Python 爬虫实例(13) 下载 m3u8 格式视频
Python requests 下载 m3u8 格式 视频
最近爬取一个视频网站,遇到 m3u8 格式的视频需要下载。
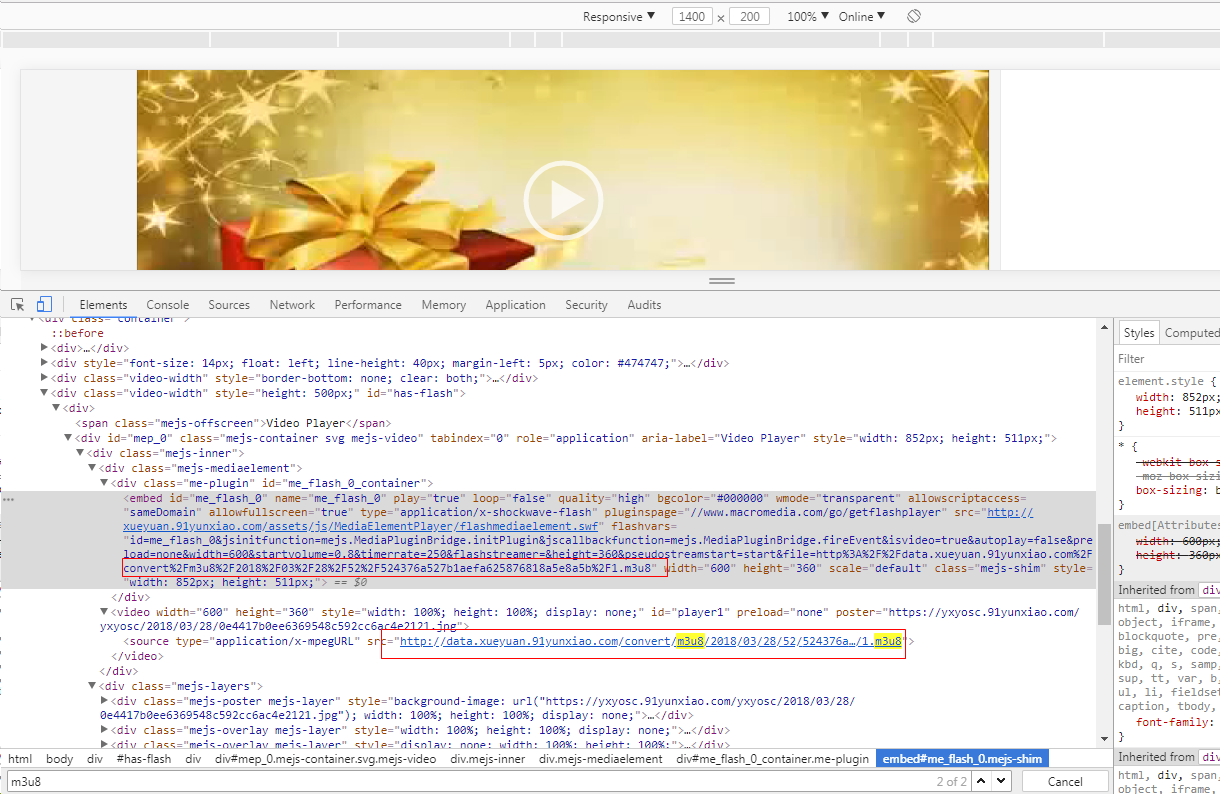
抓包分析,视频文件是多个 ts 文件,什么是 ts文件,请去百度吧:
附图:抓包分析过程
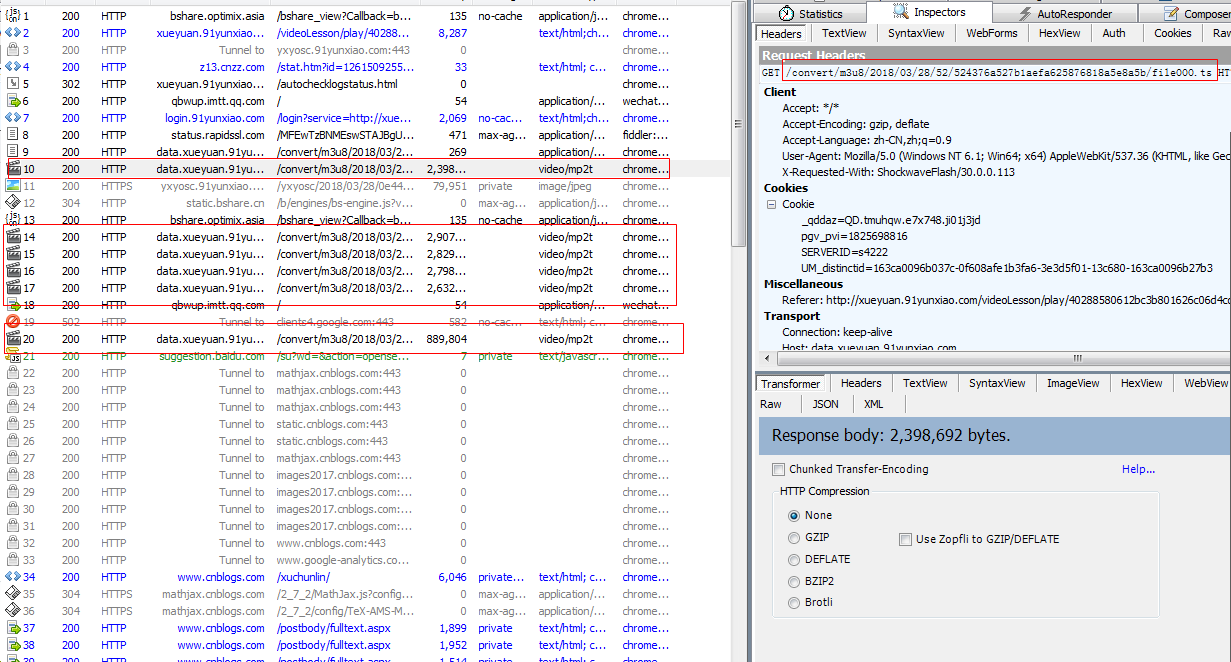
直接把 ts文件请求下来,然后合并 ts文件,如果想把 ts文件转换 MP4 格式,请自行百度吧。
完整下载代码:
#coding=utf-8
import requests
import re
import time
from bs4 import BeautifulSoup
import os session = requests.session() def spider():
url = 'http://xueyuan.91yunxiao.com/videoLesson/play/4028e4115fc893fb015fecfc56240b66.html'
headers = { "Host":"xueyuan.91yunxiao.com",
"Connection":"keep-alive",
"Upgrade-Insecure-Requests":"",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Referer":"http://xueyuan.91yunxiao.com/videoLesson/detail/4028e4115fc893fb015fecfafe200b63.html",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cookie":"UM_distinctid=163cae8de9816e-0d08a36800162a-454c092b-ff000-163cae8de99141; _qddaz=QD.n4xqjl.egbt1i.ji0ex7zv; pgv_pvi=6411171840; SERVERID=s50; JSESSIONID=5D1C6375394E84E931FBD1C774876563; CNZZDATA1261509255=2100416221-1528114457-%7C1528207774", } try:
result = session.get(url=url,headers=headers).content except:
result = session.get(url=url,headers=headers).content result_replace = str(result).replace('\n','')
print result_replace
item_url = re.findall('<source type="application/x-mpegURL" src="(.*?)" />',result_replace)[0].replace('1.m3u8','')
print item_url # for page in range(1,11): headers2 = { "Host":"data.xueyuan.91yunxiao.com",
"Connection":"keep-alive",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"X-Requested-With":"ShockwaveFlash/29.0.0.171",
"Accept":"*/*",
"Referer":"http://xueyuan.91yunxiao.com/videoLesson/play/4028e4115fc893fb015fecf8e4d60b61.html",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cookie":"UM_distinctid=163cae8de9816e-0d08a36800162a-454c092b-ff000-163cae8de99141; _qddaz=QD.n4xqjl.egbt1i.ji0ex7zv;
pgv_pvi=6411171840; SERVERID=s4222", } for page in range(0,16): if page < 10:
page_str = "" + str(page)
else:
page_str = str(page) "http://data.xueyuan.91yunxiao.com/convert/m3u8/2017/11/24/ed/ededf4dc7471a05550cc521196d28ebc/file006.ts"
item_url1 = item_url + "file0" + str(page_str) + ".ts"
print item_url1 dir_path = "E:/1"
file_name = page_str + ".ts"
response = session.get(url=item_url1,headers=headers2) if response.status_code == 200:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
total_path = dir_path + '/' + file_name
if len(response.content) == int(response.headers['Content-Length']):
# print total_path
with open(total_path, 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
f.close() spider()
Python 爬虫实例(13) 下载 m3u8 格式视频的更多相关文章
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Vue中如何插入m3u8格式视频,3分钟学会!
大家都知道video只支持ogg.webm.MP4格式,但是要是m3u8格式的视频怎么办?最近遇到这个问题在网上找了好多办法都不行,最后找到video.js后才完美解决,所以决定写一 ...
- 前端播放m3u8格式视频
一.前端播放m3u8格式视频 <!DOCTYPE html> <html lang="zh-CN"> <head> <meta chars ...
- python爬虫实例大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
- python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>> 爬取酷狗歌单,保存入csv文件 直接上源代码:(含注释) import requests #用于请求网页获取网页数据 from b ...
- 在vue项目中播放m3u8格式视频
前言:最近公司在做一个线上会议的项目,要求后台网站播放m3u8格式的视频,查找部分资料,总结一下,方便后边查阅 1.在vue工程中安装以下依赖: cnpm install video.js --sa ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
随机推荐
- web ide
https://www.jianshu.com/p/339dff3da1fa https://www.eclipse.org/che/ https://github.com/Coding/WebIDE ...
- 【Zookeeper】源码分析之序列化
一.前言 在完成了前面的理论学习后,现在可以从源码角度来解析Zookeeper的细节,首先笔者想从序列化入手,因为在网络通信.数据存储中都用到了序列化,下面开始分析. 二.序列化 序列化主要在zook ...
- Dwr 框架简单实例
Dwr 是一个 Java 开源库,帮助你实现Ajax网站. 它可以让你在浏览器中的Javascript代码调用Web服务器上的Java,就像在Java代码就在浏览器中一样. Dwr 主要包括两部分: ...
- Maven的坐标与资源库
在Maven世界中,每个工程都有它唯一的 组织名.模块名.版本 ,这三个就是maven项目的坐标,一个maven工程可以打包成jar.war.pom等形式,但是它们都是拥有上述三个坐标的.我们在项目过 ...
- JSP页面跳转之sendRedirect()与forward()辨析
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/6044817.html 在JSP中,要实现页面的跳转,主要有两种方式实现:forward和sendRedire ...
- oracle的参数文件:pfile和spfile
1.pfile和spfile Oracle中的参数文件是一个包含一系列参数以及参数对应值的操作系统文件.它们是在数据库实例启动时候加载的,决定了数据库的物理 结构.内存.数据库的限制及系统大量的默认值 ...
- 【AIX】在命令前显示完整路径
登录到AIX系统,发现在#前没有目录展示,这样我们在查看当前目前时很不方便,需要借助命令PWD才可以实现 解决方案: 在.profile文件中添加命令:export PS1="[LONGNA ...
- python 测试时一个str是不是字符串
# -*- coding: cp936 -*- #python 27 #xiaodeng #测试时一个str是不是字符串 def isAstring(obj): ''' 测试一个str是不是字符串 b ...
- Redis C客户端Hiredis代码分析
初始化 redisContext - Redis连接的上下文 /* Context for a connection to Redis */ typedef struct redisContext { ...
- Ubuntu x86-64汇编(1)
x86-64 Assembly Language Programming with Ubuntu 的读书记录 x86计算机体系架构 架构总览 CPU, RAM, 存储, 输入输出设备等, 数据的尺寸( ...