Python 爬虫实例(13) 下载 m3u8 格式视频
Python requests 下载 m3u8 格式 视频
最近爬取一个视频网站,遇到 m3u8 格式的视频需要下载。
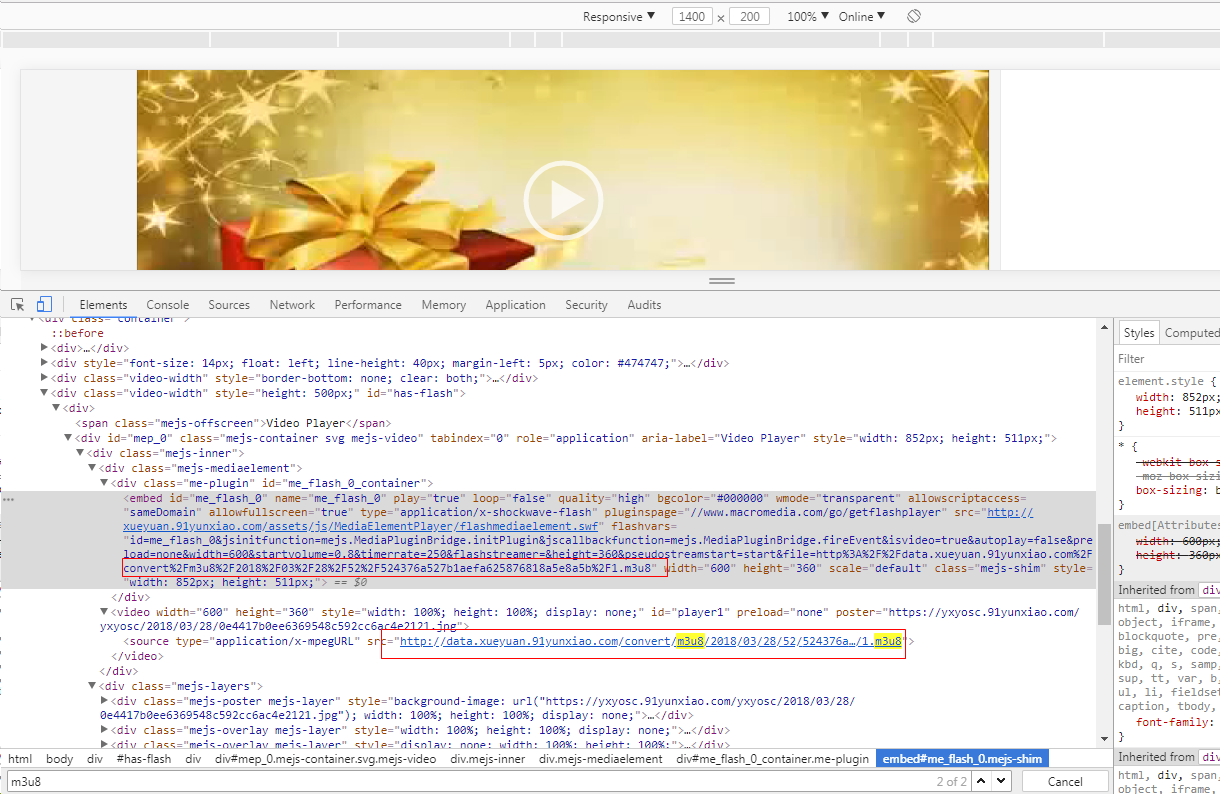
抓包分析,视频文件是多个 ts 文件,什么是 ts文件,请去百度吧:
附图:抓包分析过程
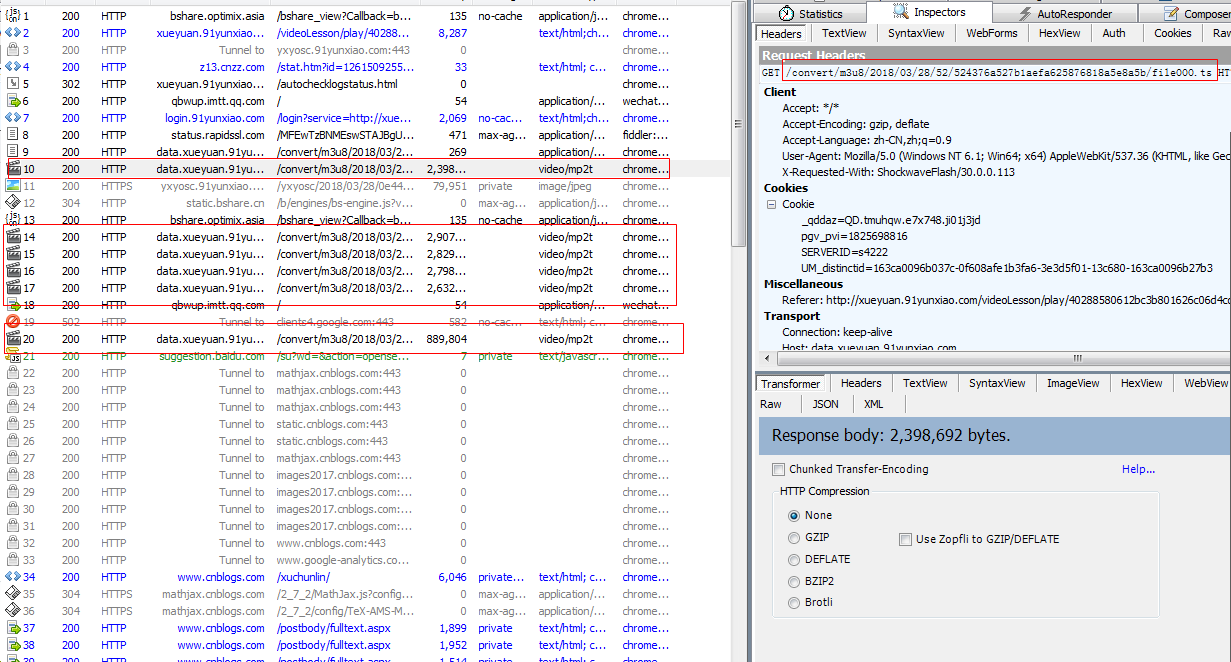
直接把 ts文件请求下来,然后合并 ts文件,如果想把 ts文件转换 MP4 格式,请自行百度吧。
完整下载代码:
#coding=utf-8
import requests
import re
import time
from bs4 import BeautifulSoup
import os session = requests.session() def spider():
url = 'http://xueyuan.91yunxiao.com/videoLesson/play/4028e4115fc893fb015fecfc56240b66.html'
headers = { "Host":"xueyuan.91yunxiao.com",
"Connection":"keep-alive",
"Upgrade-Insecure-Requests":"",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer":"http://xueyuan.91yunxiao.com/videoLesson/detail/4028e4115fc893fb015fecfafe200b63.html",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cookie":"UM_distinctid=163cae8de9816e-0d08a36800162a-454c092b-ff000-163cae8de99141; _qddaz=QD.n4xqjl.egbt1i.ji0ex7zv; pgv_pvi=6411171840; SERVERID=s50; JSESSIONID=5D1C6375394E84E931FBD1C774876563; CNZZDATA1261509255=2100416221-1528114457-%7C1528207774", } try:
result = session.get(url=url,headers=headers).content except:
result = session.get(url=url,headers=headers).content result_replace = str(result).replace('\n','')
print result_replace
item_url = re.findall('<source type="application/x-mpegURL" src="(.*?)" />',result_replace)[0].replace('1.m3u8','')
print item_url # for page in range(1,11): headers2 = { "Host":"data.xueyuan.91yunxiao.com",
"Connection":"keep-alive",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"X-Requested-With":"ShockwaveFlash/29.0.0.171",
"Accept":"*/*",
"Referer":"http://xueyuan.91yunxiao.com/videoLesson/play/4028e4115fc893fb015fecf8e4d60b61.html",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cookie":"UM_distinctid=163cae8de9816e-0d08a36800162a-454c092b-ff000-163cae8de99141; _qddaz=QD.n4xqjl.egbt1i.ji0ex7zv;
pgv_pvi=6411171840; SERVERID=s4222", } for page in range(0,16): if page < 10:
page_str = "" + str(page)
else:
page_str = str(page) "http://data.xueyuan.91yunxiao.com/convert/m3u8/2017/11/24/ed/ededf4dc7471a05550cc521196d28ebc/file006.ts"
item_url1 = item_url + "file0" + str(page_str) + ".ts"
print item_url1 dir_path = "E:/1"
file_name = page_str + ".ts"
response = session.get(url=item_url1,headers=headers2) if response.status_code == 200:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
total_path = dir_path + '/' + file_name
if len(response.content) == int(response.headers['Content-Length']):
# print total_path
with open(total_path, 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
f.close() spider()
Python 爬虫实例(13) 下载 m3u8 格式视频的更多相关文章
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Vue中如何插入m3u8格式视频,3分钟学会!
大家都知道video只支持ogg.webm.MP4格式,但是要是m3u8格式的视频怎么办?最近遇到这个问题在网上找了好多办法都不行,最后找到video.js后才完美解决,所以决定写一 ...
- 前端播放m3u8格式视频
一.前端播放m3u8格式视频 <!DOCTYPE html> <html lang="zh-CN"> <head> <meta chars ...
- python爬虫实例大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
- python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>> 爬取酷狗歌单,保存入csv文件 直接上源代码:(含注释) import requests #用于请求网页获取网页数据 from b ...
- 在vue项目中播放m3u8格式视频
前言:最近公司在做一个线上会议的项目,要求后台网站播放m3u8格式的视频,查找部分资料,总结一下,方便后边查阅 1.在vue工程中安装以下依赖: cnpm install video.js --sa ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
随机推荐
- ES6学习笔记十:模块的导入、导出
一:模块导入 1) import { 要导入的属性.方法民 } from '模块路径'; 2)该种方法需要有配置文件,指明模块所在路径 import { 要导入的属性.方法民 } from '模块名' ...
- EF Code First导航属性一对一关系中注意点及配置方法
//学生 public class Student { [key] public int StId { get; set; } public int SocialSecurityNumber { ge ...
- quartz.net 的配置文件资料
java版本的文档比较全 http://www.quartz-scheduler.org/documentation/quartz-2.x/configuration/ConfigPlugins.ht ...
- java服务端微信小程序支付
发布时间:2018-10-05 技术:springboot+maven 概述 java微信小程序demo支付只需配置支付一下参数即可运行 详细 代码下载:http://www.demodash ...
- (原+译)使用numpy.savez保存字典后读取的问题
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/7608928.html 参考网址; https://stackoverflow.com/question ...
- [抄]OKR
OKR是Objective Key Result KPI是KeyPointIndicator OKR概览 OKR是一个目标管理工具.即目标与关键成果法,是一套明确和跟踪目标及其完成情况的管理工具和方法 ...
- iOS 批量打包
如果你曾经试过做多 target 的项目,到了测试人员要测试包的时候,你就会明白什么叫“生不如死”.虽然 Xcode 打包很方便,但是当你机械重复打 N 次包的时候,就会觉得这纯粹是浪费时间的工作.所 ...
- ReactiveCocoa 中 RACSignal 是怎样发送信号
前言 ReactiveCocoa是一个(第一个?)将函数响应式编程范例带入Objective-C的开源库.ReactiveCocoa是由Josh Abernathy和Justin Spahr-Summ ...
- Ant scp upload文件至linux server(用java调用Ant api)
1.要准备的jar包:ant.jar,ant-jsch.jar code: package com.test.utils; import org.apache.tools.ant.Project; i ...
- 【SqlServer】SqlServer索引的创建、查看、删除
索引加快检索表中数据的方法,它对数据表中一个或者多个列的值进行结构排序,是数据库中一个非常有用的对象. 索引的创建 #1使用企业管理器创建 启动企业管理器--选择数据库------选在要创建索引的表- ...