zabbix LLD 自定义脚本
一 前言
二 懒人必备zabbix监控之 LLD (low level discovery)
本次的教程是我想监控kafka的消费情况,举个栗子
[root@VM_0_98_centos bin]# ./kafka-consumer-groups.sh --bootstrap-server 172.20.150.1:9092 --describe --group ee TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
ee_172_20_50 0 93864 93864 0 ee-0-213a104f-f2b7-490d-80cd-a4e391f292ab /172.20.150.1 ee-0
ee_172_20_25 0 592471 592480 9 ee-0-213a104f-f2b7-490d-80cd-a4e391f292ab /172.20.150.1 ee-0
ee_172_20_19 0 156781 156781 0 ee-0-213a104f-f2b7-490d-80cd-a4e391f292ab /172.20.150.1 ee-0
ee_172_20_26 0 1345 1345 0 ee-0-213a104f-f2b7-490d-80cd-a4e391f292ab /172.20.150.1 ee-0
ee_172_20_22 0 197724 197747 23 ee-0-213a104f-f2b7-490d-80cd-a4e391f292ab /172.20.150.1 ee-0
ee_172_20_23 0 147067 147067 0 ee-0-213a104f-f2b7-490d-80cd-a4e391f292ab /172.20.150.1 ee-0
ee_172_20_24 0 620405 620406 1 ee-0-213a104f-f2b7-490d-80cd-a4e391f292ab /172.20.150.1 ee-0
ee_172_20_21 0 7883826 7883828 2 ee-0-213a104f-f2b7-490d-80cd-a4e391f292ab /172.20.150.1 ee-0
ee_scm 0 205365 205365 0 - - - 说明: 红色部分表示表示消费的个数,黄色部分为生产的个数,绿色部分为剩余多少个
这个够直接了吧,先说一下为啥使用LLD 呢,这个先不解释。看完你应该会明白吧,如果不明白,就跟着耍一遍,应该就明白了
1 zabbix_agent 端配置
[root@VM_0_98_centos ~]# cat /opt/zabbix_agent/conf/zabbix_agentd.conf
PidFile=/opt/zabbix_agent/pids/zabbix_agentd.pid
LogFile=/opt/zabbix_agent/logs/zabbix_agentd.log
LogFileSize=0
AllowRoot=1
# StartAgents=0
Server=zabbix-server_IP
ServerActive=zabbix-server_IP
Hostname=VM_0_98_centos_zabbix-agent_IP
Include=/opt/zabbix_agent/conf/zabbix_agentd/*.conf
UnsafeUserParameters=1
HostMetadataItem=system.uname
HostMetadata=ee_mq
Timeout=30
在总的配置文件中定义导入其他配置文件,这里说一下为啥需要分配置文件,因为我觉得清爽,没啥理由。如果硬要给一个理由就是,我喜欢这样,好吧,我承认这样非常方便管理
[root@VM_0_98_centos zabbix_agentd]# ll
total 20
-rwxr-xr-x 1 zabbix zabbix 173 Mar 12 11:11 java_process.conf
-rw-r--r-- 1 root root 180 Mar 15 11:47 kafka.conf
-rwxr-xr-x 1 zabbix zabbix 75 Mar 8 17:11 tcp_conn_status.conf
看到没,我分配了很多配置文件,每个文件对应前端一个模板,脚本中的一个或者几个脚本。这样管理起来非常的方便。如果不分开,后期维护的人会非常恨你。曾经听说一个程序员因不满其他四个同事的做事风格把他们四个枪毙了,你看着办吧
[root@VM_0_98_centos zabbix_agentd]# cat kafka.conf
UserParameter=kafka.discovery,sudo python /opt/zabbix_agent/scripts/kafka/get_kafka.py
UserParameter=kafka.data[*],sudo python /opt/zabbix_agent/scripts/kafka/get_data.py $1 $2 $3
脚本一共三个文件
[root@VM_0_98_centos kafka]# ll
total 12
-rwxr-xr-x 1 root root 2526 Mar 15 11:42 get_data.py
-rwxr-xr-x 1 zabbix zabbix 2279 Mar 15 11:32 get_kafka.py
-rw-r--r-- 1 zabbix zabbix 18 Mar 14 16:47 kafka_monitor.yaml
1)先来看看配置文件中是啥kafka_monitor.yaml
[root@VM_0_98_centos kafka]# cat kafka_monitor.yaml
groups:
ee
ng
没错,就是你logstash中自己定义的group
2)先看get_kafka.py 中是干啥的呢?
#!/usr/bin/env python
# coding:utf-8 import yaml
import os
import sys
import subprocess
import re
import time
import json # ./kafka-consumer-groups.sh --bootstrap-server 172.20.150.1:9092 --describe --group ee class KafkaMonitor(object):
def __init__(self):
self.bootstrap_server = "172.20.150.1:9092"
self.cmd = "/opt/kafka/kafka_2.12-2.1.0/bin/kafka-consumer-groups.sh" try:
f = file(os.path.dirname(os.path.abspath(__file__)) + '/' + 'kafka_monitor.yaml')
self.groups = yaml.load(f)
except IOError as e:
print 'Error, kafka_monitor.yaml is not found'
sys.exit(1)
else:
f.close()
if self.groups is None:
self.groups = {}
print 'Error, kafka_monitor.yaml content is empty'
sys.exit(2) def run(self):
self.result_list = []
for self.group in self.groups.values()[0].split():
self.cmd_run = "%s --bootstrap-server %s --describe --group %s | egrep -v 'TOPIC|^$'" % (
self.cmd, self.bootstrap_server, self.group)
subp = subprocess.Popen(self.cmd_run, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
self.datas_list = subp.stdout.readlines()
self.result_dict = {}
for data_list in self.datas_list:
data_list = data_list.strip().split()
# self.result_data = {'datetime': time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'topic': data_list[0],
# 'group': self.arg1, 'partition': int(data_list[1]), 'logsize': data_list[2],
# 'offset': int(data_list[3]), 'lag': data_list[4]}
# self.result_data = {"{#GROUPNAME}": self.arg1,"{#TOPICNAME}": data_list[0],
# "{#LOGSIZE}": int(data_list[2]),"{#OFFSET}":int(data_list[3]),"{#LAG}": int(data_list[4])}
self.result_data = {"{#GROUPNAME}": self.group,"{#TOPICNAME}": data_list[0]}
self.result_list.append(self.result_data) print json.dumps({"data": self.result_list},sort_keys=True,indent=4) if __name__ == "__main__":
client = KafkaMonitor()
client.run()
也没啥,就是读取刚才的kafka_monitor.yaml 的配置文件,然后执行一条指令。就是开始的那个指令,获取一些你想要的数据,然后清洗一下格式,得到你想要的结果。用官方的话说就是 kafka_monitor.yaml是输入---> 处理 ---> 得到你想要的结果。
看看结果是啥吧
[root@VM_0_98_centos kafka]# python get_kafka.py
{
"data": [
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "mqtt_110_2"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_50"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_25"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_19"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_26"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_22"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_23"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_24"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_21"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "personal_income_tax_172_20_20"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "personal_income_tax_172_20_28"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "personal_income_tax_172_20_27"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "personal_income_tax_172_20_26"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_scm"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "personal_income_tax_nginx_access_172_20_28"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "personal_income_tax_nginx_error_172_20_20"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "personal_income_tax_nginx_access_172_20_20"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "personal_income_tax_nginx_error_172_20_28"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "nginx_error"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "nginx_access"
}
]
}
没错,就是groupname和topicname,具体为啥是这种格式,zabbix规定的吧。其中 {#GROUPNAME}和{#TOPICNAME}可以在zabbix-server前端配置页中看做是 宏变量
3)看一下第三个脚本吧get_data.py
这个是干啥的呢,就是你给我
#!/usr/bin/env python
# coding:utf-8 import yaml
import os
import sys
import subprocess
import re
import time
import json # ./kafka-consumer-groups.sh --bootstrap-server 172.20.150.1:9092 --describe --group ee class KafkaMonitor(object):
def __init__(self):
self.group_name = sys.argv[1]
self.topic_name = sys.argv[2]
self.data_type = sys.argv[3]
self.bootstrap_server = "172.20.150.1:9092"
self.cmd = "/opt/kafka/kafka_2.12-2.1.0/bin/kafka-consumer-groups.sh" try:
f = file(os.path.dirname(os.path.abspath(__file__)) + '/' + 'kafka_monitor.yaml')
self.groups = yaml.load(f)
except IOError as e:
print 'Error, kafka_monitor.yaml is not found'
sys.exit(1)
else:
f.close()
if self.groups is None:
self.groups = {}
print 'Error, kafka_monitor.yaml content is empty'
sys.exit(2) def run(self):
self.result_list = []
for self.group in self.groups.values()[0].split():
self.cmd_run = "%s --bootstrap-server %s --describe --group %s | egrep -v 'TOPIC|^$'" % (
self.cmd, self.bootstrap_server, self.group)
subp = subprocess.Popen(self.cmd_run, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
self.datas_list = subp.stdout.readlines()
self.result_dict = {}
for data_list in self.datas_list:
data_list = data_list.strip().split()
if self.group_name == self.group and self.topic_name == data_list[0]:
if self.data_type == "offset":
print int(data_list[3])
elif self.data_type == "logsize":
print int(data_list[2])
else:
print int(data_list[4]) # self.result_data = {'datetime': time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'topic': data_list[0],
# 'group': self.arg1, 'partition': int(data_list[1]), 'logsize': data_list[2],
# 'offset': int(data_list[3]), 'lag': data_list[4]}
# self.result_data = {"{#GROUPNAME}": self.arg1,"{#TOPICNAME}": data_list[0],
# "{#LOGSIZE}": int(data_list[2]),"{#OFFSET}":int(data_list[3]),"{#LAG}": int(data_list[4])} if __name__ == "__main__":
client = KafkaMonitor()
client.run()
以供接收三个参数,groupname和topname,data_type(lag/offset/logsize) 然后输出一个值,看一下执行结果吧
[root@VM_0_98_centos kafka]# python get_data.py ee personal_income_tax_172_20_26 lag
0
看到了吧。执行有点慢,到了这步之后,你就可以重启你的zabbix_agent了
2 zabbix-server 测试
[root@VM_4_84_centos ~]# zabbix_get -s 172.20.150.1 -p 10050 -k kafka.discovery
{
"data": [
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "mqtt_110_2"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_50"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_25"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_19"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_26"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_22"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_23"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_24"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_172_20_21"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "personal_income_tax_172_20_20"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "personal_income_tax_172_20_28"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "personal_income_tax_172_20_27"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "personal_income_tax_172_20_26"
},
{
"{#GROUPNAME}": "ee",
"{#TOPICNAME}": "ee_scm"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "personal_income_tax_nginx_access_172_20_28"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "personal_income_tax_nginx_error_172_20_20"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "personal_income_tax_nginx_access_172_20_20"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "personal_income_tax_nginx_error_172_20_28"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "nginx_error"
},
{
"{#GROUPNAME}": "ng",
"{#TOPICNAME}": "nginx_access"
}
]
}
[root@VM_4_84_centos ~]# zabbix_get -s 172.20.150.1 -p 10050 -k kafka.data[ng,personal_income_tax_nginx_access_172_20_20,lag]
15
看到了吧,是不是很简单
3 zabbix-server 页面配置

1)看图吧
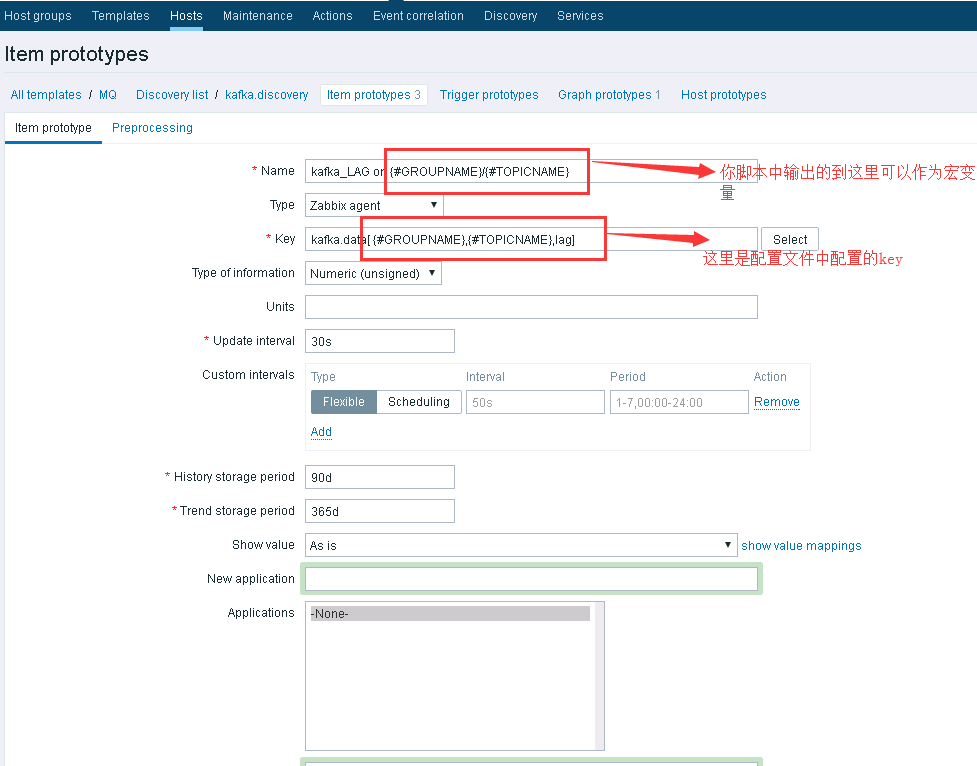
看图吧
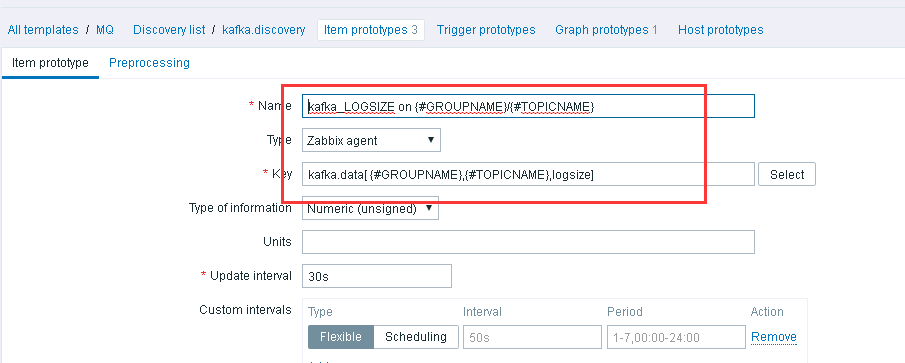
还是看图吧哈哈

2)搞个图出来吧
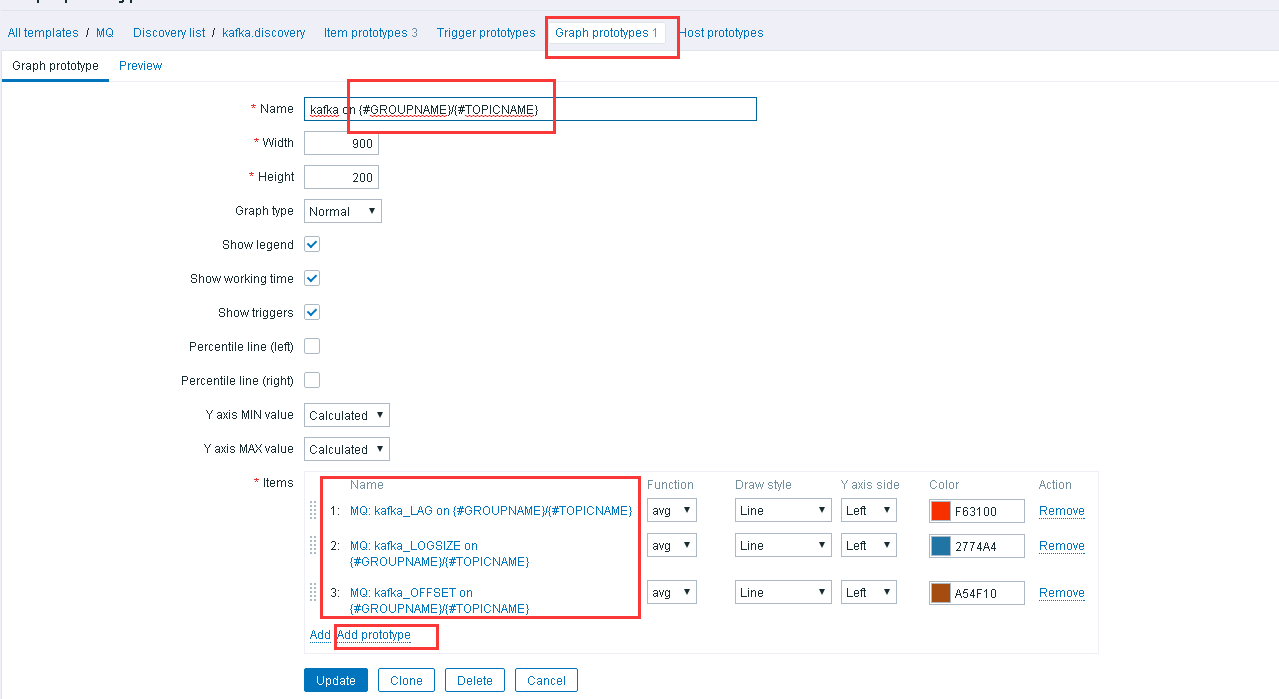
然后应用到你的主机就可以啦。
现在说说为啥这种情况,我选择了LLD呢,因为我的topicname非常多,我不想自己配置,后期还是不断的增加,我也不想配置。那这种LLD的方式可以满足你,这里需要注意一点的是,如果你的组增加了,需要在配置文件中 kafka_monitor.yaml 加上就可以了。
所谓的自动化,我的理解就是想法设法的偷懒,并且标准化的环境,高效的执行,你只需要看着他执行就行了。
写在最后,祝愿天下所有有情人终成眷属
zabbix LLD 自定义脚本的更多相关文章
- zabbix使用自定义脚本监控内存
我这里的脚本是监控centos7系统的内存.centos7系统的内存如何查看我之前的博客都是有的.这里直接写了监控步骤 1.首先是编写脚本. #!/bin/bash mem_total(){ TOTA ...
- zabbix 获取不到自定义脚本的值解决
agent端: zabbix 自定义脚本 [root@localhost script]# cat check_ping.sh #!/bin/bash result=$(/usr/local/nagi ...
- Zabbix的通知功能以及自定义脚本告警
本节内容: Zabbix的通知功能 定义接收告警的用户 定义Action Zabbix自定义脚本发送报警邮件 一.Zabbix的通知功能 在配置好监控项和触发器之后,一旦正常工作中的某触发器状态发生改 ...
- zabbix 自定义脚本监控activemq
1. 编写获取activemq队列积压消息(check-amq.sh) #!/bin/bash QUEUENAME=$ MQ_IP='172.16.1.56' curl -uadmin:admin h ...
- (48)zabbix报警媒介:自定义脚本Custom alertscripts
自定义脚本媒介.zabbix会将信息传递给脚本,接下来你在脚本里面随意处理,一共会传递三个参数,按顺序接受也就是$1,$2,$3了,为了方便记忆,一般分别给他们赋值到To\Subject\body 配 ...
- zabbix自定义脚本监控服务器端口状态
zabbix可以通过客户端的[net.tcp.port[<ip>,port]]该item监控项来判断本地/远程服务器TCP端口是否正常,不过当时没有想起来,就用了自定义脚本去写的,很久没有 ...
- [系统集成] RT(Request Tracker)执行自定义脚本及发送微信、短信的实现方法
RT(Request Tracker)是一个基于 Perl 语言的开源状态跟踪和工作流系统,支持审批.权限管理等功能,中文化支持的也不错,可以作为企业的流程审批系统使用.可惜的是,该系统在国内使用的不 ...
- 自学Zabbix11.6 Zabbix SNMP自定义OID
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 自学Zabbix11.6 Zabbix SNMP自定义OID 为什么要自定义OID? 前面已经讲过 ...
- zabbix使用自定义key进行监控
我的zabbix-server是安装在另一台虚拟机上的,用来监控下图中的这台虚拟机 先修改zabbix的客户端配置文件,增加UserParameter那行,这里我只是用来测试,所以就随便起了一个名为p ...
随机推荐
- jquery插件--问题类(新增&&删除)简易版
HTML: <!doctype html> <head> <meta charset="utf-8" /> <script src=&qu ...
- python字符串、列表和文件对象总结
1.字符串是字符序列.字符串文字可以用单引号或者双引号分隔. 2.可以用内置的序列操作来处理字符串和列表:连接(+).重复(*).索引([]),切片([:])和长度(len()).可以用for循环遍历 ...
- SQL语句 查询同一个字符在某一个字符串中出现的次数
select len(replace(字段名A,';','--'))-len(字段名A) from table表名
- 【附5】springboot之配置文件
本文转载自http://www.jianshu.com/p/80621291373b,作者:龙白一梦 我的boss 代码从开发到测试要经过各种环境,开发环境,测试环境,demo环境,线上环境,各种环境 ...
- C# 获取SQL Server所有的数据库名称
参考文章:http://www.cnblogs.com/Abel_cn/archive/2008/12/09/1351425.html http://blog.csdn.net/friendan/ar ...
- FAST:通过Floodlight控制器下发流表
参考: Floodlight+Mininet搭建OpenFlow(四):流表操作 通过Floodlight控制器下发流表 下发流表的方式有两种: 1.借助Floodlight的北向API,利用curl ...
- UVa 1605 联合国大楼
https://vjudge.net/problem/UVA-1605 题意:有n个国家,要求设计一栋楼并为这n个国家划分房间,要求国家的房间必须连通,且每两个国家之间必须有一间房间是相邻的. 思路: ...
- python学习站点
1.python 外部扩展网址 http://www.lfd.uci.edu/~gohlke/pythonlibs Python Extension Packages 2.web2py学习 http: ...
- shell 脚本中所有循环语法
写出 shell 脚本中所有循环语法 for 循环 : for i in $(ls);do echo item:$i done while 循环 : #!/bin/bash COUNTER=0 whi ...
- python中sys.stdout、sys.stdin
如果需要更好的控制输出,而print不能满足需求,sys.stdout,sys.stdin,sys.stderr就是你需要的. 1. sys.stdout与print: 在python中调用print ...