Hadoop系列(二):Hadoop单节点部署
环境:CentOS 7
JDK: 1.7.0_80
hadoop:2.8.5
hadoop(192.168.56.101)
配置基础环境
1. 测试环境可以直接关闭selinux和防火墙
2. 主机添加hosts记录
# vim /etc/hosts
192.168.56.101 hadoop
3. 创建hadoop用户
# useradd hadoop
# passwd hadoop
4. 添加免密登陆(如果不添加免密登陆,后面启动服务时候会提示输入密码)
# su - hadoop
$ ssh-keygen -t rsa
$ ssh-copy-id hadoop@localhost
安装JDK
1. 卸载系统自带的openjdk
yum remove *openjdk*
2. 安装JDK
JDK下载地址:https://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html
# tar zxvf jdk1.7.0_80.tgz -C /usr/local/
# vim /etc/profile
#添加
export JAVA_HOME=/usr/local/jdk1.7.0_80
export JAVA_BIN=$JAVA_HOME/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
# source /etc/profile
# java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
部署Hadoop
在一台机器上配置,之后拷贝到其他节点主机
1. 安装Hadoop
# su - hadooop
$ wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
$ tar zxvf hadoop-2.8.5.tar.gz
$ mv hadoop-2.8.5 hadoop #添加环境变量(每个节点都配置)
$ vim ~/.bash_profile
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export PATH $ source ~/.bash_profile
2. 配置Hadoop
配置文件在`hadoop/etc/hadoop`目录下
$ cd hadoop/etc/hadoop #1. 修改core-site.xml
$ vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
</property>
</configuration> # 2. 修改hdfs-site.xml
$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9001</value>
</property>
</configuration> # 3. 修改mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml
$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> # 4. 修改hadoop-env.sh(如果不声明JAVA_HOME,在启动时会出现找不到JAVA_HOME 错误)
$ vim hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/usr/local/jdk1.7.0_80 # 5. 修改yarn-env.sh(如果不声明JAVA_HOME,在启动时会出现找不到JAVA_HOME 错误)
$ vim yarn-env.sh
在脚本前面添加
export JAVA_HOME=/usr/local/jdk1.7.0_80
3. 格式化HDFS
$ hadoop namenode -format
4. 启动服务
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
查看启动情况
$ jps
16321 NameNode
16658 ResourceManager
16511 SecondaryNameNode
16927 Jps
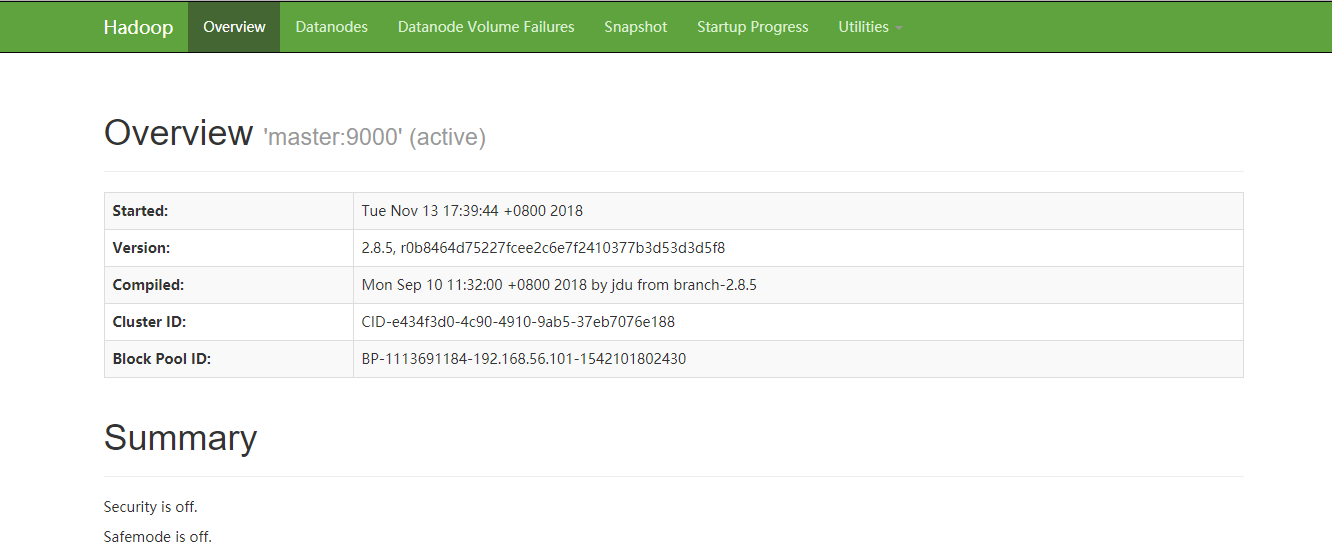
浏览器中访问http://192.168.56.101:50070 查看管理页面
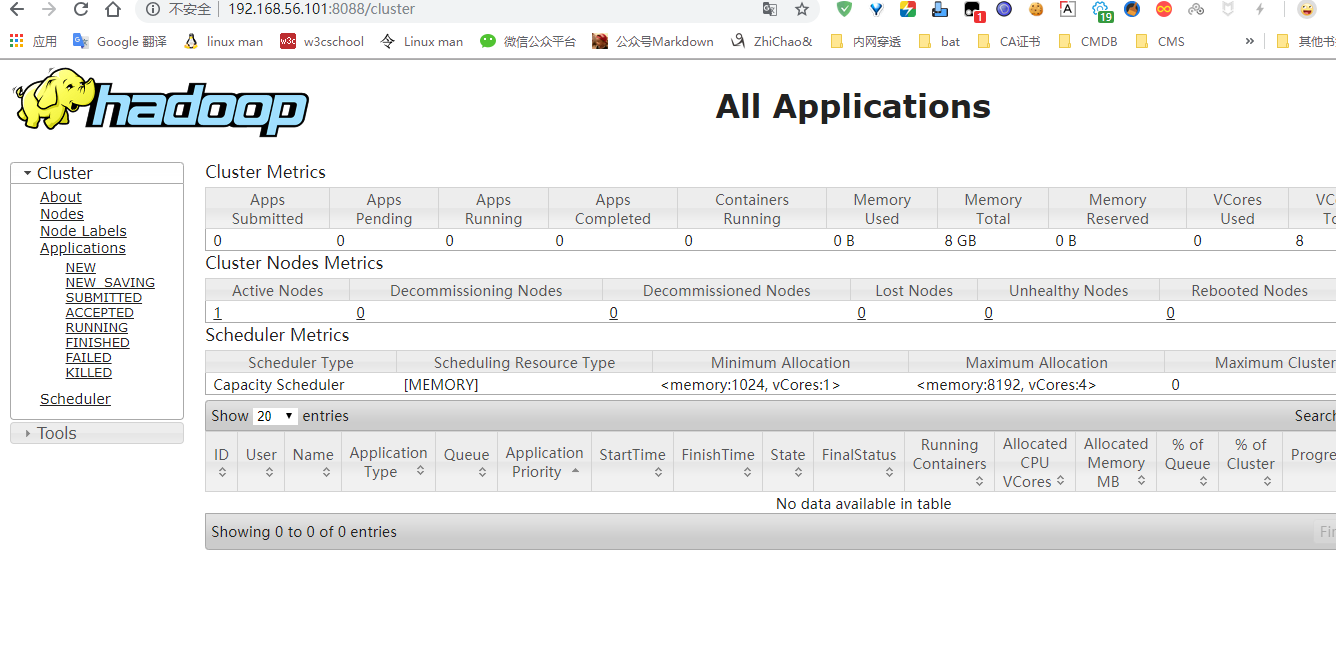
浏览器中访问http://192.168.56.101:8088
测试hadoop使用

Hadoop系列(二):Hadoop单节点部署的更多相关文章
- Hadoop 2.6.4单节点集群配置
1.安装配置步骤 # wget http://download.oracle.com/otn-pub/java/jdk/8u91-b14/jdk-8u91-linux-x64.rpm # rpm -i ...
- Ubuntu下用devstack单节点部署Openstack
一.实验环境 本实验是在Vmware Workstation下创建的单台Ubuntu服务器版系统中,利用devstack部署的Openstack Pike版. 宿主机:win10 1803 8G内存 ...
- .netcore consul实现服务注册与发现-单节点部署
原文:.netcore consul实现服务注册与发现-单节点部署 一.Consul的基础介绍 Consul是HashiCorp公司推出的开源工具,用于实现分布式系统的服务发现与配置.与其他分 ...
- HyperLedger Fabric 1.4 单机单节点部署(10.2)
单机单节点指在一台电脑上部署一个排序(Orderer)服务.一个组织(Org1),一个节点(Peer,属于Org1),然后运行官方案例中的example02智能合约例子,实现转财交易和查询功能.单机单 ...
- Kubernetes 二进制部署(一)单节点部署(Master 与 Node 同一机器)
0. 前言 最近受“新冠肺炎”疫情影响,在家等着,入职暂时延后,在家里办公和学习 尝试通过源码编译二进制的方式在单一节点(Master 与 Node 部署在同一个机器上)上部署一个 k8s 环境,整理 ...
- 单节点部署Hadoop教程
搭建HDFS 增加主机名 我这里仅仅增加了master主机名 [root@10 /xinghl/hadoop/bin]$ cat /etc/hosts 127.0.0.1 localhost 10.0 ...
- Hadoop HDFS 单节点部署方案
初学者,再次记录一下. 确保Java 和 Hadoop已安装完毕(每个人的不一定一样,但肯定都有数据,仅供参考) [root@jans hadoop-2.9.0]# pwd /usr/local/ha ...
- Hadoop入门--HDFS(单节点)配置和部署 (一)
一 配置SSH 下载ssh服务端和客户端 sudo apt-get install openssh-server openssh-client 验证是否安装成功 ssh username@192.16 ...
- Hadoop 2.2.0单节点的伪分布集成环境搭建
Hadoop版本发展历史 第一代Hadoop被称为Hadoop 1.0 1)0.20.x 2)0.21.x 3)0.22.x 第二代Hadoop被称为Hadoop 2.0(HDFS Federatio ...
随机推荐
- 玩转Spring Cloud之配置中心(config server &config client)
本文内容导航: 一.搭建配置服务中心(config server) 1.1.git方式 1.2.svn方式 1.3.本地文件方式 1.4.解决配置中包含中文内容返回乱码问题 二.搭建配置消费客户端( ...
- Asp.Net Core在CentOS部署与注意
部署具体步骤参考:将ASP.NET Core应用程序部署至生产环境中(CentOS7) 1.wwwroot是放静态文件的,Startup的配置里面要app.UseStaticFiles(); 2.在不 ...
- MySQL分组查询与连接查询
一,分组查询 使用ORDER BY子句将表中的数据分成若干组(还是按行显示) 语法: SELECT 字段名[,聚集函数] FROM 表名 [WHERE子句] GROUP BY 要分组的字段名 [ORD ...
- WEB前端需要了解的XML相关基础知识
什么是 XML? XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输数据,而非显示数据 XML 标签没 ...
- 在虚拟机中搭建qduoj(一)——准备工作
为缩减篇幅,已略去ubuntu镜像下载.虚拟机(VirtualBox.VMware)安装等操作,若有疑问请搜索相关教程. 1.虚拟机系统安装 本教程使用Ubuntu16.04 server版本(des ...
- HTML之body标签中的相关标签补充
一 列表标签 列表标签分为三种. 1.无序列表<ul>,无序列表中的每一项是<li> 英文单词解释如下: a.ul:unordered list,“无序列表”的意思. b.li ...
- 解决Geoserver请求跨域的几种思路
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景描述 跨域问题是浏览器同源安全制引起的特别常见的问题.不同前端语 ...
- python在sqlite动态创建表源码
代码之余,将开发过程中经常用的代码片段备份一下,如下的代码是关于python在sqlite动态创建表的代码,应该能对各位有所用. import sqlite3 as db conn = db.conn ...
- scrollview嵌套下拉控件嵌套recyclerview(不动第三方原基础自定义)
相信会碰到很多类似的需求,一个列表控件,然后控件上方的一个头部需要自定义,这样就不好有时候也不能加在列表控件的头部了,那必须得嵌套一层scrollview了,没毛病,那么一般的列表控件都是有上拉下拉的 ...
- Python笔记-IO编程
IO在计算机中是指input和output(数据输入与输出),涉及到数据交换(磁盘.网络)的地方就需要IO接口. 输入流input stream是指数据从外面(磁盘.网络服务器)流入内存:输出流out ...