Python爬取知乎上搞笑视频,一顿爆笑送给大家
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:Huangwei AI
来源:Python与机器学习之路
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
最近小编经常刷知乎上的一个问题“你见过哪些是「以为是个王者,结果是个青铜」的视频或图片?”。从这个问题我们就已经可以看出来里面的幽默成分了,点进去看果然是笑到停不下来。于是,我想一个个点进去看,还不如把这些视频都下载下来,享受一顿爆笑。
获取url
我们使用Google浏览器的“开发者工具”获取网页的url,然后用requests.get函数获得json文件,再使用json.loads函数转换成Python对象:
url = "https://www.zhihu.com/api/v4/questions/312311412/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=20&offset="+str(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)
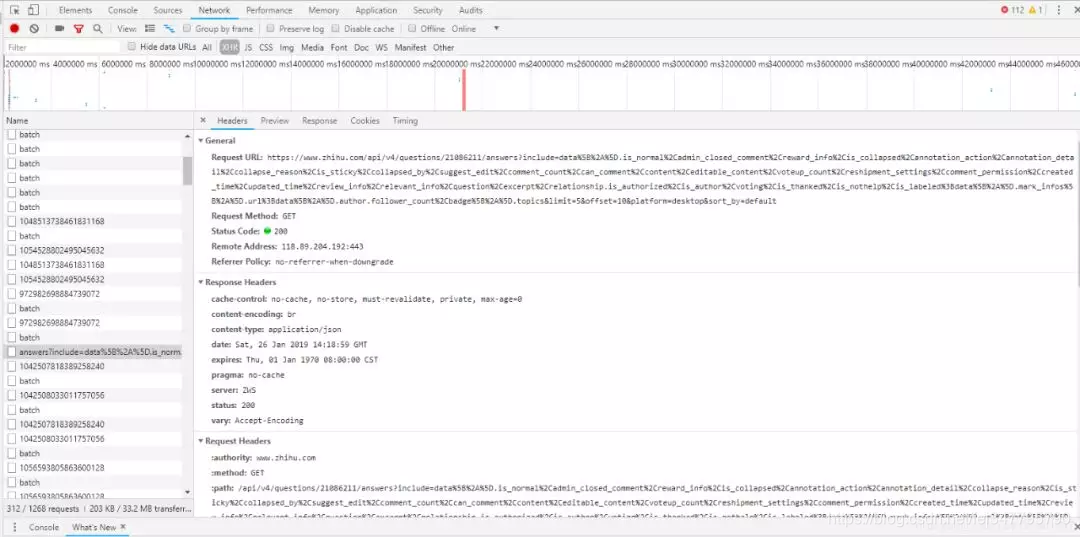
获取content
我们使用谷歌浏览器的一个开发者工具JSONview,可以看到打开的url中有一个content,这里面就是我们要找的回答内容,视频url也在里面。将返回的json转化成python对象后,获取其中content里面的内容。也就是说,我们获得了每一个回答的内容,包括了视频的地址。
for k in range(20):#每条dicurl里可以解析出20条content数据
name = dicurl["data"][k]["author"]["name"]
ID = dicurl["data"][k]["id"]
question = dicurl["data"][k]["question"]["title"]
content = dicurl["data"][k]["content"]
data_lens = re.findall(r'data-lens-id="(.*?)"',content)
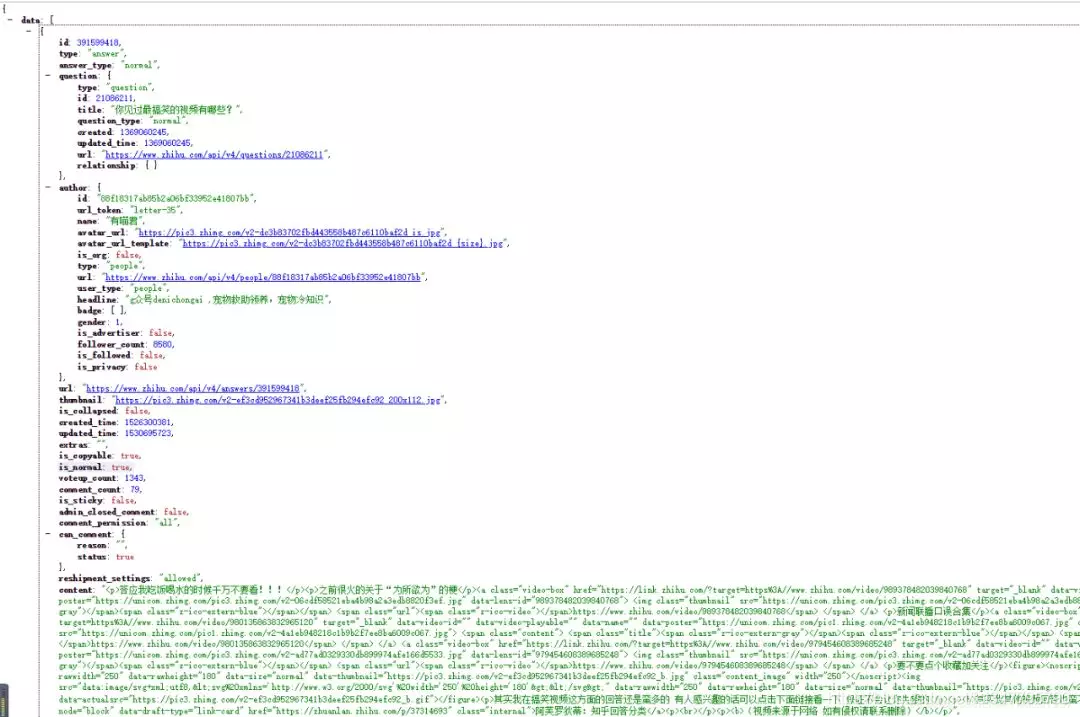
获得视频地址
打开获取的content,找到href后面的url,打开看一下打开后视频正是我们要的内容,但是发现url不是我们获取的真实地址。仔细观察后发现,这个url发生了跳转。想要知道如何跳转来的,我们再次F12,打开开发者工具,发现请求了一个新的URL。观察发现,其实后面一串数字就是之前的data-lens-id。
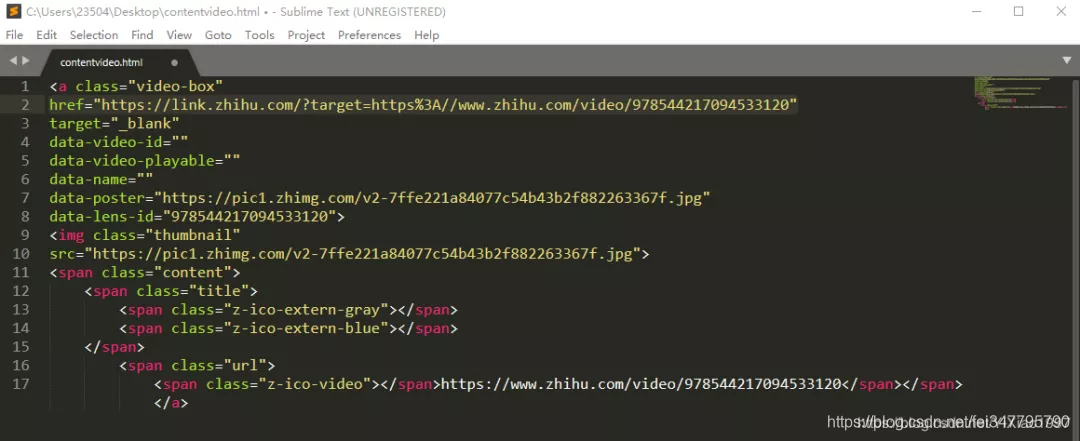
对这个地址进行构造:
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
R = requests.get(videoUrl,headers = kv)
Dicurl = json.loads(R.text)
playurl = Dicurl["playlist"]["LD"]["play_url"]
#print(playurl)#跳转后的视频url
videoread = request.urlopen(playurl).read()
完成之后,我们就可以下载视频了。
完整版代码:
from urllib import request
from bs4 import BeautifulSoup
import requests
import re
import json
import math
def getVideo():
m = 0#计数字串个数
num = 0#回答者个数
path = u'/home/zhihuvideo1'
#path = u'/home/zhihuimage'
kv = {'user-agent':'Mozillar/5.0'}
for i in range(math.ceil(900/20)):
try:
url = "https://www.zhihu.com/api/v4/questions/312311412/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=20&offset="+str(i*20)+"&platform=desktop&sort_by=default"
r = requests.get(url,headers = kv)
dicurl = json.loads(r.text)
for k in range(20):#每条dicurl里可以解析出20条content数据
name = dicurl["data"][k]["author"]["name"]
ID = dicurl["data"][k]["id"]
question = dicurl["data"][k]["question"]["title"]
content = dicurl["data"][k]["content"]
data_lens = re.findall(r'data-lens-id="(.*?)"',content)
print("正在处理第" + str(num+1) + "个回答--回答者昵称:" + name + "--回答者ID:" + str(ID) + "--" + "问题:" + question)
num = num + 1 # 每次碰到一个content就增加1,代表回答者人数
for j in range(len(data_lens)):
try:
videoUrl = "https://lens.zhihu.com/api/v4/videos/"+str(data_lens[j])
R = requests.get(videoUrl,headers = kv)
Dicurl = json.loads(R.text)
playurl = Dicurl["playlist"]["LD"]["play_url"]
#print(playurl)#跳转后的视频url
videoread = request.urlopen(playurl).read() fileName = path +"/" + str(m+1) + '.mp4'
print ('===============================================')
print(">>>>>>>>>>>>>>>>>第---" + str(m+1) + "---个视频下载完成<<<<<<<<<<<<<<<<<")
videoname = open(fileName,'wb') videoname.write(videoread)
m = m+1
except:
print("此URL为外站视频,不符合爬取规则")
except:
print("构造第"+str(i+1)+"条json数据失败")
if __name__ == "__main__":
getVideo()
跑这个程序需要注意的是需要按照代码存储视频的路径建立一个文件夹:
结果
经过一段时间爬虫,我们最终获得了七百多条视频:
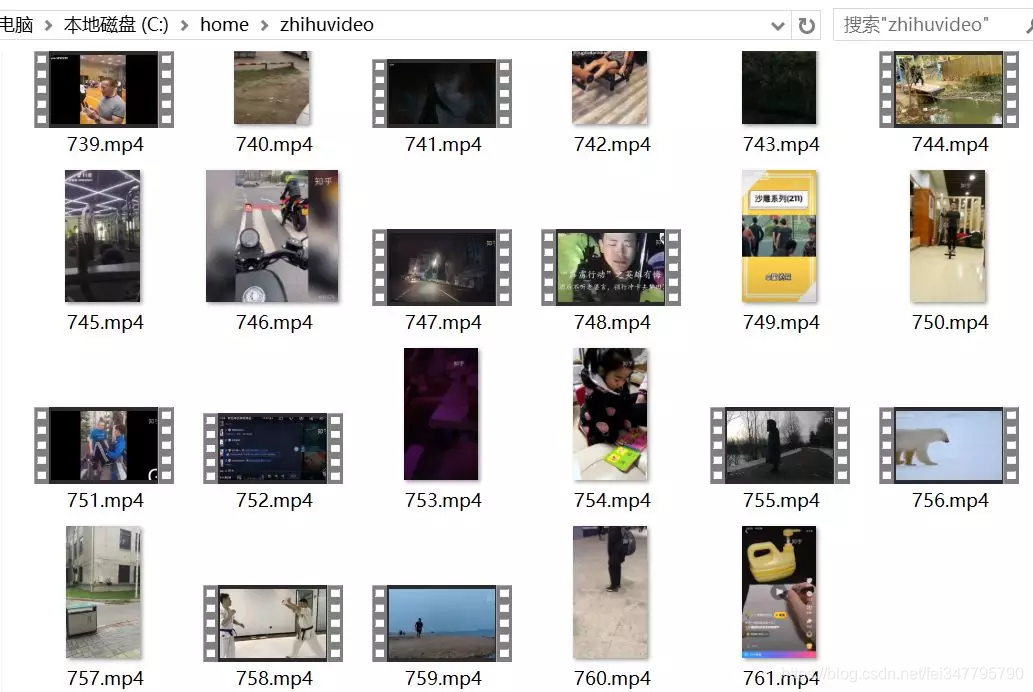
.
Python爬取知乎上搞笑视频,一顿爆笑送给大家的更多相关文章
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- python 爬取知乎图片
先上完整代码 import requests import time import datetime import os import json import uuid from pyquery im ...
- nodejs爬虫笔记(三)---爬取YouTube网站上的视频信息
思路:通过笔记(二)中代理的设置,已经可以对YouTube的信息进行爬取了,这几天想着爬取网站下的视频信息.通过分析YouTube,发现可以从订阅号入手,先选择几个订阅号,然后爬取订阅号里面的视频分类 ...
- 甜咸粽子党大战,Python爬取淘宝上的粽子数据并进行分析
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 爬虫 爬取淘宝数据,本次采用的方法是:Selenium控制Chrome浏览 ...
- Python爬取抖音高颜值小视频
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 有趣的python PS:如有需要Python学习资料的小伙伴可以加 ...
- Python爬取知乎单个问题下的回答
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 努力学习的渣渣哦 PS:如有需要Python学习资料的小伙伴可以加 ...
- python爬取知乎评论
点击评论,出现异步加载的请求 import json import requests from lxml import etree from time import sleep url = " ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- 爬取知乎热榜标题和连接 (python,requests,xpath)
用python爬取知乎的热榜,获取标题和链接. 环境和方法:ubantu16.04.python3.requests.xpath 1.用浏览器打开知乎,并登录 2.获取cookie和User—Agen ...
随机推荐
- Exe4j 打包: this executable was created with an evaluation version of exe4j
异常 this executable was created with an evaluation version of exe4j 异常.png 问题原因 当前打包使用exe4j未授权 解决方法 ...
- Mybatis中返回Map
在Mybatis中,我们通常会像下边这样用: 返回一个结果 User selectOne(User user); <select id="selectOne" paramet ...
- Kubernetes的ConfigMap对象使用
ConfigMap和Secret几乎一样,只是Secret会用base64加密,创建方式也可以彩yaml或者文件方式 下面演示一下通过文件创建configmap 创建配置文件my.yaml name: ...
- Spring Boot 2.X(九):Spring MVC - 拦截器(Interceptor)
拦截器 1.简介 Spring MVC 中的拦截器(Interceptor)类似于 Servlet 开发中的过滤器 Filter,它主要用于拦截用户请求并作相应的处理,它也是 AOP 编程思想的体现, ...
- Winform中自定义添加ZedGraph右键实现设置所有Y轴刻度的上下限
场景 Winforn中实现ZedGraph自定义添加右键菜单项(附源码下载): https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/10 ...
- Android 多选列表对话框 setMultiChoiceItems
private Button button; private final CharSequence items[] = { "北京", "上海", " ...
- Spring Boot 2 + Thymeleaf:服务器端表单验证
表单验证分为前端验证和服务器端验证.服务器端验证方面,Java提供了主要用于数据验证的JSR 303规范,而Hibernate Validator实现了JSR 303规范.项目依赖加入spring-b ...
- Script - 检查当前的undo配置和建议设置 (Doc ID 1579035.1)
Script - Check Current Undo Configuration and Advise Recommended Setup (Doc ID 1579035.1) APPLIES TO ...
- Java学习笔记(6)---正则表达式,方法
1.正则表达式: a.定义: 正则表达式定义了字符串的模式. 正则表达式可以用来搜索.编辑或处理文本. 正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别. 在Java,一个字符串其实就是一 ...
- Linux 和 Windows 查看 CUDA 和 cuDNN 版本
目录 Linux 查看 CUDA 版本 查看 cuDNN 版本 Windows 查看 CUDA 版本 查看 cuDNN 版本 References Linux 查看 CUDA 版本 方法一: nvcc ...