hadoop部署安装(二)hdfs
2.1 解压Hadop包
2.2 配置hadoop-env.sh文件
[root@master ~]# cd /usr/local
[root@master local]# tar xf hadoop-3.2.0.tar.gz
[root@master local]# mv hadoop-3.2.0 hadoop
[root@master local]# cd hadoop
[root@master hadoop]# vim etc/hadoop/hadoop-env.sh
修改:
export JAVA_HOME=/usr/local/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=yarn
export YARN_NODEMANAGER_USER=root
2.3 配置core-site.xml文件
[root@master hadoop]# vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///usr/local/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
2.4 配置hdfs-site.xml文件
[root@master hadoop]# vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
2.5 配置slave文件
[root@master hadoop]# vim etc/hadoop/workers
添加:
master
slave1
slave2
2.6 将master节点配置同步其他主机
scp -rp /usr/local/hadoop/ slave1:/usr/local/
scp -rp /usr/local/hadoop/ slave2:/usr/local/
scp -rp /usr/local/hadoop/ slave3:/usr/local/
2.7 修改环境配置文件
vim /etc/profile
添加:
#Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
#mysql
export PATH=$PATH:/usr/local/mysql-5.6/bin
#hive
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
#spark
export SPARK_HOME=/usr/local/spark
export PATH=${SPARK_HOME}/bin:$PATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
#zookeeper
export PATH=$PATH:/usr/local/zookeeper/bin
#scala
export SCALA_HOME=/usr/local/scala
export PATH=${SCALA_HOME}/bin:$PATH
[root@master ~]# scp -rp /etc/profile slave1:/etc/profile
[root@master ~]# scp -rp /etc/profile slave2:/etc/profile
2.8 格式化hdfs文件系统
[root@master ~]# hdfs namenode -format
格式化hdfs的namenode节点,产生定义的hdfs_tmp目录
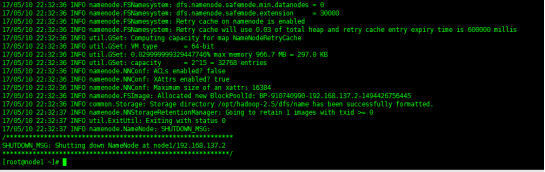
查看是否生成fsimage文件,验证hdfs格式化是否成功

2.9 启动hadoop集群
[root@master ~]# start-dfs.sh
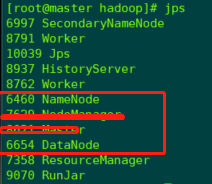
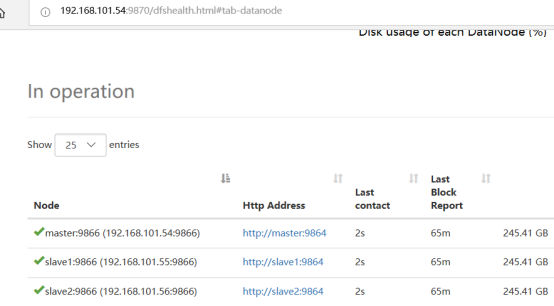
2.10 验证hadoop集群
登录http://192.168.101.54:9870
2.11 关闭hadoop集群
[root@master ~]# stop-dfs.sh
注意yarn服务需要运行zookeeper。
hadoop部署安装(二)hdfs的更多相关文章
- Hadoop集群(二) HDFS搭建
HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS展开的.所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始. 安装Hadoop集群,首先需要有Zookeeper ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- Hadoop的安装与部署
一.硬件及环境 服务器:3台,IP分别为:192.168.100.105.192.168.100.110.192.168.100.115 操作系统:Ubuntu Server 18.04 JDK:1. ...
- Hadoop 2.2.0部署安装(笔记,单机安装)
SSH无密安装与配置 具体配置步骤: ◎ 在root根目录下创建.ssh目录 (必须root用户登录) cd /root & mkdir .ssh chmod 700 .ssh & c ...
- [转]HDFS HA 部署安装
1. HDFS 2.0 基本概念 相比于 Hadoop 1.0,Hadoop 2.0 中的 HDFS 增加了两个重大特性,HA 和 Federaion.HA 即为 High Availability, ...
- hadoop的安装和配置(二)伪分布模式
博主会用三篇文章为大家详细的说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 伪分布式模式: 这篇为大家带来hadoop的伪分布模式: 从最简单的方面来说,伪分布模式就是在本地模式上修 ...
- Hadoop系列(二):Hadoop单节点部署
环境:CentOS 7 JDK: 1.7.0_80 hadoop:2.8.5 hadoop(192.168.56.101) 配置基础环境 1. 测试环境可以直接关闭selinux和防火墙 2. 主机添 ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- Hadoop 系列(二)安装配置
Hadoop 系列(二)安装配置 Hadoop 官网:http://hadoop.apache.or 一.Hadoop 安装 1.1 Hadoop 依赖的组件 JDK :从 Oracle 官网下载,设 ...
- HADOOP docker(二):HDFS 高可用原理
1.环境简述2.QJM HA简述2.1为什么要做HDFS HA?2.2 HDFS HA的方式2.2 HSFS HA的结构2.3 机器要求3.部署HDFS HA3.1 详细配置3.2 部署HDF ...
随机推荐
- 一种Mysql和Mongodb数据同步到Elasticsearch的实现办法和系统
本文分享自天翼云开发者社区<一种Mysql和Mongodb数据同步到Elasticsearch的实现办法和系统>,作者:l****n 核心流程如下: 核心逻辑说明: MySQL Binlo ...
- Spring AI + DeepSeek:提升业务流程的智能推理利器
今天,我们将深入探讨如何利用DeepSeek来真正解决我们当前面临的一些问题.具体来说,今天我们仍然会将DeepSeek接入到Spring AI中进行利用.需要注意的是,虽然DeepSeek目前主要作 ...
- Kyuubi支持Iceberg配置
一.简述 Kyuubi调用Spark来查询iceberg表,修改Spark配置信息即可. 二.服务配置 1.上传jar包到Kyuubi server节点 可以选择emr spark组件后,按照配置组( ...
- linux监控系统行为
1.验证电脑是否存在,一般都有 which script /usr/bin/script 2.配置profile文件,在末尾添加如下内容: vim /etc/profile ============= ...
- JUC并发—1.Java集合包底层源码剖析
大纲 1.为什么要对JDK源码剖析 2.ArrayList源码一:基本原理以及优缺点 3.ArrayList源码二:核心方法的原理 4.ArrayList源码三:数组扩容以及元素拷贝 5.Linked ...
- C#进行word模板占位符替换的几种工具
word模板中,包含一些需要替换的项,比如{{姓名}} {{年龄}}或者$姓名$ $年龄$,从数据库获取信息后,对模板进行替换操作生成新的word文档. 简单对以下四种工具做了一下测试: 1.NPOI ...
- RFID基础——ISO15693标签存储结构及访问控制命令说明
ISO15693协议标准的高频RFID无源IC卡,具有高度防冲突与长距离运作等优点,主要应用与资产管理.图书馆管理.供应链管理.医疗领域.开发基于 ISO15693 的应用首先需要了解标签的存储结构以 ...
- Flink学习(九) Sink到Kafka
package com.wyh.streamingApi.sink import java.util.Properties import org.apache.flink.api.common.ser ...
- 「二」nginx下载与安装
1.下载地址(开源版):https://nginx.org/en/download.html wget https://nginx.org/download/nginx-1.14.2.tar.gz 2 ...
- 经由同个文件多次压缩的文件MD5都不一样问题排查,感慨AI的强大!
开心一刻 今天点了个外卖:牛肉炒饭 外卖到了后,发现并没有牛肉,我找商家理论 我:老板,这个牛肉炒饭的配菜是哪些? 商家:青菜 豆芽 火腿 鸡蛋 葱花 我:没有牛肉? 商家:亲,没有的哦 我:我点的牛 ...