python 爬取网页简单数据---以及详细解释用法
一、准备工作(找到所需网站,获取请求头,并用到请求头)
- 找到所需爬取的网站(这里举拉勾网的一些静态数据的获取)----------- https://www.lagou.com/zhaopin/Python/
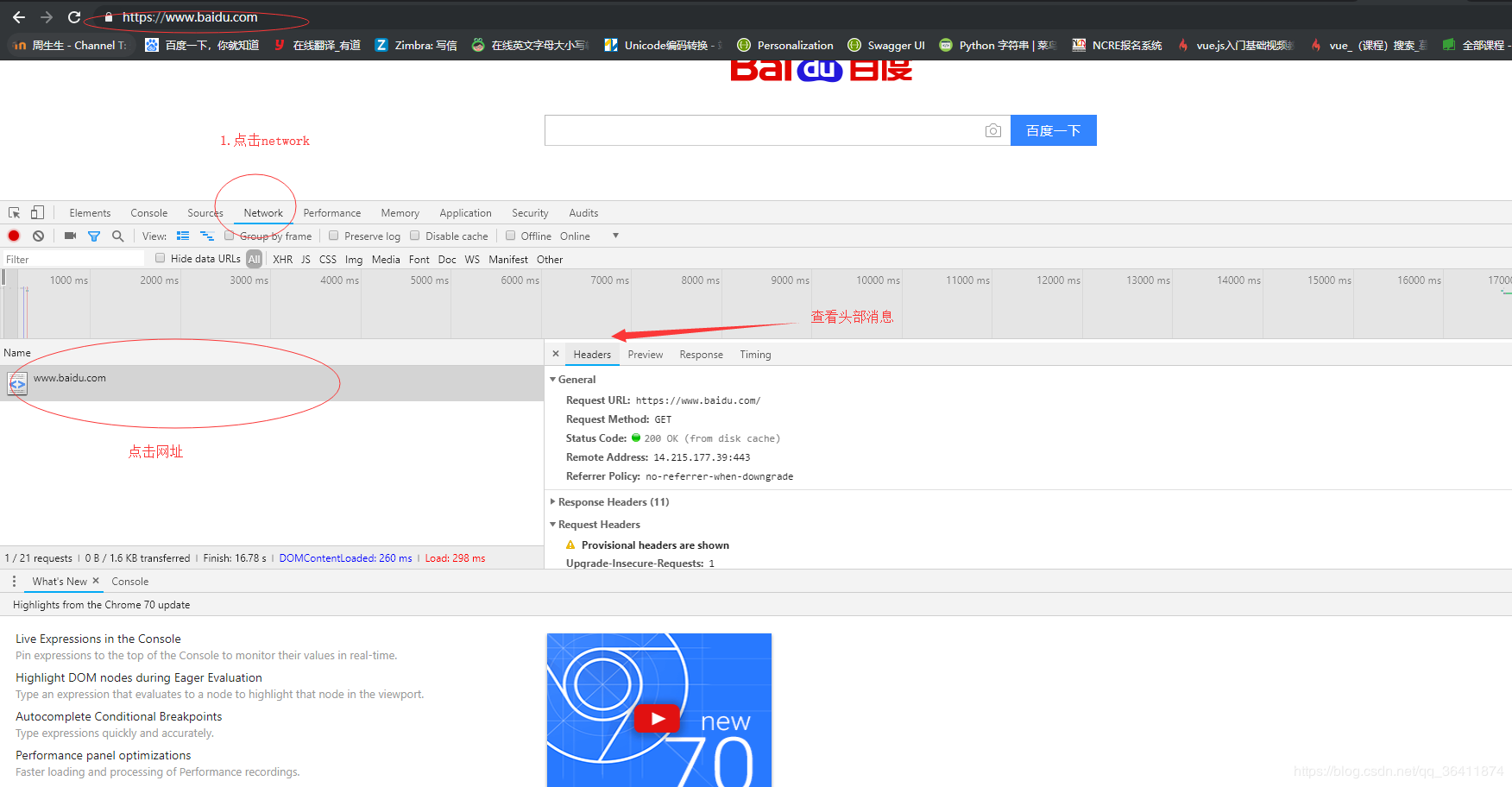
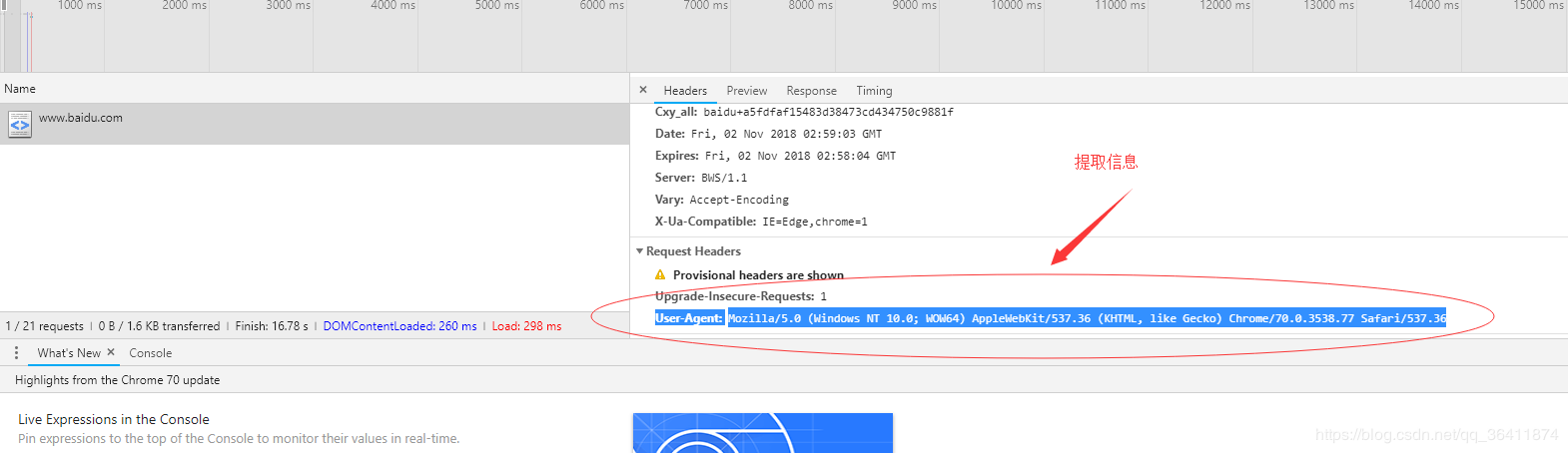
- 请求头的作用:模拟真实用户进入网站浏览数据-----------headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',}
- r=requests.get("https://www.lagou.com/zhaopin/Python/",headers=headers)-------------------这两行就是模拟用户进入网站
- 找到数据所在网页的标签(html网页右键源代码查看即可)

假设这里的15k-25k是我们要的数据,右键查看按箭头查看即可-----例如这里是span标签class=''money''(可以点击下面的控制台查看money是什么属性,有的是id=“money”这样的)------具体得看html代码
- 准备工作完毕
二、代码演示:(开始爬取)
2.1如果爬取的数据乱码,可以加入这三句话,定义输出格式
import io
import sys
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
2.2爬取职位等相关信息(完整代码)
import requests
import re
import itertools
from bs4 import BeautifulSoup
import io
import sys
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',}-------------请求头 r=requests.get("https://www.lagou.com/zhaopin/Python/",headers=headers)---------------请求该网页
r.encoding=r.apparent_encoding
result=r.text------------------------------------------获取网页文档
bs=BeautifulSoup(result,'html.parser')
# soup.find_all(string=re.compile('python')) li1=bs.find_all('h3')-------------------------------------------查找该页面所有h3标签
# len1=len(li1)
# for i in li1:-----------------------------------------------用来测试输出的内容
# print(i.string) li2=bs.find_all('em')
# len2=len(li2)
# for i in li2:--------------------------------------------用来测试输出的内容
# print(i.string) li3=bs.find_all('span',class_="money")
# len3=len(li3)
# for i in li3:
# print(i.string) li4=bs.find_all('div',class_="industry")
# len4=len(li4)
# for i in li4:
# print(i.string)
print("职位:".ljust(15),"地点:".center(15),"薪水:".center(15),"需求:".rjust(15))
print("------------------------------------------------------------------------------------------------")
for li_1,li_2,li_3,li_4 in zip(li1,li2,li3,li4):--------------------------------------------------------------------------四个列表整合(每一行一个元素对应)
print(li_1.string.ljust(15),li_2.string.center(15),li_3.string.center(15),li_4.string.rjust(15).strip())-------------strip()是用来去除字符串左右两边的空格(不然太长不好排版)
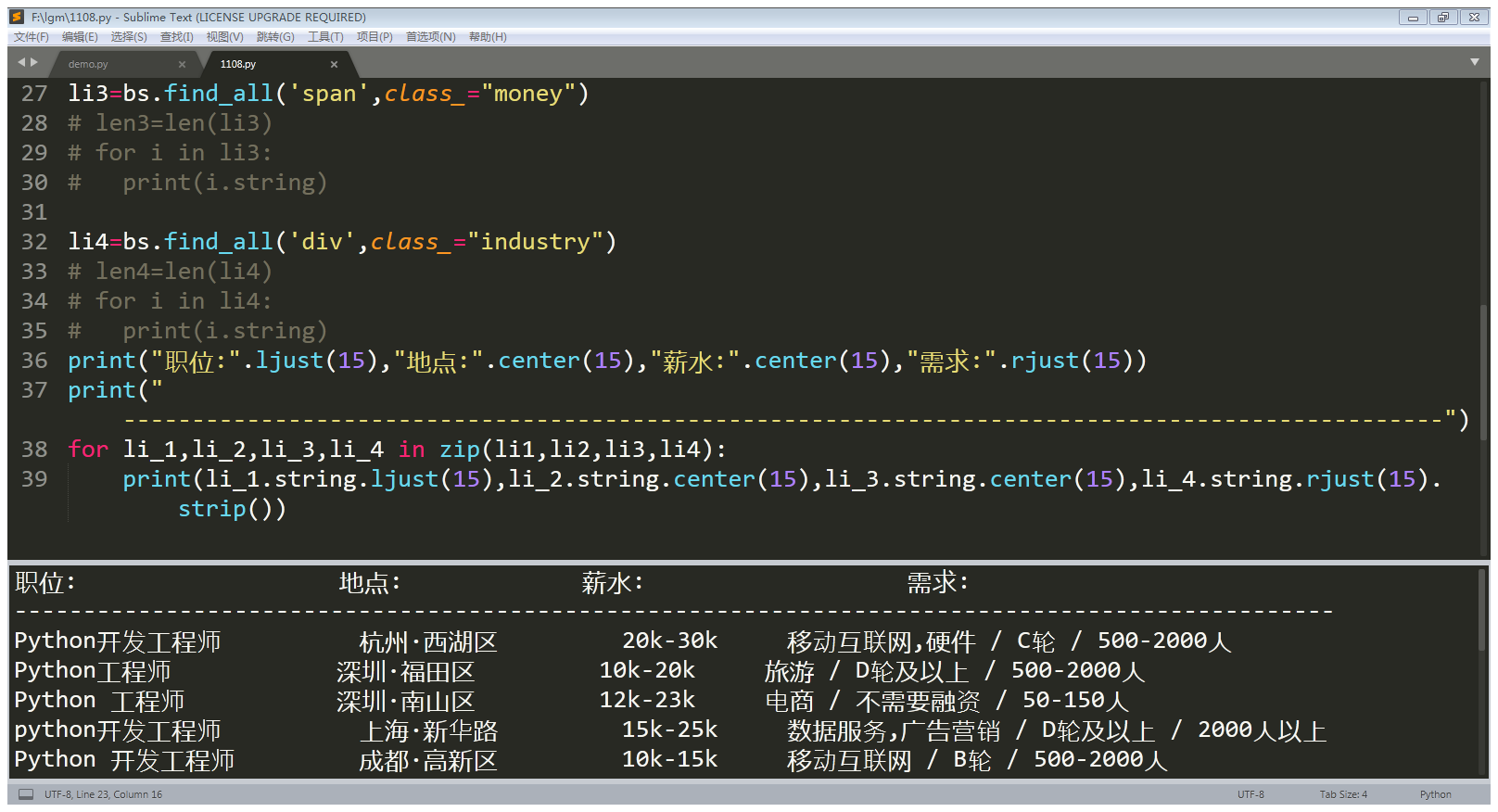
2.3运行结果
三、技术不是很难,但也很有用,不过这里得提醒一下(最好是将网页的html文档存放在本地,一直请求服务器是很不友好的行为哟!)
- 拓展:可以试着将数据存到txt文档或者excl表格中,更直观哟!
python 爬取网页简单数据---以及详细解释用法的更多相关文章
- 如何使用python爬取网页动态数据
我们在使用python爬取网页数据的时候,会遇到页面的数据是通过js脚本动态加载的情况,这时候我们就得模拟接口请求信息,根据接口返回结果来获取我们想要的数据. 以某电影网站为例:我们要获取到电影名称以 ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- Python爬取网页信息
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初 ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- python爬取股票最新数据并用excel绘制树状图
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图 ...
- Python爬取招聘网站数据,给学习、求职一点参考
1.项目背景 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大.因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于 ...
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- 使用 Python 爬取网页数据
1. 使用 urllib.request 获取网页 urllib 是 Python 內建的 HTTP 库, 使用 urllib 可以只需要很简单的步骤就能高效采集数据; 配合 Beautiful 等 ...
- python爬取拉勾网职位数据
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成 ...
随机推荐
- Python sys.setdefaultencoding('utf-8') 后就没输出
为了解决Python的 UnicodeDecodeError: 'ascii' codec can't decode byte ,我们可以加入以下代码. import sys reload(sys) ...
- Mysql高手系列 - 第19篇:mysql游标详解,此技能可用于救火
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能. 这是Mysql系列第19篇. 环境:mysql5.7.25,cmd命令中进行演示. 代码中被[]包含的表示可选,|符 ...
- Joomla 3.0.0 -3.4.6远程代码执行(RCE)漏洞复现
Joomla 3.0.0 -3.4.6远程代码执行(RCE)漏洞复现 一.漏洞描述 Joomla是一套内容管理系统,是使用PHP语言加上MYSQL数据库所开发的软件系统,最新版本为3.9.12,官网: ...
- oracle表空间不足:ORA-01653: unable to extend table
问题背景: oracle表空间不足报错是比较常见的故障,尤其是没有对剩余表空间做定期巡检的系统: 报错代码如下: oracle表空间不足错误代码:ORA-01653: unable to extend ...
- Spring Boot (十四): 响应式编程以及 Spring Boot Webflux 快速入门
1. 什么是响应式编程 在计算机中,响应式编程或反应式编程(英语:Reactive programming)是一种面向数据流和变化传播的编程范式.这意味着可以在编程语言中很方便地表达静态或动态的数据流 ...
- Bribe the Prisoners SPOJ - GCJ1C09C
Problem In a kingdom there are prison cells (numbered 1 to P) built to form a straight line segment. ...
- Springboot2.x + ShardingSphere 实现分库分表
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程. 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用. 在拆分之前 ...
- django-Xadmin后台管理
0919自我总结 django-Xadmin后台管理 一.安装环境 pip install https://codeload.github.com/sshwsfc/xadmin/zip/django2 ...
- Redis 3.0中文版学习(一)
网址:http://wiki.jikexueyuan.com/project/redis-guide/entry-to-master-a.html http://www.yiibai.com/redi ...
- POST PUT 小解
POST 主要是用来提交数据让服务器进行处理的,PUT主要是请求数据的. POST 提交的数据放在HTTP正文里面,而PUTT提交的数据放在url里面.