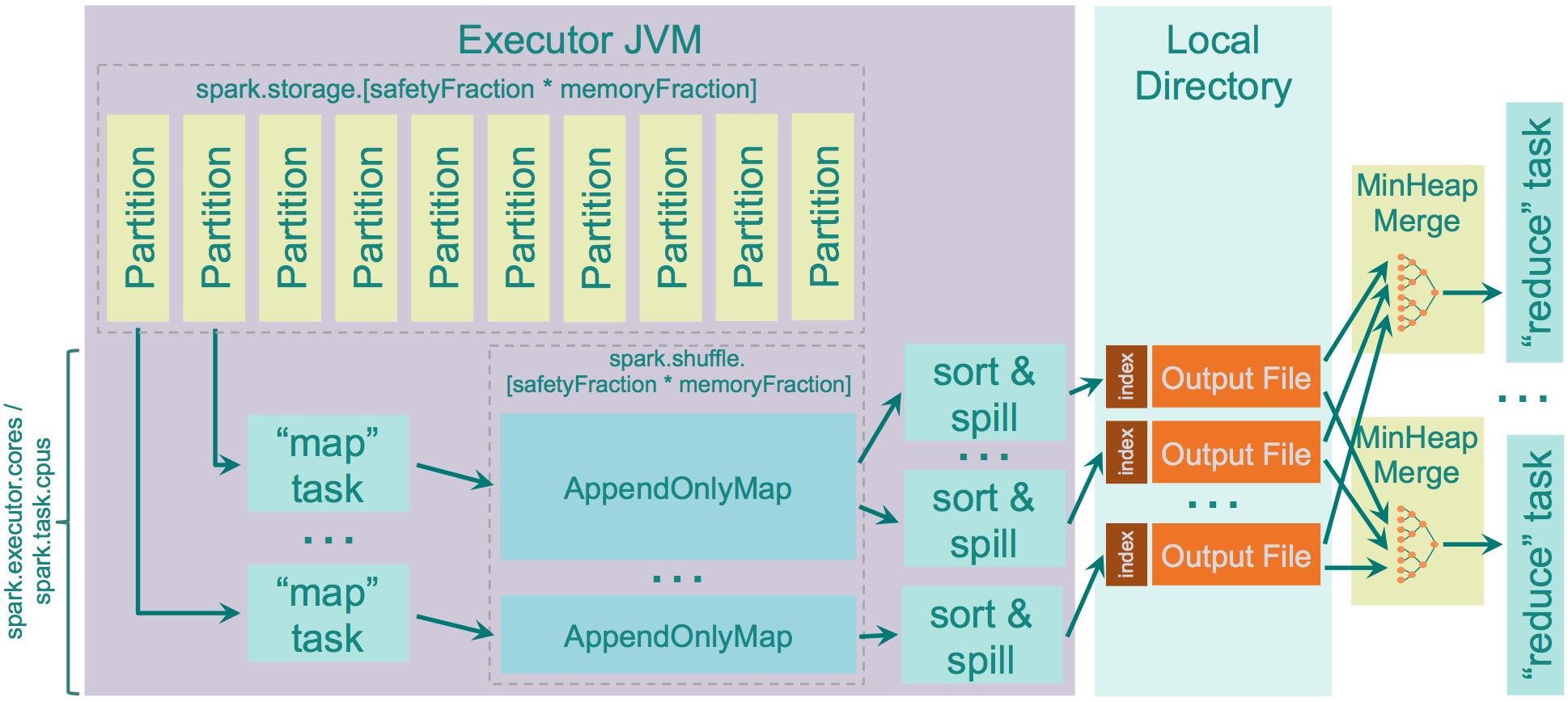
在map进行排序,在reduce端应用Timsort[1]进行合并。map端是否容许spill,通过spark.shuffle.spill来设置,默认是true。设置为false,如果没有足够的内存来存储map的输出,那么就会导致OOM错误,因此要慎用。
用于存储map输出的内存为:“JVM Heap Size” \* spark.shuffle.memoryFraction \* spark.shuffle.safetyFraction,默认为“JVM Heap Size” \* 0.2 \* 0.8 = “JVM Heap Size” \* 0.16。如果你在同一个执行程序中运行多个线程(设定spark.executor.cores/ spark.task.cpus超过1),每个map任务存储的空间为“JVM Heap Size” * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus, 默认2个cores,那么为0.08 * “JVM Heap Size”。
spark使用AppendOnlyMap存储map输出的数据,利用开源hash函数MurmurHash3和平方探测法把key和value保存在相同的array中。这种保存方法可以是spark进行combine。如果spill为true,会在spill前sort。
Sort Shuffle内存的源码级别更详细说明可以参考[4],读写过程可以参考[5]
优点
- map创建文件量较少
- 少量的IO随机操作,大部分是顺序读写
缺点
- 要比Hash Shuffle要慢,需要自己通过
spark.shuffle.sort.bypassMergeThreshold来设置合适的值。 - 如果使用SSD盘存储shuffle数据,那么Hash Shuffle可能更合适。
参考
[1][Timsort原理介绍](http://blog.csdn.net/yangzhongblog/article/details/8184707)
[2][形式化方法的逆袭——如何找出Timsort算法和玉兔月球车中的Bug?](http://bindog.github.io/blog/2015/03/30/use-formal-method-to-find-the-bug-in-timsort-and-lunar-rover/)
[3][Spark Architecture: Shuffle](http://0x0fff.com/spark-architecture-shuffle/)
[4][Spark Sort Based Shuffle内存分析](http://www.jianshu.com/p/c83bb237caa8)
[5][Spark Shuffle Write阶段磁盘文件分析](http://www.jianshu.com/p/2d837bf2dab6)
Spark Shuffle之Sort Shuffle的更多相关文章
- Spark Shuffle之Hash Shuffle
源文件放在github,如有谬误之处,欢迎指正.原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/hash-sh ...
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- Spark技术内幕:Shuffle的性能调优
通过上面的架构和源码实现的分析,不难得出Shuffle是Spark Core比较复杂的模块的结论.它也是非常影响性能的操作之一.因此,在这里整理了会影响Shuffle性能的各项配置.尽管大部分的配置项 ...
- 【Spark调优】Shuffle原理理解与参数调优
[生产实践经验] 生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍. [Shuffle原理学习笔记] 1.未经优化的HashSh ...
- Spark性能优化:shuffle调优
调优概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行 ...
- Add, remove, shuffle and sort
To deal cards, we would like a method that removes a card from the deck and returns it. The list met ...
- Partitioning, Shuffle and sort
Partitioning, Shuffle and sort what happened? - Partitioning Partitioning is the process of determi ...
- Hadoop-2.2.0中文文档—— MapReduce下一代- 可插入的 Shuffle 和 Sort
简单介绍 可插入的 shuffle 和 sort 功能,同意在shuffle 和 sort 逻辑中用可选择的实现类替换.这个情况的样例是:用一个不是HTTP的应用协议,如RDMA来 shuffle 从 ...
- shuffle和sort分析
MapReduce中的Shuffle和Sort分析 MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据.第一个提出该技术框架的是Google 公司,而Google 的 ...
随机推荐
- Delphi写的DLL,OCX中多线程一个同步问题
Delphi写的DLL,OCX中如果使用了TThread.Synchronze(Proc),可能导致线程死锁,原因是无法唤醒EXE中主线程, Synchronze并不会进入EXE主线程消息队列. 下面 ...
- 数构与算法 | 什么是大 O 表示算法时间复杂度
正文: 开篇我们先思考这么一个问题:一台老式的 CPU 的计算机运行 O(n) 的程序,和一台速度提高的新式 CPU 的计算机运 O(n2) 的程序.谁的程运行效率高呢? 答案是前者优于后者.为什么呢 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- 20155316 2016-2017-2 《Java程序设计》第3周学习总结
教材学习内容总结 类:创建类.使用类 基本类类型与类类型 数组 封装的概念 重载 类语法 static成员 教材学习中的问题和解决过程 1.既然数组在JAVA中就是对象,那么int[] 是否是一个类呢 ...
- c++ 全局变量
一.全局变量 声明 全局变量的定义和一般变量定义相同,不同的就是它的位置.一般会放在所有共享函数的前边. 作用 在函数间共享数据. 二.全局变量的运用 三.作业: 写出代码运行结果: ; //0 in ...
- 深度学习开源库tiny-dnn的使用(MNIST)
tiny-dnn是一个基于DNN的深度学习开源库,它的License是BSD 3-Clause.之前名字是tiny-cnn是基于CNN的,tiny-dnn与tiny-cnn相关又增加了些新层.此开源库 ...
- day5 RHCE
19 .配置 iSCSI 服务端 (***先做这个题目**,挂载重启,机器会挂掉) 配置server0提供一个iSCSI服务磁盘名为iqn.2014-11.com.example:server0,并 ...
- 【BZOJ4560】[NOI2016]优秀的拆分
[BZOJ4560][NOI2016]优秀的拆分 题面 bzoj 洛谷 题解 考虑一个形如\(AABB\)的串是由两个形如\(AA\)的串拼起来的 那么我们设 \(f[i]\):以位置\(i\)为结尾 ...
- Zabbix学习之路(一)之Zabbix安装
一.Zabbix环境准备 [root@linux-node1 ~]# cat /etc/redhat-release CentOS Linux release (Core) [root@linux-n ...
- VBA_常用VBA代码
'批量替换字符 Sub Test() Dim i As Integer ).Value = "已激活" Then Cells(i, ).Value = "Active&q ...